OpenAI 的嵌入 API太慢了吗?探索其他嵌入模型和服务的优势
这篇文章讨论了机器学习模型的延迟对聊天应用和代理的用户体验的影响,重点关注了生成语言模型(LLM)的提示生成过程中的语义搜索任务。文章比较了两种嵌入API 服务(OpenAI 和 Google)和几种开源嵌入模型(sentence-transformers)在嵌入速度和准确度方面的表现,发现 OpenAI 的嵌入 API 服务的延迟明显高于 Google 的新嵌入 API 服务,而本地运行的开源嵌入模型则是最快的。文章建议开发者根据自己的需求和数据选择合适的嵌入模型,并提供了一些使用 Langchain 和 HuggingFace 集成嵌入模型的示例代码。
原文链接:https://www.getzep.com/text-embedding-latency-a-semi-scientific-look/

在讨论机器学习模型性能时,通常指的是模型在特定任务上的表现。对于数据科学家和机器学习工程师来说,这包括准确率、损失等度量。然而,随着聊天机器人和智能代理等基于文本生成的 AI 应用成为我们日常生活的一部分,模型延迟成为另一个显著影响用户体验的性能指标,即模型生成结果所需的时间。如果生成过程较慢,将会影响聊天用户的体验。
OpenAI 的 GPT-3.5-Turbo 模型显著缩短了流式响应的首字节响应时间。然而,构建发送给 GPT-3.5-Turbo 模型的提示通常是一个冗长且缓慢的过程,可能需要多次调用其他模型,以及第三方或内部服务,以生成被 GPT-3.5-Turbo 用来生成响应的情境学习内容。
虽然我们通常在创建提示之前就将文件嵌入,但搜索词的嵌入必须在执行搜索时实时完成。因此,嵌入的速度成为生成 GPT-3.5-Turbo 结果的关键。
为什么向量数据库和嵌入模型是 AI 技术的关键
最常见的提示生成任务之一是使用向量数据库从文档集合中检索相关信息。向量数据库存储了一个被称为嵌入的文档的数学表示,并使用近似最近邻等技术比较文档之间,或者与搜索词的相似度。在机器学习中,这个任务被称为语义搜索。
嵌入是由专门设计用于执行此任务的语言模型生成的。有许多不同的嵌入模型,每个模型都有独特的性能特征:准确性、速度、存储和内存使用等。它们也可能是多语言的,或者针对特定的自然语言进行训练。有些甚至针对特定的商业或科学领域进行训练。
虽然文件通常在创建提示之前就被嵌入,但是搜索词嵌入必须在执行搜索时即时创建。这使得嵌入的速度成为生成 LLM 结果的关键路径。
对嵌入模型延迟的半科学调查
正如我们上文所讨论的,缓慢的文本生成影响用户体验,而生成文本的关键任务之一就是使用语义搜索查找相关内容。虽然我们应该考虑嵌入模型的成本、内存使用和实施的便利性,但这次调查仅关注嵌入的速度,以及在有的情况下,对语义相似性搜索任务的MTEB 基准性能。
我们测试了两个嵌入 API 服务和几个由sentence-transformers包支持的开源嵌入模型。我们选取的开源模型代表了在 MTEB 基准测试中得分高,且在 CPU 上表现良好的模型族。还有许多其他模型,你应该根据你的使用场景进行实验,以基准作为指导,而非铁律。
