给人工智能“大模型”当保姆,都要操哪些心?
(一)ChatGPT和宋丹丹,谁陪你聊天更贵?
“有人花钱吃喝,有人花钱点歌,有人花钱美容,有人花钱按摩,今儿我雇个好活,有人花钱,雇我陪人儿唠嗑儿。”
2000年,作为一个小屁孩在电视前看春晚时,我决计想不到,有生之年世界上真能出现一个陪人唠嗑的机器人,还能唠得和小品《钟点工》里宋丹丹演的“大妹子”一样好。。。
二十三年以后,我等到了 ChatGPT。

先问你个问题:ChatGPT 和宋丹丹,你觉得谁陪你聊天会更贵一些?
看上去有点儿无厘头,其实这是个严肃的问题。你先在心里盲猜一个答案,然后我给你求解:
先来看钟点工的价格。
小品里宋丹丹说了,唠一小时40块。
再来看 ChatGPT。
它唠嗑的价格,一般人不知道,但中哥我知道。
这是浚源告诉我的。
给你介绍一下,浚源有三个身份:
一、人工智能老师傅;二、字节跳动火山引擎旗下“方舟平台”的研发负责人;三、不仅关心AI马儿跑,更关心马儿吃多少草的“现实主义者”。
话说,2022年底,ChatGPT 刚横空出世那阵儿,作为人工智能界的“老炮儿”,浚源简单跟它对话了几句,就得出了两个了不得的结论:
一、这种大模型加持的AI,掌握了理解上下文的能力,可以像人一样你一言我一语地“连续对话”。
就凭这一样,已经华丽丽地实现了几代人工智能科学家半个多世纪的梦想。
二、能做到这一点,是因为他们掌握了 AI 大模型的“涌现机制”。
从专业角度看,这个进步不是“骗炮”,它很可能让人工智能摆脱如中世纪般漫长的“人工智障阶段”,得以在各行各业迅速普及!
一想到“普及”两个字,他不困了,按捺不住想要算算这大模型运转的成本是多少。
话说,ChatGPT 的“工资”也是明码标价的——它是按照 Token 来计算的。
啥是 Token?咱们人类理解语言的基本单位是字词,但是大模型理解语言的方法稍有不同,它的基本单位就是 Token。
一个 Token 有时候对应半个词,有时候对应多个词,大部分时候对应一个词。
为了方便,咱们就简单理解为一个 Token 对应一个词吧。

这张图直观展示了啥是“Token”。
ChatGPT 跟你聊天,分为两步:
1)先理解你说的话;
2)再生成它说的话。
这“一听” “一说”,里头总共有多少Token,它就收你多少钱。
现在 ChatGPT 有两个版本,普通版的 ChatGPT3.5,还有史诗级的 ChatGPT4.0。调用 ChatGPT3.5的价格是“每1000个 Token0.002美金”;调用 ChatGPT4.0的成本大概是“每1000个 Token0.06美金”。
咱们就按一问一答500个Token算:ChatGPT3.5回答一个问题大概是不到1分钱人民币,ChatGPT4.0回答一个问题大概是不到5毛钱人民币。
也就是说,如果你打字飞快,把 ChatGPT4.0壁咚到墙角一顿唠,一小时能问出去几十个问题,极限状态也能耗费掉30-40块钱。
说到这儿,我们的问题大概就有答案了:
目前人类最先进的 AI 大模型——ChatGPT4.0——竟然和宋丹丹老师陪聊的价格差不多。。。
它聊一小时也相当于黄宏老师的1小锤,0.5大锤。。。
相当于赵丽蓉老师的0.22杯宫廷玉液酒。。。
好,不开玩笑了。其实刚才这些计算都是非常粗略的,不足作为商业参考,我讲这些只是为了让你能直观地感受到:
人工智能不是省油的灯——“大模型”干起活来,其实成本并不低。
而我们今天要讲的所有故事,皆与此相关。
话说,大模型干活的成本高低,本来和浚源也没太大关系。因为他当时还在忙另一个项目,测试大模型只是满足一下自己该死的求知欲。
可是,2023年3月底的一天,他的命运轨迹突然如秋名山的赛道,来了一个急转弯。
当时火山引擎智能算法负责人吴迪找到他,开门见山:眼看大模型的浪头已经开始翻涌,火山引擎准备跳进这个历史大潮里,你要不要来?
