百度推出通用图像关键信息抽取工具PP-ChatOCR 基于文心大模型打造
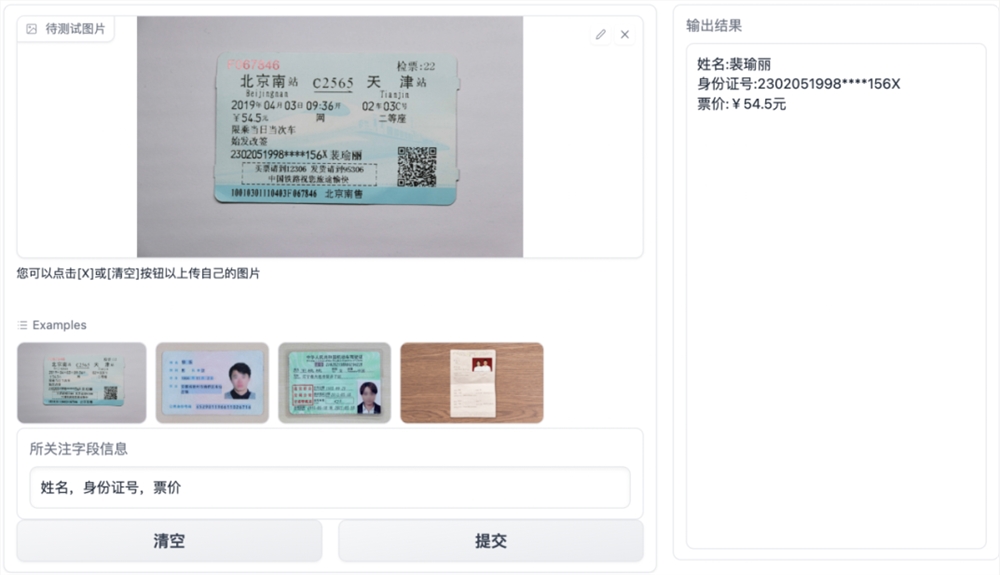
近日,百度飞桨团队宣布推出基于文心大模型的通用图像关键信息抽取工具——PP-ChatOCR。它结合了 OCR 文字识别和大模型技术,可以在多种场景下提取图像中的关键信息。
PP-ChatOCR 的核心思想是利用大模型的泛化能力和规则化处理,将 OCR 识别结果传递给文心大模型进行信息提取。PP-ChatOCR 的技术框架包括 OCR 推理、场景判别、Prompt 构造和后处理等步骤。
百度表示,使用 PP-ChatOCR 可以快速搭建通用的图像关键信息抽取系统,降低开发成本。对于个性化的需求,可以针对业务场景进行优化,包括微调 OCR 模型和调整大模型输出。PP-ChatOCR 已经在多个场景中取得了良好的精度和稳定性。
据悉,PP-ChatOCR 目前正式上线飞桨 AI 套件 PaddleX,开发者可以在 PaddleX 中对 PP-OCRv4做训练微调。同时 PaddleX 还支持 PP-ChatOCR 的高性能部署。
PaddleX 支持10 任务能力,包括图像分类、目标检测、图像分割、3D、OCR 和时序预测等;内置36种飞桨生态特色模型,包括 PP-ChatOCR、PP-OCRv4、RP-DETR、PP-YOLOE、PP-ShiTu、PP-LiteSeg、PP-TS 等。
AI Studio 应用中心体验 PP-ChatOCR:
https://aistudio.baidu.com/aistudio/projectdetail/6488689
飞桨 AI 套件 PaddleX 中的 PP-ChatOCR:
https://aistudio.baidu.com/aistudio/modelsdetail?modelId=332
PaddleOCR GitHub:
https://github.com/PaddlePaddle/PaddleOCR
- 0000
- 0000

 0001
0001
 0000
0000- 0000