上海AI实验室开源“书生·万卷”1.0多模态预训练语料
站长网2023-08-15 09:34:210阅
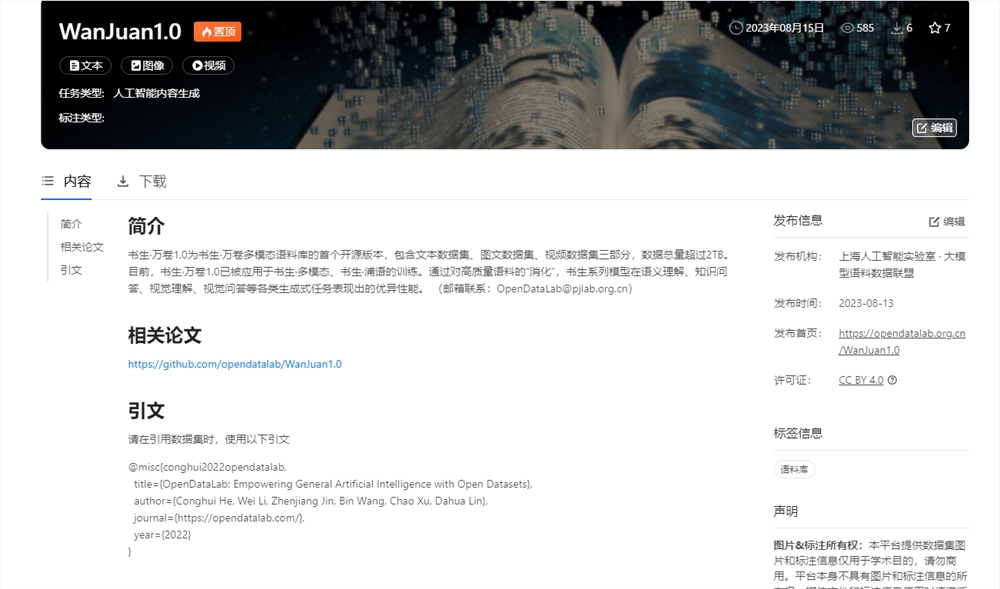
上海 AI 实验室联合语料数据联盟成员共同开源发布了高质量多模态预训练语料 “书生・万卷”1.0。
据悉,这个语料库包含了文本数据集、图文数据集和视频数据集,总量超过2TB。其中包括超过5亿个文本、2200万个图文交错文档和1000个节目影像视频。
这些数据经过细粒度清洗、去重和价值对齐等处理,具备多元融合、精细处理、价值对齐和易用高效的特点。
上海 AI 实验室表示,开源发布 “书生・万卷” 有助于降低大模型技术的门槛,推动大模型的应用和创新。该语料数据联盟旨在通过联合多方机构打造高质量的语料数据,探索形成可持续运行的激励机制,打造国际化、开放型的大模型语料数据生态圈。
地址:https://opendatalab.org.cn/WanJuan1.0
开源地址:https://github.com/opendatalab/WanJuan1.0
0000
评论列表
共(0)条相关推荐
- 0000
- 0000
- 0000
- 0000
- 0000