“来!”浚源回答很干脆。
浚源
(二)一帮人工智能老师傅,发现了啥惊天大幂幂?
老规矩,在讲“老师傅搞事情”之前,为了让浅友们都能上车,咱们还是先把时间暂停,强势科普一点儿基本姿势。
问:到底啥是大模型?
答:就像飞机是用钢铁模仿鸟儿翅膀一样,大模型是用计算机模仿人类的大脑。
咱们的大脑之所以能做决策,是因为它把学过的知识、见过的人、想过的事情都做成了“缩略图”存在了脑细胞里——遇到啥问题,去“缩略图”上查一下,就能得出答案。
你老板之所以给你发工资,不就是因为你有这个技能点么?
大模型也是一样——你只要把全世界的知识都拿来,然后像虎妈一样督促它“好好学习”,也能在它“大脑”里生成缩略图。
和你一样,大模型也能用这个能力打工赚钱!
问:那一个大模型从“啥也不是”到能“打工赚钱”,中间拢共分几步?
答:分五步。
1、找一座“贵族学校”。
众所周知,训练“AI 模型”需要用 GPU 卡。训练 AI 大模型,更是得用成千上万个 GPU 卡。
GPU 卡堪比黄金,每张都得一万美元起步,堆在一起妥妥就是盖了一座贵族学校嘛!这也没办法,大模型的本质就是氪金魔法,没有金刚钻,别练大模型。
2、找来一堆“课本”。
所谓课本,就是数据,成吨的数据。(训练一个靠谱的大模型,怎么也得几千亿 Token 吧。。。)
课本里的知识越多、越纯、越高级,最终学出来的大模型就越厉害。
3、找一群“老师”来上课。
所谓老师,就是“机器学习平台”。把一个小孩纸丢进学校里,他是没办法自学成才的,得有老师来讲课。
同样,AI 也需要“灵魂的工程师”。
机器学习平台负责“安排课表”,然后对照“课本”上的知识一堂一堂地给大模型“上课”。所有知识都学完,大模型就毕业了。
4、找一群“师傅”来带徒弟。
你懂的,很多毕业生虽然满脑袋都是知识,但啥也干不好,因为没有专业领域的实践经验嘛!
大模型也一样,得根据它将要承担的具体工作,找个“师傅”来继续做“职业培训”。这个过程就叫对模型的“精调”。至此,大模型的“训练”阶段终于结束,可以出徒了。
5、大模型开始“搬砖”。
大模型搬砖的姿势,学名叫做“推理”。比如,我给大模型提一个请求,它在“大脑”里过一下,输出一个结果,就完成了一次推理。
当然,每次推理都会耗费一些计算力。
注意,有趣的事情来了:
推理的计算力成本和“模型大小”有关系。
说到一个模型的大小,其实就在说它包含多少个参数。就拿 ChatGPT3.5来说,它的模型大概有几千亿个参数(具体数量没有公布),而 ChatGPT4.0大概有上万亿个参数(具体数量也没公布)。
你可以把参数类比为人的“脑细胞”。
思考同样的问题,脑细胞多的“大脑袋”比脑细胞少“小脑袋”更耗费能源。当然,“大脑袋”能解决的问题也更复杂。很公平,对吧?
诶,就在这里,老师傅们发现了一个惊天大幂幂。
啥秘密呢?
