对话LanguageX团队:在翻译领域,让AI的工作归AI,人类的工作归人
在ChatGPT掀起大模型热潮后,翻译行业被认为是率先受到冲击的。
OpenAI曾在报告中提到,如果一项工作使用AI能减少50%以上的时间,那么它就是可替代的,翻译就是容易被AI取代的职业之一。
但其实译员使用广义的AI技术工具来辅助翻译已不是什么新鲜事。一直以来,机器翻译软件之于专业译者,就如同Photoshop之于设计师。

部分机器翻译软件

部分计算机辅助翻译和翻译项目管理软件
目前,神经网络机器翻译是主流的机器翻译方式。毕业于蒙特雷高翻学院的Wang告诉我们,“现在业内大多数译员都会采用译后编辑的方式,可以以机翻为基础进行修改。但是对于有些保密性的内容,公司为了避免风险可能会要求译员不能上传机翻平台,尽量自己手翻”。
ChatGPT的翻译能力则比机器翻译更胜一筹,比如能提供润色、生成多种译文、变化译文风格,但在译文的准确性和完整性上存在局限,短期还不能与人工翻译相媲美。如果译员翻译能力在机器技术水平之下,那有可能就会被取而代之。
如今译员要怎样和AI共存?作为一家深耕语言科技领域的上市公司,甲骨易推出了面向专业译者的AI翻译平台LanguageX,近期升级了新版本,支持AI翻译、AI润色、训练个性引擎等功能。
他们提出:让机器的工作归机器,人类的工作归人。
最近“头号AI玩家”找到LanguageX团队负责人李光华(David),和他聊了聊怎么训练翻译行业的垂直大模型,怎么做AI翻译产品,以及AI时代的译者要往哪里去。
从机器辅助翻译,到生成式AI翻译
头号AI玩家:您是什么时候加入甲骨易的,之前接触过AI翻译吗?
David:我本身是学俄语专业的,毕业之后做过俄语和英语的翻译,当时觉得很多翻译工具又笨又重,后来就转型去做这方面的产品研发,加入甲骨易快3年了。
我很早就接触过机器翻译(Machine Translation,MT),那时还不叫AI翻译,AI也尚未流行。在语言服务中我们会用到机器翻译软件,但是效果比较差,有很多局限,基本上只是一种辅助手段。
再早一些,大概在40年前,翻译专业就有一款叫做Trados的计算机辅助翻译软件,它会把你之前翻译过的句段和术语保存到数据库里,当遇到重复的内容就不用再翻译,它可以直接调用,提升翻译效率。
Trados页面
这种计算机辅助翻译(Computer-Aided Translation,CAT)是机器翻译的初级阶段,前者要在人的参与下完成翻译,后者可以自动翻译。
2016年,谷歌发布了神经网络机器翻译系统(Neural Machine Translation,NMT),大幅度提升了机器翻译质量,在业内引起了震动。这时候人工智能也迎来第一波热潮。到今年ChatGPT的出现相当于又提升了一步。
头号AI玩家:AI翻译和机器翻译有什么区别?
David:我的看法是,机器翻译小于AI翻译。机器翻译约等于自动翻译,AI翻译的内涵会更大一些,除了自动翻译,AI还可以润色、辅助做翻译、提取术语等等。
在技术上,神经网络机器翻译和生成式AI翻译均是根据概率生成的,差别在于,神经网络机器翻译有编码器和解码器,近似BERT路线,有点像做完形填空,而GPT路线是做词语接龙,只有解码器,根据上一个词去预测下一个。在数据方面,机器翻译模型用双语平行语料训练,大模型一般用海量单语语料训练。
头号AI玩家:LanguageX有哪些功能?