模型部署类型MTEB 检索分数OpenAI text-embedding-ada-002API 服务49.25Google Vertex AI textembedding-gecko@001API 服务未知 -2023年5月推出sentence-transformers/gtr-t5-xl本地 CPU 执行47.96sentence-transformers/all-MiniLM-L12-v2本地 CPU 执行42.69sentence-transformers/all-MiniLM-L6-v2本地 CPU 执行41.95
API 测试在 GCP 和 AWS 上进行,这符合了当今许多应用的场景。本地模型在几个云实例和我的 MacBook Pro M1(配备16GB RAM)上进行了测试。详细信息请见下文。
结果
摘要:Google 的新嵌入 API 比 OpenAI 的快得多,而本地 CPU 上的开源模型最快。Google 的模型尚无检索基准,但 OpenAI 的模型在 MTEB 上得分最高。如果延迟是你的关注点,你可以考虑 Google 或开源模型。
OpenAI 的text-embedding-ada-002模型是许多开发者的首选。由于应用程序常常使用 OpenAI 的模型,因此开发者使用同样的 API 来嵌入文档是合理的。OpenAI 最近也大幅降低了这个 API 的价格。
事实证明,无论是从 AWS 还是 GCP 测量,OpenAI 嵌入 API 的延迟显著高于 Google 新的textembedding-gecko@001模型(仅从 GCP 测量)。
OpenAI 的性能波动较大——许多人都经历过在一些时候 OpenAI 的 API 扩展性差的情况。使用 Azure OpenAI Service 运行在 Microsoft Azure 中的应用,模型的延迟可能会更低。
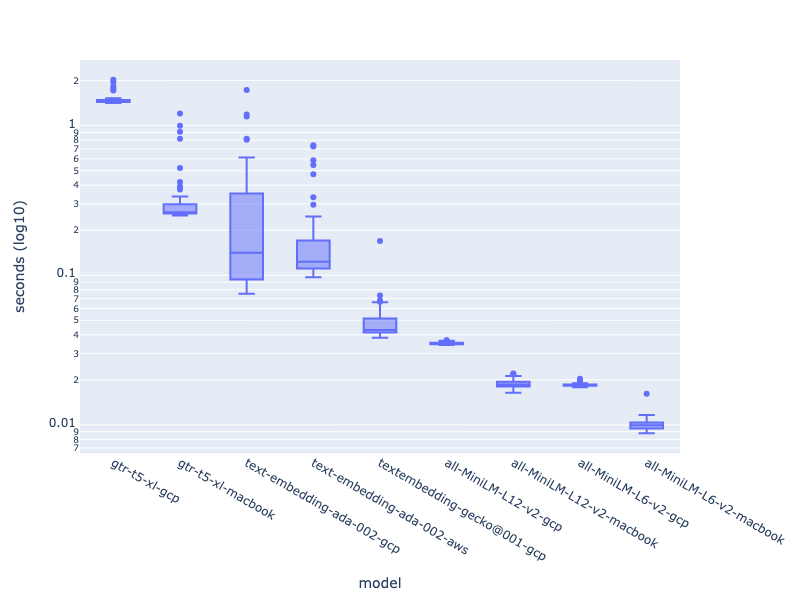
模型延迟(秒,log10)
毫不意外,运行在本地 CPU 上的开源嵌入模型在性能上超越了 Google 和 OpenAI 的 API 服务。网络传输是慢的。但令人惊讶的是 Google 的模型与本地开源模型相比表现出色。我只从 GCP 测量,因此 API 肯定有更低的网络延迟。
延迟通常在第95百分位处进行测量,DevOps 和 SRE 称之为 p95。以下是 p95模型结果(非对数刻度)。OpenAI API 的 p95响应从 GCP 需要近一分钟,从 AWS 需要近600毫秒。
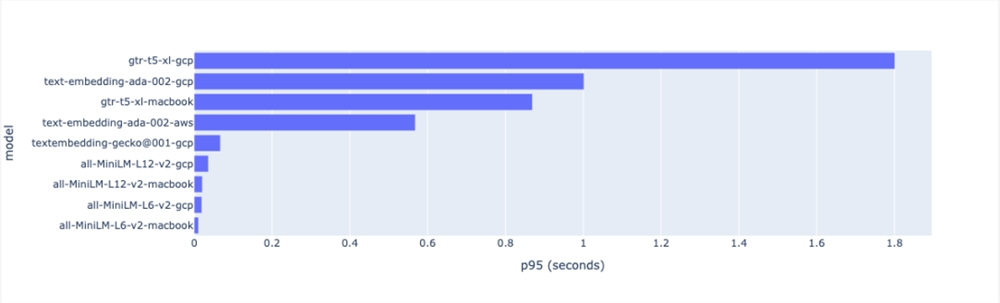
模型延迟 p95(秒)
在这次调查中,虽然开源模型gtr-t5-xl的 MTEB 得分与 OpenAI 的产品最接近,但其表现却远不如所有其他模型。有可能在大批量嵌入的情况下,如果使用 GPU,性能会显著提高(详见下文)。
all-MiniLM系列的开源模型速度非常快(且作为较小的模型,其内存效率非常高)。考虑到他们的速度和相对易于部署的特性(见此Langchain 示例),评估他们对于你特定使用场景的性能表现是值得的。
嵌入模型性能的效果可能因人而异
sentence-transformers团队已经创建了大量不同的模型,并且有充分的理由。每个模型都具有不同组合的性能特性,并且用于不同的用途。口语,句子长度,向量宽度,词汇量和其他因素都会影响模型的性能。有些模型可能对某个领域的表现比其他模型更好。在选择模型时,使用 MTEB 和其他基准作为指导是值得的,但一定要用自己的数据进行实验。
为什么要用 CPU 进行句子嵌入?