AI大模型的复杂度并不是随着任务复杂度“同步增加”。任务复杂,模型必须指数级增大。这也意味着推理成本会随之提升。
人脑则不同:随着思考问题难度的增加,推理成本几乎不会上升。(当然人脑存在一个思考极限。)
大幂幂来了:假如要处理的问题难到一定程度,“AI 大模型解题的成本”就会超过“人脑解题的成本”。
那 AI 大模型大到啥程度,就会比(同等聪明的)人更贵了呢?
拿2023年的科技水平来说,至少在 ChatGPT4.0能处理的任务复杂度这个级别,人和 AI 的成本已经大致相当了。(这下你明白为啥我在文章开头要算那个账了吧?)
当然,浚源强调这样简单比较并不准确。但一个总体趋势是:特别难的任务推理成本还太高,目前不太实用。
了解了这些,我们再回到吴迪和浚源他们身边,你就能跟上这群“AI 老炮儿”当时的思考逻辑了:
像 GPT4.0那样超大的模型,更靠近通才——靠一个模型就能胜任多种工作。虽然研发一劳永逸,适配各行各业相对简单,但是它的推理成本会很高,甚至超过真人!
明显用人来干更便宜的情况下,谁会用 AI 去干呢?
像 GPT3.5那样或者更小一点的大模型,更靠近专才——必须针对各个工作单独调整模型,才能完美胜任。(或者说它也是通才,但比真正的通才更专一些。)
虽然适配工作很麻烦,但是,它的推理成本低啊!大家用得起,才有商业化的动力。
话说,就在我们故事开始的2023年3月,眼看中国大大小小的企业都已经开始研发大模型,堪称“百模大战”。
当时很多看客觉得,中国大模型要想追上 ChatGPT3.5的水平,起码得2-3年。但浚源掐指一算,不用那么久——预计到2023年底,大家就能追上 ChatGPT3.5的水平。
这也意味着,“小而专”的大模型在中国的商用已经箭在弦上。
有了这些共识,老师傅们再盘腿坐在一起,商量火山引擎要搞点儿啥事情。
他们得出结论:既然这么多小而专的大模型想进入各行各业,必然需要根据具体的工作种类进行定向精调、各种适配。
那作为云计算服务商,能不能把各家大模型都放在一起,火山引擎提供统一的平台和工具,帮这些大模型在各行各业落地呢?
这不就是那个经典逻辑么?在美国西部淘金热的时候,赚大钱的不是那些亲自淘金的,而是在一旁卖铲子的。。。
但我转念一想:不对啊!帮大模型在各行各业落地,这是你说帮就帮的么?这些大模型愿意么?各行各业的客户愿意么?
其实,2023年春天吴迪忽悠浚源“入伙”时,浚源就提出了这个疑问:“咱们家里到底有啥矿,让人家非得和我们火山引擎合作不可嘞??”
吴迪呵呵一笑:你有所不知,就在此时此刻,智谱、MiniMax、出门问问、澜舟科技、百川智能这些明星公司的大模型已经跑在咱们火山引擎上了!
吴迪
(三)火山引擎的“朋友圈”来之不易
实话实说,第一次听到吴迪说“中国很多明星大模型都跑在火山引擎上”,我也觉得他在吹牛。
怎么可能有这么多嘛?!
但是仔细了解了“火山简史”之后我发现,如果我是大模型创业公司,可能也会把大模型放在火山引擎上来训练。
听我来讲讲这段故事。
火山引擎跟人工智能的关系,怎么说呢。。。就主打一个“家传”。
话说,字节跳动的两大天王——抖音和今日头条——它们火爆的原因有千万条,但如果只能说一条,那肯定是“人工智能推荐技术”。
就拿抖音举例,它有一个熊熊燃烧的人工智能推荐引擎,可以对平台上发生的一切细节进行实时计算,然后针对每个正在刷抖音的用户,找到此时此刻你最有可能喜欢的短视频,随着你手指轻轻一划,这条短视频就传输到了你的屏幕上。
想想看,能给几亿人“量体裁衣”推荐视频的人工智能,训练起来得有多艰难、运转起来得有多壮观。
有关这个推荐引擎,篇幅有限今天就不展开了,浅友们可以参考《你在被窝里刷手机,一个引擎在远方玩命奔跑》《你在抖音上点的小红心哪里去了》。
我要说的是,它就运转在火山引擎上。
你注意过抖音登录屏幕这行小字么?