David:主要有三大类功能。
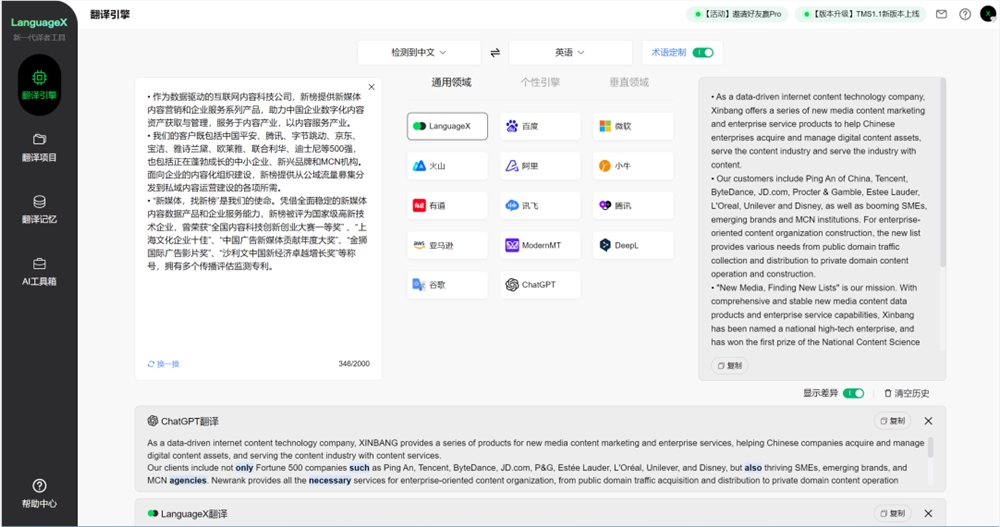
一是AI翻译,我们聚合了全球比较好的AI翻译引擎,比如谷歌翻译、DeepL、ChatGPT,以及我们自研的LanguageX翻译引擎;
LanguageX页面
二是辅助专业译者翻译。支持交互式翻译,译者在翻译一句话时,我们会把译文作为一个提示显示在下方,只要他改了一个词,我们会根据这个词实时再重新生成一遍。这样他调整句子就不需要来回剪切粘贴,思路不会被打断。
同时,译者也可以用自己积累的数据去训练个性化的机器翻译引擎;
