3D-LLM:让AI聊天机器人可以解读三维世界
研究人员推出了一款名为3D-LLM的新方法,可以将对3D 环境的理解融入到大型语言模型中。这意味着聊天机器人将能够理解和处理3D 空间的概念,从而更好地在三维世界中导航和操作。
大型语言模型和多模态语言模型可以处理语音和2D 图像,比如ChatGPT、GPT-4和Flamingo。然而,这些模型缺乏对3D 环境和物理空间的真正理解。研究人员现在提出了一种称为3D LLM 的新方法来解决这个问题。
3D LLM 旨在通过使用点云等3D 数据作为输入,为 AI 提供3D 空间的概念。通过这种方式,多模态语言模型应该理解空间关系、物理和可供性等概念,而这些概念仅靠2D 图像很难掌握。3D LLM可以使人工智能助理能够在3D 世界中更好地导航、规划和行动,例如在机器人技术和实体人工智能领域。
为了训练模型,团队需要收集足够数量的3D 和自然语言数据对 - 与网络上的图像文本对相比,此类数据集是有限的。因此,团队开发了ChatGPT的提示技术来生成不同的3D描述和对话。
结果是包含超过300,000个3D 文本示例的数据集,涵盖3D 标记、回答视觉问题、任务分解和导航等任务。例如,ChatGPT 被要求通过询问有关从不同角度可见的物体的问题来描述3D 卧室场景。

然后,该团队开发了3D 特征提取器,将3D 数据转换为与预训练的2D 视觉语言模型(例如 BLIP-2和 Flamingo)兼容的格式。
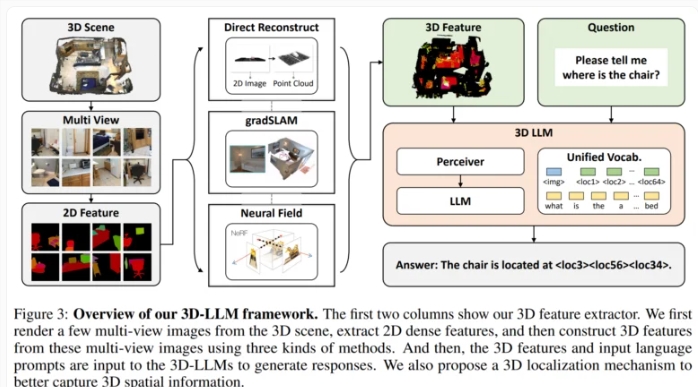
此外,研究人员使用3D 定位机制,允许模型通过将文本描述与3D 坐标相关联来捕获空间信息。这也促进了使用 BLIP-2等模型来有效地训练3D LLM 来理解3D 场景。
实验结果显示,3D 语言模型可以生成对3D 场景的自然语言描述,进行3D 感知对话,并将复杂任务分解为3D 动作。这表明,通过结合空间推理能力,人工智能有潜力开发出更接近人类的3D 环境感知。
研究人员计划将这种模型扩展到其他数据模式,如声音,并训练它们执行其他任务。这将进一步提高 AI 助手在多模态环境中的能力。最终的目标是将这些进步应用到可以与3D 环境智能交互的具体 AI 助手中。这意味着未来可能会有更智能的机器人和具体人工智能应用程序。
- 0000
- 0001
- 0000
- 0001
- 0001