其实,火山引擎这些年一直在给自家业务提供服务,2020年才正式挂牌对外提供基础计算力,算是云计算的后后后来者了,在市场份额上自然照阿里云、腾讯云有不少距离。
但这里要注意,我所说的距离是指以“CPU”为基础算力的传统云;在以“GPU”为基础算力的人工智能云上,火山引擎可是并不逊色。
刚才咱们说,训练大模型很像“送 AI 去上学”,不仅是指学的过程像,连“卷”的样子也像。
咱们人类教育已经卷到了极致,卷完学区房卷学校,卷完学校卷老师,卷完老师卷辅导。
送 AI 上学也一样,家家不都得找“师资力量”最强的学校么?!
火山引擎“师资力量”咋样呢?我说两个事儿你感受一下:
第一,火山引擎上有“名校”。
刚才说过,GPU 是大模型的学校。
无论是前几年互联网的蓬勃时代,还是疫情的低迷时期,火山引擎对于 GPU 卡可是从不吝啬,一直在买买买。
当然,这主要是因为它的“客户”抖音、今日头条发展太迅猛,对底层AI计算力的需求一直饥渴。
然鹅,这客观上导致火山引擎成为了中国 GPU 的大户。
虽然官方没有披露数据,但是火山引擎手里掌握的 AI 计算力,绝对是全中国数一数二的,数三都不太可能。。。
现在全世界都掀起大模型浪潮,所有人都在争抢 AI 计算力,在这种“饥荒”状态下,看到火山引擎手里充沛的 AI 计算力,那不就是饿了三天看到肉包子的效果么?
第二,火山引擎上有“名师”。
刚才也说过,“机器学习平台”就是大模型的老师。
可这老师具体是咋工作的嘞?我简单给你摆一摆。
1)你可以把大模型看成是一个有千亿个脑细胞的大脑,老师教授知识的过程,从细节上看就是在“调整每一个脑细胞的参数”。
2)每一本“书”进入大脑,都会刷新一遍所有脑细胞的参数。老师孜孜不倦地一本一本往脑袋里装书,脑细胞参数就一遍一遍被“刷新”。
3)但这里的问题是,由于操作太精密,每一波脑细胞参数完全刷新之后才能存档(CheckPoint),进行过程中是不能“存档”的。
一旦中断,至少得“一本书”从头再来。
4)训练一个大模型,需要几千张 GPU 卡连续工作几个礼拜,你中间卡碟,心若在梦就在,只不过是重头再来,那前面白算的一段成本谁给报销?!
5)所以,训练必须一!遍!过!
仔细想想:这种大模型训练过程,跟杂技“顶碗”是一样一样的,所有的碗必须全部到位,一个碗碎了,整个杂技就都废了。
这还不够,GPU 是人类最精密最凶残的造物——每张 GPU 卡700w,一个机箱里插8张——光是发热已经秒杀了一般的电暖气。。。
你想想看,这大夏天的,人脑子都容易热傻了,何况电脑。一堆“电暖气”在一起绞尽脑汁儿算数,一个不小心就会导致故障。
还没完,在保证不出故障的情况下,你还得尽量提高 GPU 的使用效率,确保整个“教学任务”用最短的时间完成。
所以,火山引擎这群“老师”(机器学习平台),必须同时做到三点:
1、制定最有效率的教学大纲(保证训练总时长最短);
2、严谨地教书育人(保证训练过程不出错);
3、维持课堂秩序(保证底层硬件之间的协作顺畅)。
这难度就不是顶碗了,这是顶碗的时候踩着平衡木,手里还得扔着五个球。。。
怎么样,这活儿不是谁都能干的吧?
