一场 AI 引发的开源革命迫在眉睫?Hugging Face 更改文本推理软件许可证,不再“开源”
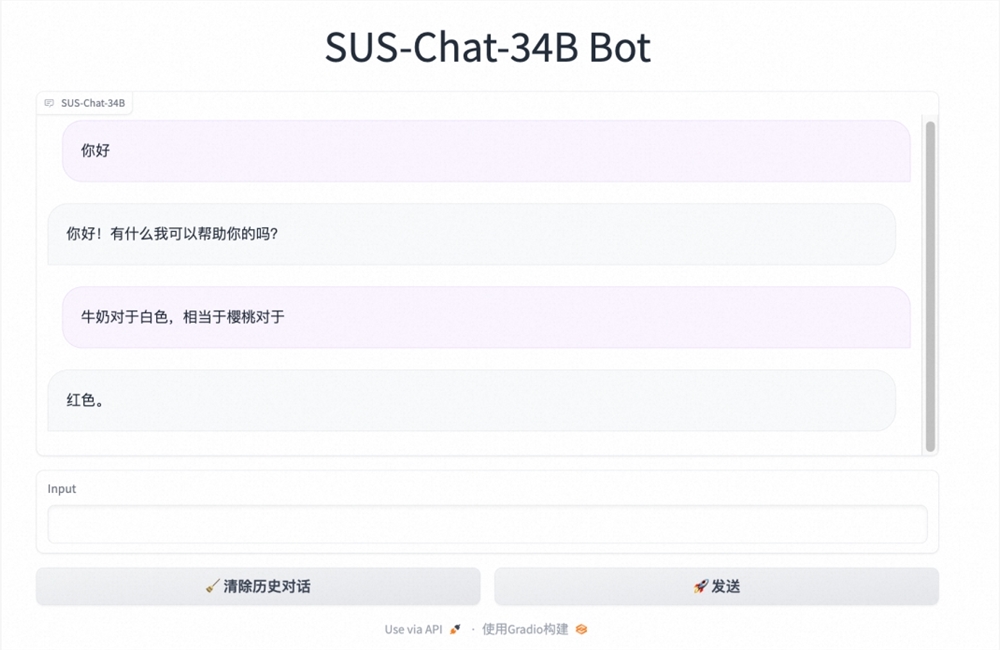
Text-Generation-Inference(又称 TGI)是 Hugging Face 今年早些时候启动的一个项目,作为支持 Hugging Face Inference API 和后来的 Hugging Chat 上的 LLM 推理的内部工具,旨在支持大型语言模型的优化推理。自推出后,该项目迅速流行,并被 Open-Assistant 和 nat.dev 等其他开源项目采用。

近日,Hugging Face 宣布,在最新推出的 TGI v1.0版本中,其开源许可证将从 Apache2.0改为 HFOIL1.0。HFOIL 代表 Hugging Face Optimized Inference License,是 HuggingFace 专为优化推理解决方案而设计的协议。Hugging Face 表示,HFOIL 并不是真正的开源许可证,虽然源代码仍然可以访问,但其增加了一项限制:要销售基于 TGI 构建的托管或托管服务,需要单独的协议。
为什么要更换许可证?
据悉,TGI 已成为 Hugging Face 商业产品(如推理端点)及其商业合作伙伴(如 Amazon SageMaker、Azure 机器学习和 IBM watsonx )的重要组成部分。而 Hugging Face 此次更换许可证也与其商业策略紧密相关。
根据 Hugging Face 的说法,TGI 最初是一个为其内部产品提供动力的项目,该公司将其视为商业解决方案的关键组成部分。“TGI 并不是一个社区驱动的项目,而是一个可供社区广泛访问的生产解决方案。我们希望继续公开建设 TGI,并将继续欢迎大家做出贡献。但与 Transformers 和 Diffusers 等社区驱动的项目不同,TGI 专注于生产环境中的性能和稳健性,目标是构建商业产品。”
据悉,TGI 此前所有版本仍然在 Apache2.0下获得许可,最后一个 Apache2.0版本是版本0.9.4。
Hugging Face 表示,源代码许可的这一变化对免费使用 TGI 的绝大多数社区用户没有影响,其推理端点客户及商业合作伙伴的客户也不会受到影响。但它将限制非合作云服务提供商在未请求许可的情况下提供 TGI v1.0 服务。
如果是 v1.0之前的 TGI 现有用户,当前的版本仍然是 Apache2.0,可以不受限制地进行商业使用。
如果用户将 TGI 用于个人用途或研究目的,则不受 HFOIL1.0的限制。
如果用户将 TGI 作为内部公司项目的一部分用于商业目的(不作为托管或托管服务出售给第三方),则也不受 HFOIL1.0限制。
如果将 TGI 集成到出售给客户的托管或托管服务中,则考虑升级到 v1.0及更高版本的许可证。
“开源是一个误称,它应该是来源自由。”有网友评价道。也有网友表示,“开源不应过度限制我使用工具的方式。如果无法再将其嵌入到我销售的产品中,则它是可用的源代码,但不是开源的。”
有人提出,资产阶级认为他们可以从公地获取创新来建立帝国并压迫群众,至少应该为这种特权付出代价。对此,有开发者表示,“FSF (自由软件基金会)对此的回答是使用 AGPLv3,它在网络访问上限制了 Copyleft。”
AGPL v3协议规定,除非获得商业授权,否则无论以何种方式修改或者使用代码,都需要开源。开发者“kmeisthax”表示,“如果你唯一的目标就是阻止大型企业接触您的代码,那么当然可以使用这个许可证。但你也可以使用奇怪时髦的后现代许可证来做到这一点,这些许可证从技术上讲不授予任何权利,很容易被用来限制 Copyleft 巨魔。但如果你只是想要公平且易于遵守的规则,那么该许可证就有问题。”“AGPLv3仅对使用解释性语言进行 Web 开发有意义,这样可以轻松列出网站的代码。”