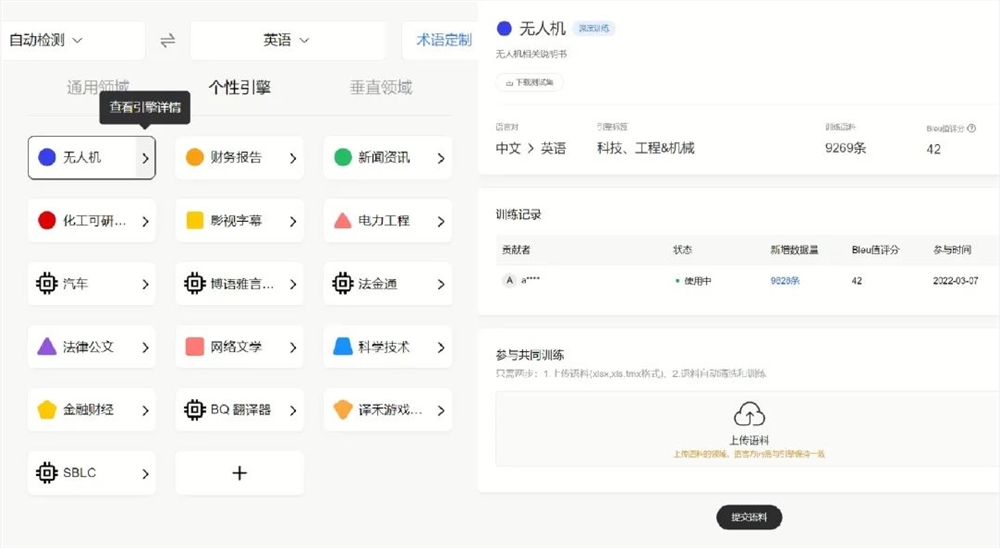
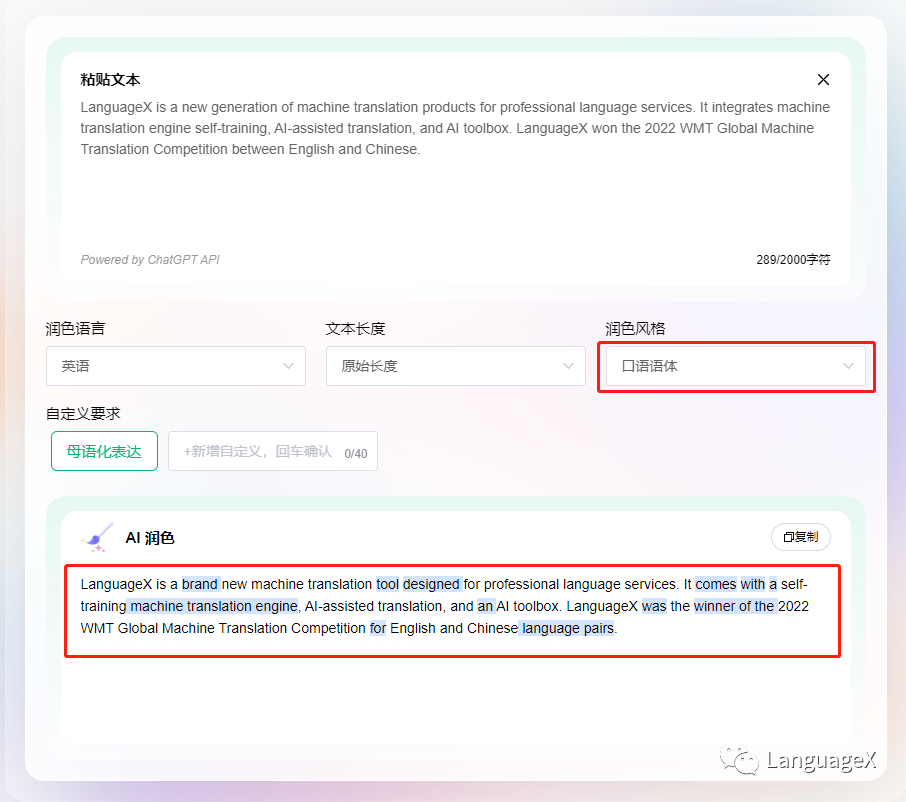
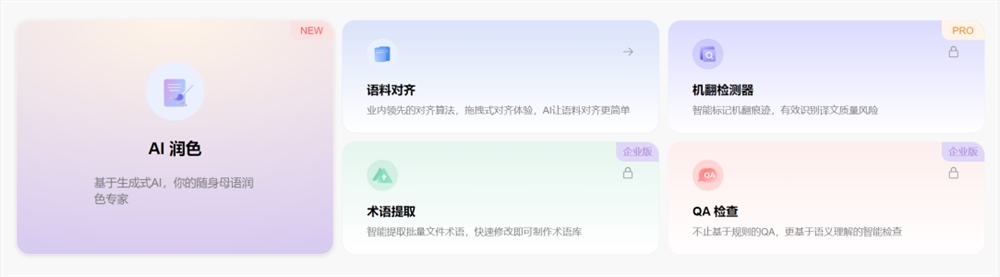
三是一些AI工具。“AI润色”目前接入了GPT的API,可以自定义风格,比如要求更地道的母语表达。还有“语料对齐”,可以把原文和译文两篇文档的内容一句句对齐,这样译者能拿来训练引擎或者做翻译记忆。
头号AI玩家:LanguageX有哪些典型的应用场景?