话说这些技能,火山引擎的老师傅也不是一开始就会的。但是。。。这几年为了支撑抖音用户从1亿到2亿,从3亿到6亿,老师傅不会也得会。
比如他们搞出了“0碎片”技术,保证每一丝 GPU 都被用到极限;比如他们研发了一套AI专用的通信框架,让原来25天才能训完的模型用15天就能搞定。
大模型,那可是各家公司的宝贝疙瘩,很多创业公司几十号人就开发这么一个模型,自然要找最好的“学校”来培养。
看了一圈,火山引擎又有名校又有名师,妥妥的重点学校,来这儿也是顺理成章了。
就这样,从2022年开始,火山引擎和这些大模型公司陆续交上了朋友。
老师傅很清楚,这豪华“朋友圈”可不是误打误撞得来的,而是人家从心底相信火山引擎过去十年苦练的真功夫才会慕名而至——每一个朋友都来之不易,绝不能辜负,得帮人帮到底,送佛送到西啊!
怎么才算帮人帮到底呢?
吴迪掏出老司机的经验,开始盘算:
从2023年初到2023年底,这个阶段大家应该都在“卷”大模型本身,AI 计算力主要会用于“模型训练”;
但从这个时间节点往后,大家的模型都训练得差不多了,目标是进入各行各业,那就得有“师傅”来进行各种“职业培训”,也就是“模型精调”。
显然从那时起,“精调”所占用的 AI 计算力肯定会慢慢攀升——2-3年后,“精调消耗的算力”就可能超越“训练消耗的算力”。
如此说来,火山引擎要想让手里的 AI 算力和 AI 底层技术在历史长河里奔腾不息,就得不断根据水流调整开船的姿势:
1)先把大模型请上船,帮它们用最低成本和最高效率做训练;
2)再把千行百业务的客户也请上船,帮他们做精调和适配,让大模型这种新技术顺畅地融入他们的血液!
这,就是“火山方舟”大模型服务平台的由来。
怎么样,目标很清晰吧?吴迪拍拍浚源的肩头,去干吧!
不过突然被推入大海,从零开始造船,浚源还有点儿蒙——既然要做“平台”,火山方舟就得一手托两家,左手是大模型公司,右手是用大模型的各行各业——得同时满足两方的需求才行。
那。。。怎么才能让两方都满意嘞?
浚源首先想到的就是:得给大模型配个“脑壳”!
(四)大模型最怕“裸奔”
细心的朋友想必已经观察到了,人的大脑一般是不裸露在外面的。。。
这当然是因为大脑很柔软,也很精密,需要被格外地保护起来。
大模型也是如此。
简单来说,大模型有“两怕”。
第一怕:大模型开发者怕使用者探测到它的模型结构。这样一来,花费上千万美元成本训练的模型,就可能被人白嫖了呀。。。
第二怕:大模型使用者怕模型开发者看到它的数据。如果“用于精调的数据”和用户使用模型时的“请求数据”被拿走,那相当于企业机密就走光了呀。。。
这麻杆打狼两头害怕,还怎么合作呀?!
诶,有办法——像人脑那样,给大模型加个“脑壳”呗!
浚源告诉我,这个“脑壳”的学名叫做“安全沙箱”。
简单来说,它的原理是酱的:
1)安全沙箱绑在火山引擎上,既不属于大模型生产方,也不属于大模型使用方,与世隔绝。(沙子都漏不出去嘛!)