“kmeisthax”进一步表示,“如果你想更严格,还有 OpenWatcom 许可证,它会在您使用软件时触发 Copylef,所以没有私人分叉。实际上,这不像 AGPLv3那样令人头疼,你不需要允许通过网络下载源代码,您只需在某处发布您的修改即可。FSF 拒绝碰它,因为他们认为私人分叉是一项人权。”
“kmeisthax”认为,阻止“资产阶级”从公地掠夺所有创新的问题在于,这样做会使软件脱离公地,这比 AGPLv3、SSPL 或 OpenWatcom 更糟。任何试图这样做的人都不是想保护公地,而是想加入资产阶级。因为不允许你为他人托管软件,这是专有世界的语言。专有软件许可之所以如此有利可图,主要是因为使用限制——它允许你查看每个用户的钱包,并从中提取最大金额的资金。
延绵近半世纪的开源许可证
要为 AI 改变?
自由软件与开源许可证自上世纪七、八十年代起曾经历演变以适应代码编程的需求。如今,它需要再次转型来应对 AI 模型带来的新一波冲击。
比如,ChatGPT 现在仍然使用的是开源代码。特别是,分别由 Google 和 Facebook 开发的 TensorFlow 和 PyTorch 推动了 ChatGPT。这些框架为构建和训练深度学习模型提供了必要的工具和库。没有它们,就没有 ChatGPT。ChatGPT 另一个重要的开源部分就是 Hugging Face 的 Transformer,这是用于构建最先进的机器学习模型的领先开源库。
得益于开源,但 OpenAI 却没有将 ChatGPT 开源。“ OpenAI 本来是作为一家开源(这就是为什么我将其命名为‘Open’AI)、非盈利公司而创建的,目的是作为谷歌的制衡,但现在它实际上已经成为一家闭源、利润最大化的公司。由微软控制。根本不是我想要的。”马斯克曾批评道。
开源模型的流行也印证了大家对于 AI 模型开放的期盼。但实际上,基于版权法处理软件代码的自由软件和开源许可证,并不适合支撑 AI 开源软件之下的大语言模型(LLM)神经网络与数据集。而另一方面,相当规模的编程数据集长期基于自由软件与开源代码,因此必须采取措施、顺应转变。有鉴于此,开放源码倡议(OSI)执行董事 Stefano Maffulli 等开源和 AI 领导者,努力寻求一种对双方均有积极意义的新方式,希望将 AI 与开源许可证结合起来。
去年 J. Doe 等人(匿名)起诉了 GitHub。原告在美国加州北区法院控诉微软、OpenAI 和 GitHub 通过其基于 AI 的商业系统 OpenAI Codex 与 GitHub Copilot 窃取了开发者的开源代码。原告方认为,“涉案”代码几乎就是直接从公共 GitHub 代码仓库中抓取的原始代码副本,且未获得开源许可承认。
目前案件仍在审理中,原告方修改了诉讼方向,包括指控被告违反《数字千年版权法》、违反合同(违反开源许可证)、存在不公平得利和不正当竞争行为,以及违反合同(违反 GitHub 政策中约定的销售许可条款)。
这类麻烦困扰的不只有微软。耶鲁大学法学院网络安全讲师、耶鲁大学隐私实验室创始人 Sean O’Brien 认为,“很快就会出现与专利流氓类似的完整子产业,但这一次将主要围绕 AI 生成的成果。随着越来越多作者使用 AI 驱动工具在专有许可之下发布代码,这将建立起新的反馈循环。软件生态系统将被专有代码所污染,而这些代码将成为‘有心之人’的索赔载体。”
德国研究员兼政治家 Felix Reda 等人则声称,一切 AI 生成的代码都属于公共产出。SmartEdgeLaw Group 创始成员之一、美国律师 Richard Santalesa 认为,这里其实存在合同法与版权法的双重纠纷。Santalesa 认为,出售 AI 生成代码的企业将“与所有其他知识产权一样,将其交付的材料(包括 AI 生成代码)视为自有财产。”而公共领域代码和开源代码的处理方式并不相同。