David:我们有两个大的使用场景,分别针对专业译者和普通用户。
专业译者每天的工作就是要非常精准地翻译一篇几千字的文章,一般需要翻译的字数是5000到10000。他可以先在LanguageX上建一个项目,拿到一篇文档后直接上传,它会自动解析这个文档。
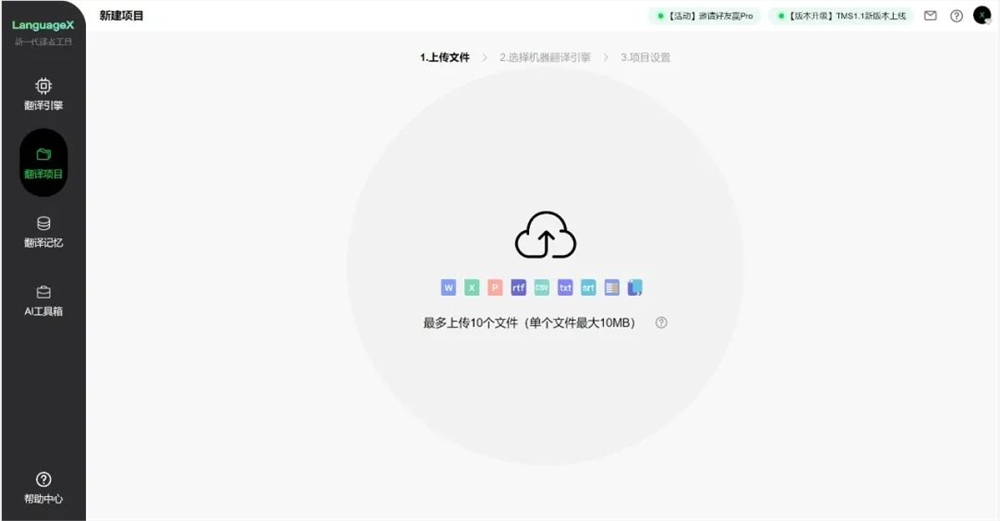
然后译者来选择合适的翻译引擎,比如字幕引擎。AI会预翻译一遍,之后译者进入编辑页面来修改译文,他可以在编辑器里跟AI交互,比如AI会提示一些术语,帮他检查一些年份、标点等低级错误。

下载后,它直接就是一个可编辑的word文档。这是一个比较简单的专业译者的翻译流程。
普通用户如果看到海外的书或者报道,也可以上传到LanguageX,但选引擎的时候就不需要那么精细,可以选一些自己熟悉的,加一点术语干预,让它处理的译文可读性更好。这是一个非专业译者的案例。
头号AI玩家:训练自己的翻译模型,这个功能用得多吗?需要自己提供训练语料?
David:这一类还是比较多的。如果我们来分领域的话,往往会分得比较大,像财经、法律、医疗。但有些用户的引擎就很有意思,比如专门用来翻译魔术资料,他的引擎叫魔术翻译,还有翻译摄影专业书、无人机相关材料的,类似这种个性化的细分领域。
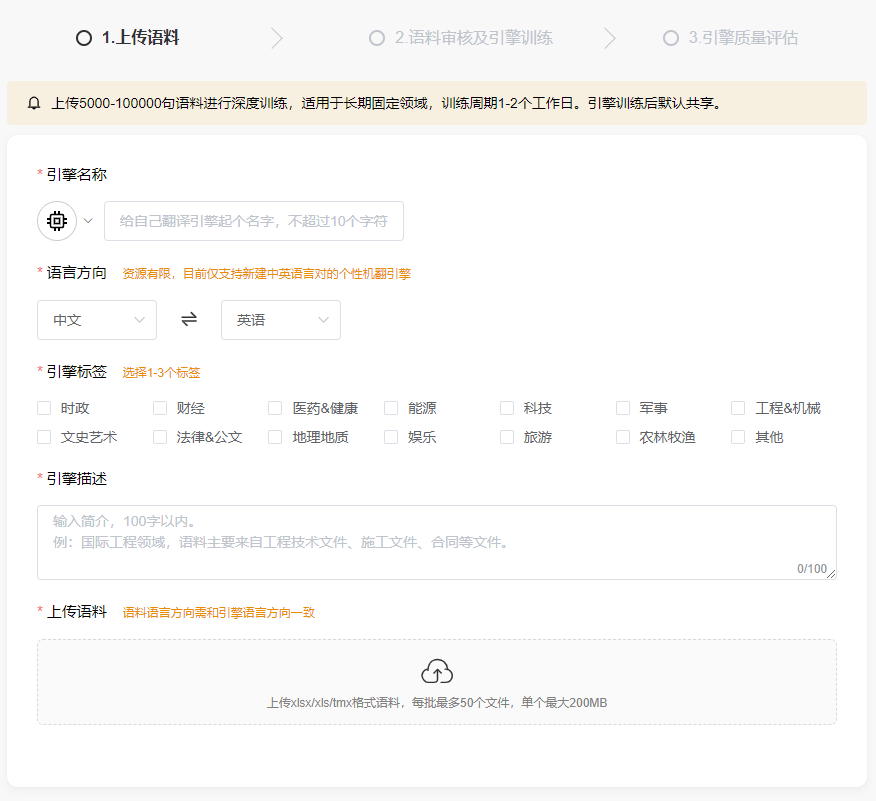
而专业译者可以根据项目或者自己翻译较多的领域来训练模型。训练语料确实需要自己来积累,专业译者从业一两年,基本上就会有大量的资料,可以通过“语料对齐”工具处理成一一对应的数据上传。我们的操作还是比较简单的,只需要三四步,不需要译者懂API等技术配置,训练完成后就可以在阵列选用了。
如何做一个翻译行业的垂直大模型
头号AI玩家:LanguageX团队是怎么组建的?
