清华发布SmartMoE:支持用户一键实现 MoE 模型分布式训练
清华大学计算机系 PACMAN 实验室发布了一种稀疏大模型训练系统 SmartMoE,该系统支持用户一键实现 Mixture-of-Experts(MoE)模型的分布式训练,并通过自动搜索并行策略来提高训练性能。
论文地址:https://www.usenix.org/system/files/atc23-zhai.pdf
项目地址:https://github.com/zms1999/SmartMoE
MoE 是一种模型稀疏化技术,通过将小模型转化为多个稀疏激活的小模型来扩展模型参数量。然而,传统的专家并行技术在训练 MoE 模型时存在性能问题,因为稀疏激活模式导致节点间不规则的 all-to-all 通信增加延迟和计算负载不均。

为了解决这些问题,SmartMoE 系统设计了专家放置策略和自动并行算法。通过对常用并行策略的支持和动态负载均衡,SmartMoE 系统在性能测试中表现出较高的加速比。
该系统的特点包括:
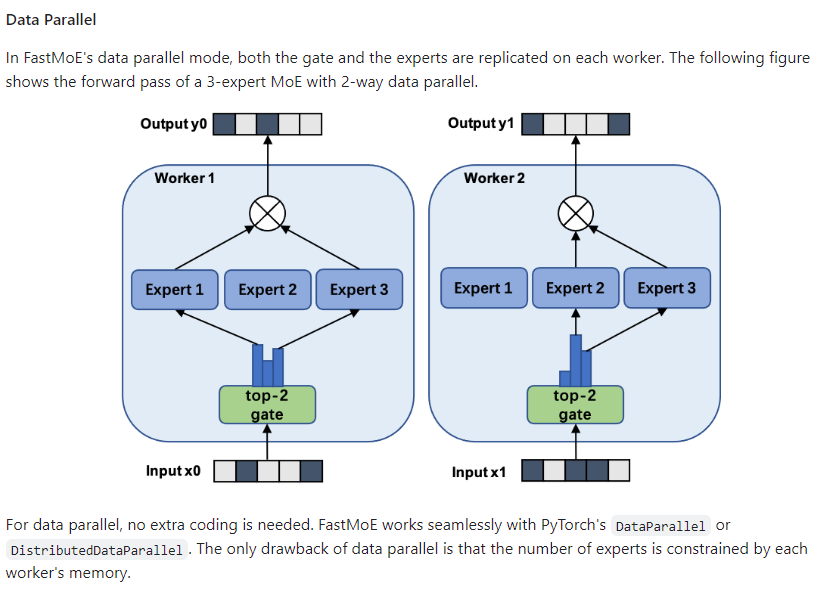
支持常用并行策略:SmartMoE 系统对数据并行、流水线并行、模型并行和专家并行等四种并行策略进行了全面的支持,并允许用户任意组合这些策略。
专家放置策略:为了处理 MoE 模型的动态计算负载,SmartMoE 系统设计了专家放置策略,根据当前负载调整专家的放置顺序,实现节点间的负载均衡。
两阶段自动并行算法:为了提高 MoE 模型复杂混合并行策略的易用性,SmartMoE 系统设计了一套轻量级且有效的两阶段自动并行算法。这个算法将自动并行搜索过程分为训练开始前的搜索和训练过程中的动态调整两个阶段,以减少搜索的开销。
高性能:在性能测试中,SmartMoE 在不同模型结构、集群环境和规模下都表现出优异的性能。相较于之前的 FasterMoE 系统,SmartMoE 能够实现高达1.88倍的加速比。
总之,SmartMoE 是一种可以一键实现高性能 MoE 稀疏大模型分布式训练的系统,具有支持多种并行策略、专家放置策略和两阶段自动并行算法的特点。通过这些特点,SmartMoE 系统能够提高 MoE 模型的易用性和训练性能,助力 MoE 大模型的发展。
- 0000
- 0001
 0000
0000- 0000
- 0000