在测试开源模型时,我们专注于 CPU 的性能,而非 GPU。CPU 的部署成本低,易于扩展。虽然嵌入模型,像许多深度学习模型一样,在处理大数据集时在 GPU 上表现最好,但我们这里的主要关注点是模型对单个短句子的表现。在这种情况下,使用 GPU 通常比使用 CPU 更慢,因为将数据传输到 GPU 的代价比将同样的数据从内存移动到 CPU 的代价更高。
用 Langchain 使用 SentenceTransformer 模型
即使你没有使用 GPU,使用 SentenceTransformer 嵌入模型在 Langchain 中也相对简单,易于实现。Langchain 自带 HuggingFace 集成,允许在 HuggingFace 托管的任何嵌入模型作为 Langchain 的Embedding。
注意:你需要确保已安装了sentence_transformers。
fromlangchain.embeddingsimportHuggingFaceEmbeddings,SentenceTransformerEmbeddings
# 使用我们上面评估的最轻量级模型embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
text = "Iceland is wonderful to visit"
embedded_docs = embeddings.embed_documents([text])
阅读 Langchain 的 [索引和 VectorStores 文档,了解如何在你的链或代理代码中使用上述内容。
测试方法
我们对每个模型的嵌入速度进行了50次迭代的抽样测试。嵌入的文本相对较短,旨在代表 LLM-based 应用在构建提示时对向量数据库进行搜索的类型。
texts=["Visarequirementsdependonyournationality.CitizensoftheSchengenArea,theUS,Canada,andseveralothercountriescanvisitIcelandforupto90dayswithoutavisa."]
测试句子
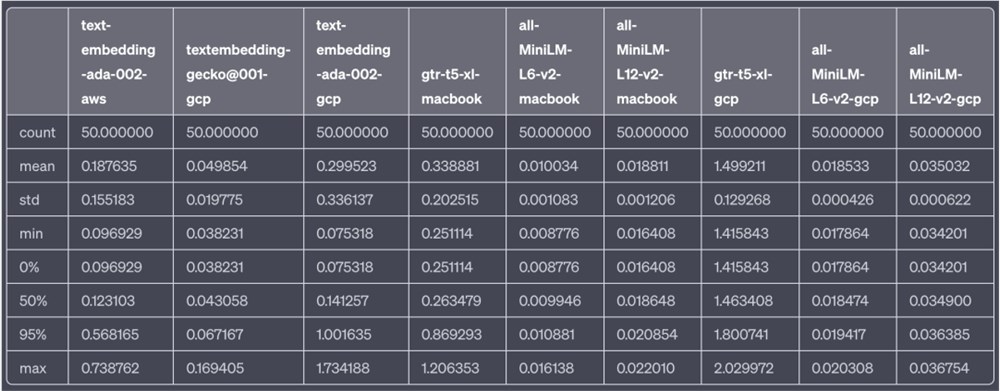
模型延迟数据表
测试在以下基础设施上/从以下基础设施运行:
GCP:位于 us-central1的 n1-standard-4(4vCPU,15GB RAM)实例
AWS:位于 us-west-2的 ml.t3.large(2vcpu 8GiB)实例
我的 MacBook Pro14" M1,拥有16GB 的 RAM
在所有实验中,pytorch只使用 CPU。
使用的软件包括:
JupyterLab
sentence-transformers2.2.2
pytorch2.0.1
Python3.10和3.11
你认为 OpenAI 是目前最好的选择吗?为什么?欢迎发表你的看法和理由。
参考链接
首字节响应时间:https://en.wikipedia.org/wiki/Time_to_first_byte?ref=getzep.com
索相关信息:https://blog.langchain.dev/retrieval/?ref=getzep.com
近似最近邻:https://en.wikipedia.org/wiki/Nearest_neighbor_search?ref=getzep.com
语义搜索:https://www.sbert.net/examples/applications/semantic-search/README.html?ref=getzep.com
许多不同的嵌入模型:https://huggingface.co/spaces/mteb/leaderboard?ref=getzep.com
MTEB 基准性能:https://huggingface.co/spaces/mteb/leaderboard?ref=getzep.com
sentence-transformers:https://www.sbert.net/?ref=getzep.com
以基准作为指导,而非铁律:https://www.getzep.com/text-embedding-latency-a-semi-scientific-look/#your-mileage-may-vary-with-embedding-model-performance
大幅降低了:https://openai.com/blog/function-calling-and-other-api-updates?ref=getzep.com
Azure OpenAI Service:https://azure.microsoft.com/en-us/products/cognitive-services/openai-service?ref=getzep.com
Langchain 示例:https://www.getzep.com/text-embedding-latency-a-semi-scientific-look/#using-sentencetransformer-models-with-langchain
大量不同的模型:https://huggingface.co/sentence-transformers?ref=getzep.com
HuggingFace:https://huggingface.co/?ref=getzep.com
sentence_transformers:https://pypi.org/project/sentence-transformers/?ref=getzep.com
- 0004
- 0000
- 0000
- 0001
- 0000