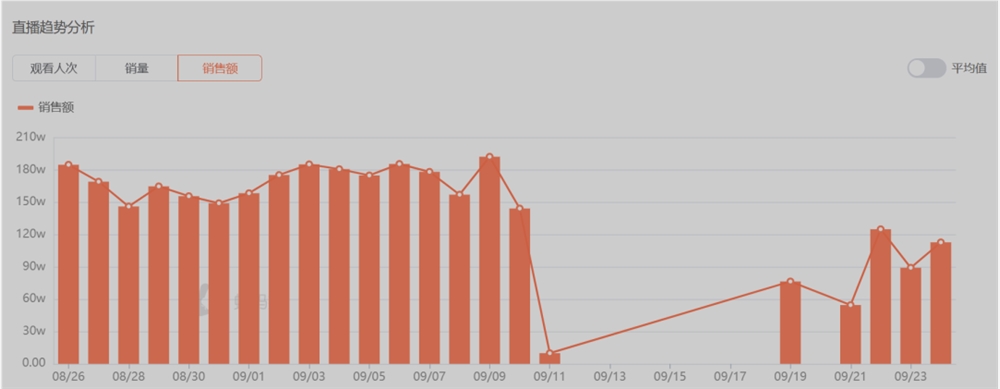
Prismer: 一个专家集合的视觉语言模型 支持多节点训练
prismer 是一种视觉语言模型的实现,旨在提供一个具有专家集合的系统。该系统基于 PyTorch1.13开发,使用了 Huggingface 的加速工具包,支持多节点多 GPU 的训练。它可以进行图像描述和视觉问答等任务,并且在预训练和微调方面都取得了良好的性能。通过继承来自公开的、预先训练的领域专家的大部分网络权重并在训练期间冻结它们,Prismer 只需要训练几个组件。
项目地址:https://github.com/nvlabs/prismer
核心功能:
1. 提供了 Prismer 和 PrismerZ 两种模型的预训练和微调检查点,可以进行零 - shot 图像描述和视觉问答任务。
2. 支持使用多个专家模型进行集合,提高模型的表现。
3. 提供了用于生成专家标签的工具,以构建多标签数据集。
4. 支持使用自定义数据集进行训练和微调,并提供了训练和评估脚本。
5. 提供了一个简洁的示例,可在单个 GPU 上进行图像描述任务。
优点:
Prismer 模型有几个优点,但最值得注意的优点之一是它在训练时非常有效地使用数据。Prismer 构建在预训练的纯视觉和纯语言骨干模型之上,以实现这一目标,并大幅减少获得与其他最先进的视觉语言模型同等性能所需的 GPU 时间。人们可以使用这些预先训练的参数来使用大量可用的网络规模知识。
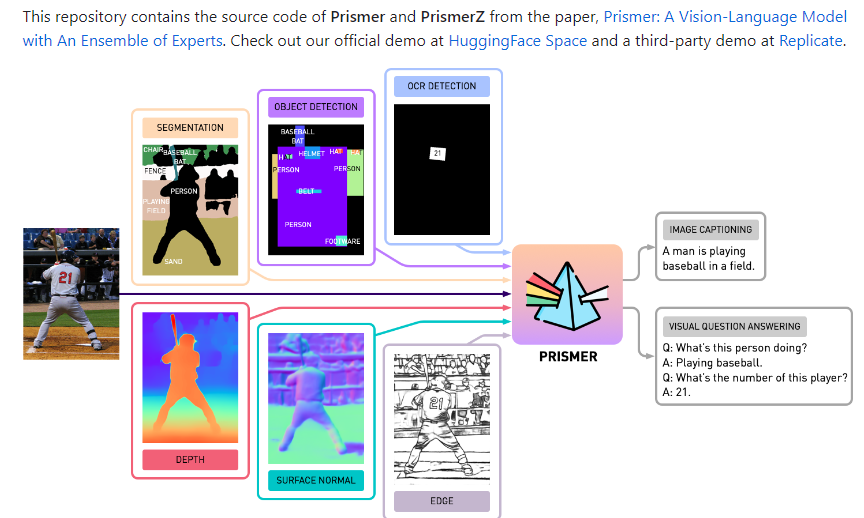
研究人员还为视觉编码器开发了多模态信号输入。创建的多模态辅助知识可以更好地捕获有关输入图像的语义和信息。Prismer 的架构经过优化,可以最大限度地利用经过培训的专家,并且可训练的参数很少。
研究人员在 Prismer 中纳入了两种经过预培训的专家:
主干网专家负责将文本和图片翻译成有意义的标记序列的预训练模型分别称为“仅视觉”和“仅语言”模型。
根据训练中使用的数据,话语模型的主持人可能会以各种方式标记任务。
特性
知识渊博的人越多,结果就越好。随着 Prismer 模态专家数量的增加,其性能也随之提高。
专业技能越强,结果越高 研究人员用均匀分布中的随机噪声替换部分预测深度标签,以创建损坏的深度专家,并评估专家质量对 Prismer 性能的影响。
抵制无益的意见 研究结果进一步表明,当噪声预测专家加入时,Prismer 的性能是稳定的。

 0000
0000- 0000
- 0000
- 0000
- 0000