David:当时我们是从零开始组建团队的,我们的初心是用最先进的AI技术服务于专业的译者。
之前根据我们初步的评测,从翻译任务来看,ChatGPT在中英翻译上有一些微弱的优势,但是小语种翻译弱于现在业内主流的翻译系统。当然技术更迭很快,我们之后隔一段时间会再去评测。
研发方面我们有算法和工程团队,我们也在研究用于翻译的垂直大模型。
头号AI玩家:研发时最大的困难是什么?
David:做生成式大模型当然困难挺多的。以前翻译系统是一个语言方向做一个系统,比如中翻英、英翻中、中翻俄、俄翻中,这三个语言就要四个系统。现在我们希望哪怕是10个、20个语言,都是一个系统。所以我们要考虑大模型里的语种比例,以及数据的分布。
这需要很多试训练,做很多的反馈和迭代,就像打磨一个产品,不能一蹴而就。这是比较大的一个挑战。
然后还有成本上的考虑。GPU如果训练的数据量太大,算力成本是个问题,我们作为一个商业化产品团队,整体投入都要考虑ROI,比如提升了多少性能,如果说只是微弱的提升,但是消耗成本很大,就要做取舍。
头号AI玩家:如何判断AI翻译的好坏?在训练中有哪些衡量标准?
David:我觉得可以通过两个方面来判断。
一方面是它有没有达到预设场景的预期。比如字幕翻译中,中文如果先说主句、再说从句,翻译成英文后顺序倒了,那字幕就对不上口型了。以及常见的翻译引擎是按照一句句话为单位的,不记得这句的“他”是指代前面哪个人。我们针对这些问题,把几句话作为一个整体去训练,AI就会记得上下文。
要是AI拥有了这样的能力,我们就认为这是一个好的引擎。需要注意的是,字幕翻译引擎用来翻译专利材料,发现翻得不好,这很正常。所以我们首先要界定翻译的场景。
另一方面,要看AI翻译的数据有没有形成闭环,训练和使用的过程对这个AI系统有没有帮助。比如我们平台设计了使用过程中会提供一些反馈,这样AI会持续优化改进。
具体到质量评测方面,国际通用的标准Bleu/Comet等指标会计算和参考译文的相似度,给出一个打分。包括机器评分和人工评分,译者会评估“信达雅”,主要是“信”(真实可信)和“达”(得当流畅)。
头号AI玩家:翻译大模型的参数量会达到多少?能反映出翻译的质量怎么样吗?
David:确实是成正比的一个关系,参数量越大越好。但是翻译的训练数据大部分还是需要平行的语料,原文和译文对应起来。参数更高当然更好,但是数据量会急剧增大,而且找不到那么多语言类数据去训练。
我们目前模型大概是几十亿参数。我们还在试验,几十亿应该是一个比较好的区间,可以达到不错的翻译效果。
头号AI玩家:训练的数据主要来自于哪里呢?
David:主要是我们之前在语言服务业务上积累的大量数据,当然也有些公开的数据。
头号AI玩家:LanguageX的商业化模式是什么样的?
