知乎大模型「知海图AI」上线!产品官宣即内测,为4亿用户摘取「热榜摘要」
又一家国内企业大模型产品发布。
不是别的,而是已拥有4亿用户的最大中文问答社区知乎。
而且官宣即内测——
不光有首个大语言模型「知海图AI」,首款产品也将应用于热榜。
情理之中,意料之外。
一方面,知乎拥有天然的大模型优势,有场景有应用,最关键的还有天然大规模、高质量的中文数据池。NewBing也将其视作中文数据源之一,一时间股价暴涨近50%。
这种优势放眼国内并不多见,此次产品发布也算是千呼万唤始出来。
但另一方面,在众多尤其科研工作者认知中,知乎作为知识问答分享平台,每一次技术革命爆发都在这里围观与见证。
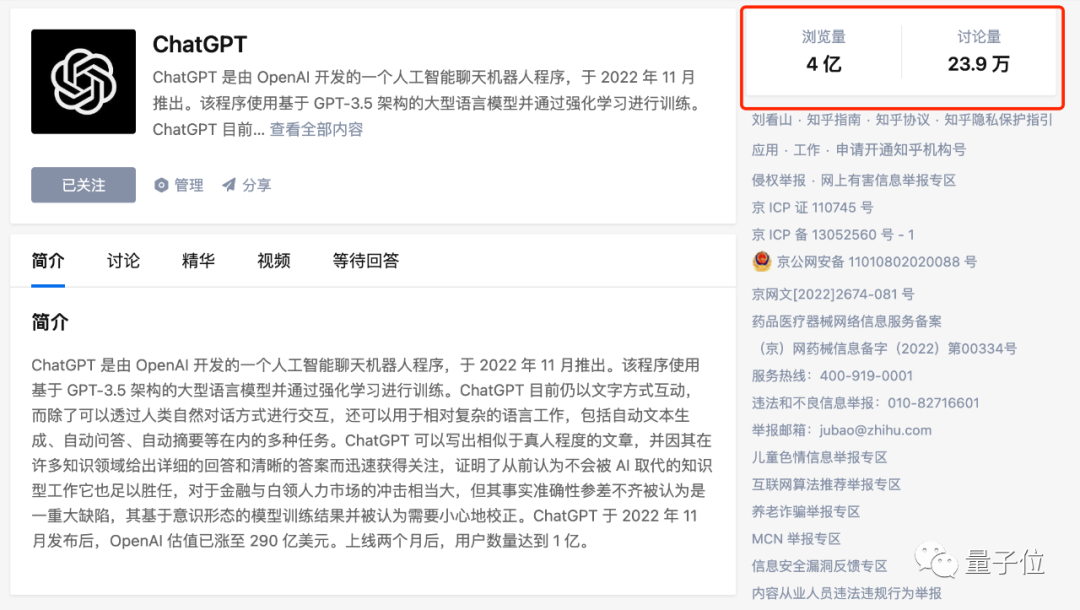
正如ChatGPT相关话题就已打破当年AlphaGo讨论热度,浏览量达4亿,讨论量近24万。
至于知乎背后相关AI技术和布局,并不被大多数人所知。
现在,知乎主动分享了一切。
而且随着产品的发布,知乎在大语言模型上的布局也首次浮出水面。
知乎大模型产品官宣即内测
在发布会现场,知乎也释出了「热榜摘要」的产品形态最新Demo,让正在等待内测的朋友们先来一睹为快~
可以看到的是,“看山”小助手会出现在热榜的问题下方。
然后它会抓取那些优质问答的重要观点,经过AI算法整理、聚合、润色后,将回答梗概展现给用户。
这样一来,看热门问题的同时就能获取关键信息,效率直接拉满。
而这背后的大语言模型CPM-Bee,来自当下饱受市场关注的清华系大模型创业公司面壁智能。
据知乎联合创始人、CTO李大海介绍,CPM-Bee是目前视野范围内表现最好的中文大语言模型。
面壁智能联合创始人兼CEO曾国洋,也给出了官方内测表现:
内容聚合场景下,在41个问题中,有28个问题表现持平。与GPT-4相比基本持平。
作为国内最早开展相关研究和探索的公司之一,创始团队来自清华计算机系自然语言处理与社会人文计算实验室(THUNLP),刘知远、孙茂松、刘洋多位教授分别是他们的联合创始人和顾问。因此在大模型学研转化、开发落地等方面都有丰富的经验。
产学研转化这块,团队曾最早提出由知识指导的预训练模型ERNIE,围绕模型预训练、提升学习、参数高效微调等这些大模型热门议题,他们也在国际顶会上发表了数十篇论文。
他们也曾开发开源多个大模型,比如:国内首个中文大模型CPM-1、高效易用大模型CPM-2、可控持续大模型CPM-3……
除此之外,法律、生物医学等垂直领域也开发了专有专用大模型。成立伊始,就与法律、汽车、家电、传媒等行业龙头客户达成合作,以及完成近千万种子轮融资。
而就在最近,面壁智能刚获由知乎领投、智谱AI跟投的天使轮融资。据双方消息,此次投资合作旨在实现双方优势资源的价值共创,共同探索大规模语言模型的上层应用。
由此看来,知乎大模型布局也浮出水面:投资大模型公司, 共同打造大模型应用。
据透露,与面壁智能之间属于是深度融合的关系,每天都要见一面的那种。
接下来,在CPM-Bee基础上,随着更多的反馈和迭代,新模型有了更强的逻辑推理能力和更快的训练和推理速度之后,将逐步应用到知乎更多场景中去。
比如创作、讨论场、信息获取等。
事实上这种路径也并不陌生,正如微软与OpenAI。微软的产品矩阵完美贴合ChatGPT的落地场景,应用的同时又能反哺迭代大模型的能力。于是乎,正是两者技术与应用的深度融合,才有了震撼全球的搜索引擎、生产力和生产生活的变革,让企业、个人都能享受到AIGC带来的潜力和可能。
随之而来的问题是——
为什么走这样一条路?
当前国内大模型的发展,已经远不能用火热来形容。这个被认为是比以往任何变革都大十倍的机会,任何企业和机构都不愿意轻易错过,这几周接踵而至的新进展就可见一斑。
不可否认的是,知乎此时布局大模型,选择了一条最适合自己的路——
用知乎CEO周源的话说,是AI时代新生产力的开发者、以及新场景的创建者。
个中缘由得从国内大模型发展开始拆解。
首份《中国AIGC产业全景报告》显示,国内大模型发展大致可以分为三种路径:基础设施层、模型层以及应用层。
其中,模型层成为当前发展的关键卡口,在一定程度上限制了上下层级(基础设施层、应用层)的发展。
至于模型层发展好与不好,归根结底,主要来自算力和数据这两方面:算力是支撑背后大语言模型训练的硬件基础,而数据则是直接影响模型能力强弱甚至生成质量的关键。
尤其是中文数据这块,一方面本质原因,中文相对英文复杂,技术难度高;另一方面,国外英文数据集更丰富,且质量较高。但国内的中文语料并不完善,必要时还需要各家公司来清洗,耗费人力财力。
而这恰好与知乎区别于其他平台的独特优势有关。
我们都知道,模型效果的好坏,既取决于数据的数量,也取决于质量。这一点知乎似乎能做到两者兼备。
在数量方面,2022第三季度财报显示,知乎社区内的内容量已累计超5.79亿条。2022年年度财报显示,问答量已累计到了5.06亿条,覆盖超1000个垂直领域。
尤其在一些专业问题上,更是表现明显。
知乎战略副总裁、社区业务负责人张宁透露这样一组关键数据:
站内从事科研学习和工作的人群总数高达544万人。仅科研互联网领域,就日均图文生产量两万多篇。
在数学、物理、天文、人工智能等多个领域的回答、文章和视频数都超过了100万篇。
而除了数量之外,数据的质量也是尤为关键。
在ChatGPT发布之初,经常会出现一些离谱、错误的答案。「一本正经地胡说八道」是ChatGPT留给大家的初印象。
这背后其实正是与训练数据的质量有关,数据集中掺杂了诸多鱼龙混杂的内容。
而在知乎,诸多专业人士的探讨、问答机制的筛选构成了内容数据的高质量,甚至有的知乎内容已经直接成册出书。
前段时间,NewBing刚出炉,诸多网友发现一些回答来源正是来自于知乎。

