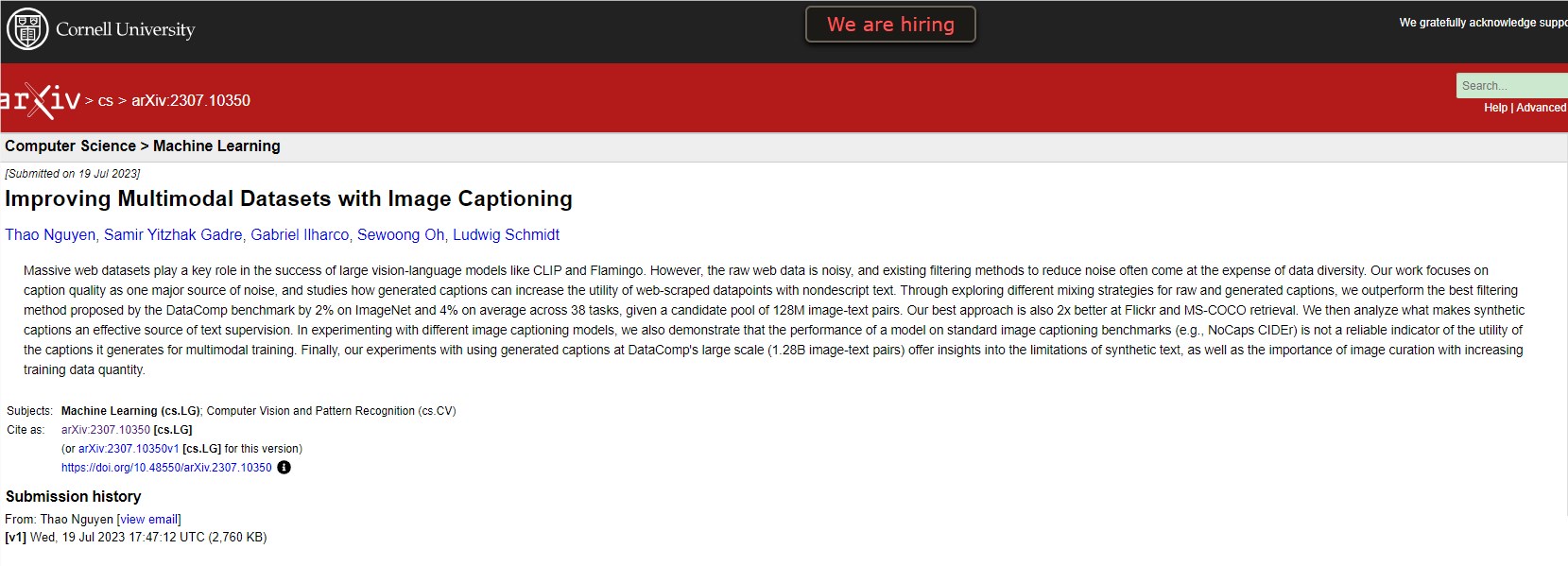
研究:合成字幕对多模态模型训练有用吗?
多模态模型是人工智能领域的重大进展之一。这些模型可以处理和理解来自多种模态的数据,包括视觉(如图像和视频)、文本(如自然语言)和音频(如语音和声音)。这些模型能够结合和分析来自这些不同模态的数据,执行需要在多种数据类型之间进行理解和推理的复杂任务。
由于大型多模态模型在视觉任务中被广泛使用,因此对这些模型进行图像 - 文本对的预训练已经证明可以在各种与视觉相关的任务上获得高性能。

论文地址:https://arxiv.org/abs/2307.10350
研究人员一直在尝试改善用于视觉任务中的大型多模态模型的网络数据(如图像 - 文本对)的实用性,但由于诸多因素的影响,如图像和文本不匹配、数据源有问题和低质量内容,网络数据经常含有噪音或无信息性。
目前,现有的方法虽然可以降低数据中的噪音,但往往会导致数据多样性的损失。为了解决这个问题,一个研究团队提出了一种关注网页抓取数据中字幕质量的方法。
他们的主要目标是探索生成的字幕如何提高具有模糊或无信息性文本的图像 - 文本对的实用性。为此,研究团队测试了几种混合策略,将原始网站字幕与模型生成的字幕相结合。
这种方法在数据比较基准 DataComp 提供的最佳过滤策略上取得了显著的优势。在拥有1.28亿个图像 - 文本对的候选池中,ImageNet 的改进达到了2%,在38个任务中,平均改进为4%。他们的最佳方法在 Flickr 和 MS-COCO 的检索任务中超过了传统技术,证明了他们的策略在实际应用中的可行性。