David:我们从上线第一天就有免费试用和付费的版本,专业用户或者深度内容消费者购买付费版本还是比较多的。因为我们产品使用门槛比较低,前期C端用户比较多,付费比例也高于预期。之后我们可能会考虑组织协作需求来更新产品,B端用户会相应增加。
头号AI玩家:影响用户付费意愿的主要因素有哪些?
David:现在有免费的翻译平台,但是我们做得比较专业,又比较友好,还是有比较多用户愿意付费使用的。
我觉得影响付费意愿的因素,首先看是不是解决了用户的实际问题。比如他上传一个30MB大小的PDF,市面上大部分翻译平台可能只支持10MB,那我们就可以传上去。
其次,我认为比较重要的是这个产品能否传递一种理念或者温度。我们的slogan是“为热爱语言而生”,我们希望这个产品让用户觉得翻译很有乐趣,又很简单。以前的翻译软件可能要专门培训一段时间,译者才会安装和使用,我们想尽量降低用户使用翻译工具的门槛。
头号AI玩家:甲骨易在AI产品上的工作重心是什么?未来有哪些规划?
David:一方面是增加协作功能,之前主要是个人版本,但精准的翻译场景,基本上必须需要协作才能保证产出是精准的。专业翻译这个场景有不同的角色和流程,比如项目经理来管理十个译员共同协作翻译一本书,还有译员、审校以及不同的流程。就像设计类的figma,我们想让从业者直接在平台界面上协作。
还有就是围绕专业定位打造社区,我们现在有一个初步的社群,大家可以在群里反馈问题,后面可能会有一些相关的资讯,甚至订单,去满足专业群体的需求,让社区也服务于语言服务这个群体。
为什么AI还取代不了专业译者
头号AI玩家:ChatGPT出现后,对LanguageX带来什么影响?
David:确实有影响。一些朋友会觉得翻译消失了,如果要套用三体的这句话,其实很多工作都可以这么说。比如自然语言处理也可以说消失了,因为之前我们都是训练一个单独的小模型做单独的任务,现在突然一个大模型来做,所以确实有这种情绪。
但我认为,大模型短期内被高估了,长期被低估了。
大模型在这个阶段被高估了,大家觉得AIGC好像是万能的,在翻译领域有人觉得ChatGPT比其他引擎好很多,但从真实的评测来看,我们在不同类型找代表性的几百个句子进行打分,结果是如果把ChatGPT当做一个翻译系统,那它现在可能处于中上水平,算不上最强的翻译系统。
而且ChatGPT只覆盖了十多个语言,全球有7000个语言。在使用方式和体验上,我们也不能每次都复制原文、给了提示词才能翻译。我觉得在专业翻译这个场景,还有大量的产品和工程问题。
长期的话,大模型是被低估了,因为理解和表达是ChatGPT的重要能力,它其实是我们人类非常底层的能力,机器拥有之后带来的变化可能无法预测。
现在很多AI产品,给我一种马拉汽车的感觉,有很多条条框框的阻碍。比如产品设计上很难改掉历史的惯性。我们今天看到这种APP或网站的形态,我觉得之后都会有大变化。现在还处于很早期的阶段,AI翻译产品也一样。
LanguageX最早框架受辅助翻译影响非常深,首页并不是AI翻译的矩阵,而是一个上传文件的入口,后面我们发现这个矩阵越来越重要,才改成了入口。我们正在努力去打破这种惯性,多一些创新。
头号AI玩家:那ChatGPT现在不会对你们造成太大威胁?