周源这样拆分AI时代的生产力要素,主要分为三层:应用场景、专有数据以及基础模型。基于问答的讨论场,是天然的应用场景。这当中不断产生的内容、关系和知识图谱,则是独一无二专有数据。
而以GPT为代表的基础模型层在快速发展,再结合知乎的应用场景和专有数据,可推动大模型快速的应用落地。与此同时知乎的专业场景,还能反哺大模型技术迭代。
事实上,李大海也透露,知乎也正在与各种类型的公司合作,利用自身独特优势,助推国内大模型的发展。
除了应时之势的考量,这背后也是回归本质顺其自然的选择。
在知乎发现大会上,周源再次谈及知乎社区一直以来「获得感」的内容价值观——
让每个人更好的分享知识、经验与见解,找到自己的解答。
他认为,AI终将服务于人,赋能于人,是人类能力的扩增。
于是具体到知乎这一场景下,人机共创就可以帮助创作者更好地发挥创造力、提高内容创作的效率和质量,从而让更多用户得到帮助、开阔眼界。
大模型浪潮下,诸多应用场景被提及。知乎也作为新场景的创建者躬身入局,探索更多价值。
回顾以往每一次的技术变革更迭,国内百万从业者们通过问答、话题、圆桌、想法、专栏、直播等方式在这里学习与探讨、回应和激辩。
因此从某种程度上来说,知乎作为关键媒介,在国内前沿科技发展进程中起到了不容忽视的作用。
尤其在这场全球ChatGPT风暴里,体会尤为明显,相关话题浏览量达4亿,讨论量超23.9万。
吴恩达老师在这里周更博客,呼吁大家理性看待这个浪潮;被王慧文收购、正处风口浪尖的一流科技创始人袁进辉在知乎中寻找着答案……
诸多ChatGPT衍生产品在这里首发诞生:北大团队推出的ChatExcel、首个公开对标ChatGPT开源项目ChatRWKV 、以及首个国内ChatGPT检测器……背后的开发者们也现身回应,亲自解答网友的疑惑。

一群科研人员、创业者、从业者在这里汇集联结,打破时间与空间的壁垒,第一时间探寻前沿动向,进而去推动国内前沿科技的发展。
只是现在及未来,知乎将利用自己积累的优势,以更显性的方式为中国大模型的发展贡献力量。
—完—


 0000
0000- 0000
- 0001
- 0000
- 0000