研究团队通过测试多个图像字幕模型来探讨人工生成的字幕为文本监督提供了什么样的帮助。团队通过研究发现,模型生成的字幕对于多模态训练的实用性并不总是由其在已建立的图像字幕基准(如 NoCaps CIDEr)上的表现好坏来确定。这凸显了评估生成的字幕的必要性,特别是对于多模态活动,而不仅仅依赖传统的图像字幕基准。
研究使用了 DataComp 的12.8亿个图像 - 文本对的数据集,以研究生成的字幕在更广泛范围内的应用。这个实验揭示了合成文本的局限性,并强调了在扩大训练数据的情况下,图像筛选的重要性的增加。
团队分享的见解包括:
选择一个字幕模型时,对预训练网络进行微调可能不会产生对多模态训练有效的字幕;
多个来源的字幕的组合可以提高在小规模和中规模 DataComp 基准上的性能;
在个体级别上,合成字幕的噪音较少且包含更多视觉信息,但在群体水平上,与原始字幕相比,它们缺乏多样性;
合成字幕的效益的可扩展性因不同的数据规模而异,通过尝试不同的数量,可以突显合成字幕的局限性,图像质量控制和多样性差距在更大的数据范围内变得更加重要。
- 0000
- 0000
- 0000
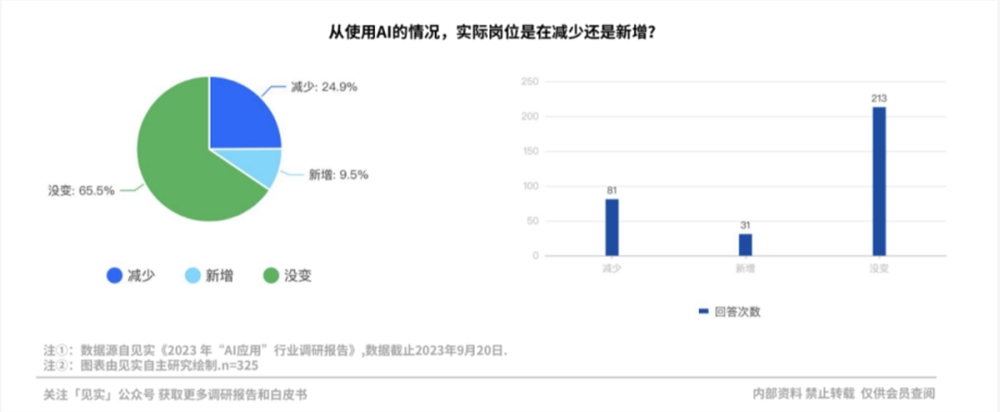
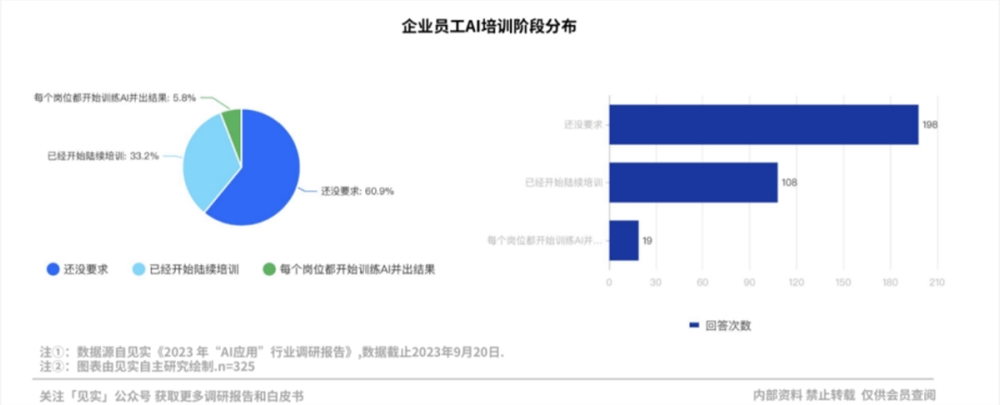
 0000
0000- 0000