David:ChatGPT出现之后,我们尽快接入了产品,希望更多地了解GPT本身以及这个技术的潜力和边界。短期内我觉得是高估它,但我担心的是长期。可能2年之后,ChatGPT的能力范围又大了一圈。
对我们而言有点危机感,但我并不悲观。
之前译者每天翻译5000字已经到了极限,现在可能达到1万字,未来有可能5万字,10万字。质量没有下降,但是产出多了。也就是说语言服务工作者可以以相同的价格,为客户提供十倍甚至百倍的更高效服务——今年ChatGPT的加持,加速了行业效率提升这一过程。
在AI模型方面,之前我们的中译英模型都做好了,正在犯愁还有这么多语言,而现在我们有机会把好多语言放在一起训练,用更高效的方式训练。所以我觉得GPT技术是一个利好,AI能快速降低跨语言的门槛。
头号AI玩家:翻译对精准度要求很高,AI翻译会出现胡说八道的情况吗?要怎么处理?
David:会有,生成式模型都会有这种概率偏差,其实从神经网络机翻开始就有这种无中生有的情况。所以我们说以前的规则机器翻译是“傻子”,神经网络机器翻译是“疯子”,有的时候乱发挥,现在这个生成式AI就更疯了。
从技术上来说,这个问题还是一个业界难题。需要再次检查,在产品层面,我们可以用一些术语来约束它,以及使用自动检查。我们第一步会用质量检查QA,接下来流程里还会增加审校的环节。
头号AI玩家:您如何看待国内外AI翻译的行业现状和发展趋势?
David:AI翻译是ChatGPT很直接的一个能力。我觉得大趋势是会有更多的大众翻译的产品出现,比如集成到各种平台的插件。
但我觉得精准的翻译还是很重要的,很多场景下我们需要精准、可以信赖的,而不是仅用于参考。这方面AI还无法解决最后一公里的问题。
国内外的话,从需求上来说,欧美这块是比较领先的,本身欧美的跨语言市场就非常大,比如美国是多语言多民族的一个移民国家,语言服务就很发达。但是怎么和大模型结合,我觉得欧洲稍微落后一点,中国和美国有些差距,在语言上我们应该是第二梯队。
目前纯面向大众的翻译产品太多了,但面向专业语言服务,且以AI为内核的比较少,海外同类公司比如有Lilt、Unbabel。新兴的创业公司一般都瞄准了看起来更大的大众市场,我觉得有利有弊吧。
头号AI玩家:您认为在翻译领域,哪些工作应该交给机器,哪些是人应该做的?
David:现在这个阶段我自己的判断是,排版、处理格式、打标签这些比较枯燥的事情最好是交给机器来做。还有一些低级错误的检查、整体术语统一,以及AI润色。润色这个能力之前我没想到,因为是比较有创造力的,但在这个行业里,找母语专家来润色稿件是比较稀缺的,所以AI也可以做一些润色工作。
我们人类的工作应该是保证信息可信赖,做判断、定稿,还有一些创造性的翻译最终仍需要人来确定。
当然这个判断是在变化的。我需要继续去学习AI到底是什么、能做什么,现在AI已经证明了比拼技能、比拼知识的话,它的表现很强,所以我觉得人的核心竞争力不是某种技能或者知识,而是更底层的东西,像同理心、好奇、发散性思维。
不过对于译员来说,现在专业知识仍然还是一个壁垒,比如经常翻译专利的译员,他就知道专利摘要怎么遣词造句。
头号AI玩家:外语或翻译专业还值不值得学?
David:我认为语言肯定会变得更重要,现在大模型都是用自然语言来提问,prompt用英语写跟用汉语写完全是两个效果,外语可能会比以前还要重要,还是值得作为专业学习的。翻译只是语言应用的一个场景,可能在外语里的重要性会降低。
Wang认为,AI尚不能代替要求较高的笔译工作,更别提强调互动交流的口译了。虽然AI翻译还不成熟,但想成为有竞争力的译员,一定要去了解最新的技术。
对译员来说,学会使用AI工具已成为眼下非常急迫的一件事情。
“失去的工作不会再现,你只有和机器协作,创造新的岗位。”翻译过《人类简史》的资深翻译闾佳向九派新闻表示。
AI技术对从业者的冲击不是突然发生的,我们还有时间去主动学习AI,探索技术的边界,提升人类占优势、而机器难以提供的那部分价值。这是翻译从业者的应对之道,也是其他行业值得思考和借鉴的。
- 0001
 0000
0000

 0000
0000- 0000
- 0000