更重要的是,这还涉及数据集如何获取许可这个宏观问题。虽然很多开源许可证之下都涵盖大量“开放”数据集,但并不足以彻底解决目前的尖锐冲突。
如今的我们正站在类似的十字路口上。TensorFlow、PyTorch 和 Hugging Face Hub 等 AI 程序在其开源许可证下运行良好,但其他新 AI 成果却不知该如何走出自己的道路。数据集、模型、权重等并不完全适合传统的版权模型。Maffulli 认为,技术社区应当设计出一些更符合自身目标的新事物,而不能总是依赖于对已有规则的“魔改”。
Maffulli 解释道,为软件设计的开源许可证可能并不适合 AI 工件。例如,虽然 MIT 许可证强调的广泛自由度在模型层面比较适用,但 Apache 或 GPl 等更复杂的许可证却很可能引发问题。Maffulli 还强调,将开源原则应用于医疗保健等敏感领域同样面临着挑战。在这些领域,关于数据访问的法规已经成为行业发展道路上的障碍。简而言之,法律规定医疗数据不得开源。
与此同时,大多数大语言模型的数据集都属于黑盒子,我们根本不知道其中到底有些什么。因此,正如电子前沿基金会(EFF)所言,我们最终陷入了“垃圾进、宝贝出”的茫然境地。为此,EFF 建议必须开放训练数据。
通过立法保护开源?
中国、欧盟、美国和英国等多国政府一直在努力开展 AI 监管。而 Hugging Face、GitHub、EleutherAI、Creative Commons、LAION 和 Open Future 等六家开源 AI 利益相关方组成的联盟正向欧盟立法者请愿,呼吁在设定欧盟 AI 法案(将成为欧盟 AI 法案的最终版本,也将是全球第一部全面的人工智能法)时保护开源创新。
在日前发布的政策文件《在欧盟 AI 法案中支持开源与开放科学》(Supporting Open Source and Open Science in the EU AI Act)当中,开源 AI 领导者们提出了“如何确保 AI 法案适用于开源”的相关建议,原则要求“确保开放式 AI 开发实践不会面临在结构上不切实际的义务,或者其他有碍技术发展的义务。”
根据这份文件,有利于闭源及专有 AI 开发(例如 OpenAI、Anthropic 和谷歌等顶尖 AI 厂商开发的模型)的“过于广泛的义务”,“可能会对开放 AI 生态系统造成不利影响。”
Hugging Face 机器学习与社会事务负责人 Hacine Jernite 在采访中表示,虽然政策文件的内容相当丰富,但该联盟想要强调的核心永远是鼓励创新。“我们认为,人们应该能从各类基础模型、组件间自由选择,并根据需求随意组合和匹配,这一点非常重要。”
此外,该联盟还希望强调开源 AI 的重要性、甚至是必要性,认为监管不应阻碍开源 AI 的创新道路。Jernite 解释道,“开放本身并不能保证负责任的开发态度。但是,开放性和透明度却是负责任治理的必要前提。因此,开放性不是要躲避责任,而责任也不应该妨碍开放发展。”
GitHub 高级政策经理 Peter Cihon 指出,随着欧盟理事会及之后的欧盟议会制定出 AI 法案草案,立法者们开始审视整个价值链、思考如何减轻其中由 AI 发展早期引发的风险。
Cihon 在采访中指出,“通过这一步骤,我们正加倍努力,确保法案不会在潜移默化中偏向于大企业、或者其他资源充足的 AI 参与者,而是将这份权利同样交付给出于业余爱好的开源开发者、非营利性组织和学生。总而言之,立法者一直过于关注特定的价值链和特定的模型,大多是 API 模型——而这种关注在开源背景下并不真正适用。”
 0001
0001- 0001
- 0000
- 0000
- 0000