2)大模型生产方把模型 Copy 一份放在沙箱里,大模型的使用方把一条条“请求”加密之后送进沙箱,再把用于解密的钥匙放在沙箱里。
这样,全世界就只有这个沙箱里的大模型可以看到请求的明文。
3)同样,一条条回答从沙箱里送出来时,也是加密的,只有大模型用户有解密钥匙,这样,就做到模型使用全程只有“天知地知你知我知”。
4)如果需要对模型进行“精调”,也是同样的操作。大模型的使用方把自己用于精调的数据加密之后送进沙箱。
精调后的模型参数就留在沙箱里,大模型的开发者也拿不出来。
总之,沙箱就像一个完美的特工:该说的说;不该说的打死也不说。
对于字节这群顶级老师傅来说,做出这个安全沙箱简直是洒洒水,真正难的,是如何“一次成型”地把它快速做好。
确切地说,留给浚源的时间只有两个月。
为啥要的这么急呢?
很简单的道理:火山引擎上的各个大模型正在紧锣密鼓,都快训练得八九不离十了!
脑子都快好了,脑壳还没好,这哪行?!
可是,一个大模型的运转过程中,数据会像水流一样在云上的计算、存储、网络这三个基础设施里来回“流窜”。
要想造出一个滴水不漏的沙箱,就必须像大坝截流一样,把这三个峡口都堵严实,但凡有一样隔离不彻底,都有可能造成数据泄露。
更难的是,这三样基础设施是由火山引擎底层技术部门维护的,不是浚源团队自己说干就干的,得靠兄弟团队配合。。。
幸好浚源平时靠谱。这张脸,此时不刷,更待何时?!
这不,整个四月份,他派出了好几支“方舟远征军”,驻扎在各个产品团队里,上午说需求、中午聊架构,下午跟他们一起撸代码,晚上一起撸串。。。
老师傅们就这样一起撸了两个月代码,感情越撸越好,配合越来越默契,终于做出了一个紧致无比沙箱。
然后,他们马不停蹄把几大合作伙伴的顶尖大模型都塞进沙箱里。
至此,赛博世界华灯璀璨,老师傅们在街边列队整齐,伸出温热的小手,向千行百业的客户招呼——来呀,感受中国大模型的汹涌澎湃呀这个画面太美,不妨让它暂停一会儿。我先问你个问题:说了半天“千行百业”,你知道大模型到底能用在什么行业么?
我就不逞能了,直接让吴迪回答吧。
他把目前大模型的应用场景分成三类:
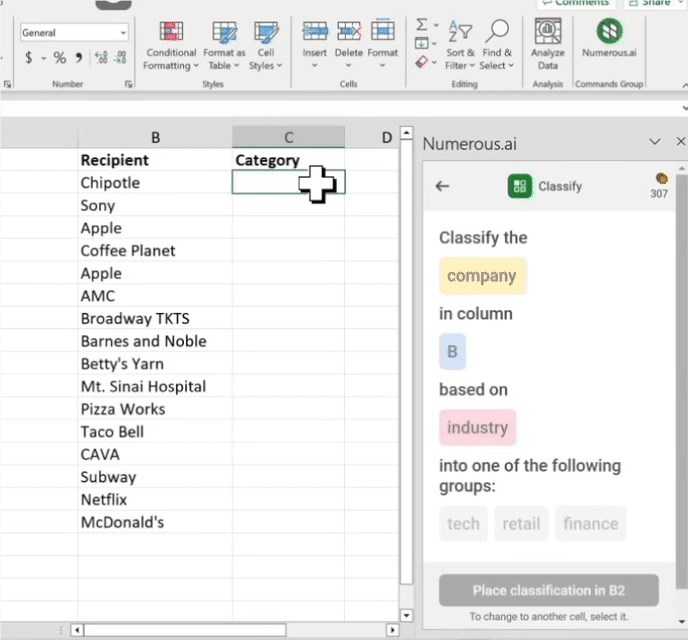
第一类是“生成”。比如大模型看了一堆A产品的资料后,就能变身“AI 客服”,顾客买了A产品,不用看说明书,遇到不会用的地方尽管提问,它都能对答如流。
第二类是“控制”。比如把大模型塞进汽车,它就能变成“AI 管家”。你说一句“我想在车里打个盹儿”,它就能帮你把座椅放倒,把空调打到不吹人的舒适温度,车内灯光调暗,没准还给你来个摇篮曲。
第三类是“辅助创作”。比如让大模型看一堆游戏设定和美术稿,他就能变身“AI 设计师”,游戏开发者可以让它自动生成符合游戏画风的道具、场景、NPC,还能创作符合 NPC 人设的对白。人类设计师只要在它的基础上修改就行,大大节省了创作成本。
你发现没,这些工作的共性就是:需要一些创造力,但不多。
或者你可以简单理解:目前大模型能胜任的工作难度,大致相当于大专院校毕业3年以内人类社畜的水平吧。
之前说过,由于推理成本的限制,做这些工作只能使用比较小的大模型。
比较小的大模型,只有适配后才能更好地完成任务。模型越小,这个适配工作就越多。
如此说来,既然火山引擎铁了心要帮助大模型在千行百业落地,那就必须有一个贴身团队来服务客户——就像“保姆”一样,帮他们配对合适的大模型,并且帮助他们降低使用成本。
那,这个“保姆”要谁来干呢?
吴迪想来想去,在火山引擎内部,还真有一个“服务型人才”,那就是老科。
你还记得字节跳动有一张技术王牌么?
没错,就是那个熊熊燃烧的可以同时帮几亿人推荐内容的“推荐引擎”。
好东西自然不能独享。早在火山引擎还没正式成立的2017年,“推荐引擎”就对外服务了——大大小小的企业都能用到“抖音同款”推荐引擎。而负责把这个推荐引擎接入千家万户的服务团队,正是老科的团队。
让他们来带领大模型面向企业的服务(AI to B)团队,有两个肉眼可见的好处:
第一、火山的推荐引擎已经接入了千行百业,很多公司都已经成为了好朋友,老科团队可以从里面挑选最好最好的朋友“送福利”,让他们优先试用“火山方舟”。
第二、毕竟大模型是人类科技的风口浪尖,客户试用之后难免会遇到些小问题。鉴于老科团队跟客户们都有交情,客户们要是有啥不满意,想打人的时候。。。下手不会太重。。。
2023年5月,火山引擎的几位老师傅去桂林团建,在大自然鬼斧神工的美景里,吴迪看着远方,问老科:“要不要来?”
老科说:“来!”
老科
(五)大模型的“保姆”和“红娘”
话说,要想保姆出场,得先让红娘出场。
因为在我看来,老师傅面临的困难,首先是“唐伯虎点秋香问题”。
举个例子吧:
我是A公司的老板,我们公司生产一种“夺命3000”的格斗神器,想用大模型做一个“AI 客服”。
此时我的角色就是唐伯虎。
我面前有一群“AI大模型”,我知道,里面一定有一个模型最适合做“AI 客服”——成本最低,效果也最好。它就是我的“秋香”。
唯一的问题是:这群大模型都盖着盖头,我不知道谁是“秋香”。。。
大模型是封闭在沙箱里的,开发者不可能打开脑壳给我看;就算开发者愿意给我看,面对一堆代码,我哪知道它到底适不适合我?
这里就要轮到“大模型红娘”出场了!
老师傅键盘敲得飞起,开发了一套“大模型评测工具”,专门在“不掀开盖头(头盖)”的情况下,通过对话来评测这个大模型是不是你的“秋香”。
简单来说,这个评测工具有两个功能。
第一个功能:“自动化评测”。
还拿A公司举例吧。我不是想做“AI 客服”么,那我可以自己写一些符合我要求的“问题和答案”,打包成一个数据集,放在这个评测工具里。
它会自动把火山引擎上所有的模型都跑一遍,然后给出分值。
分值越高,就说明这个模型给出的答案最接近我的数据集,那它就八九不离十是我的秋香了!
第二个功能:“人工评测”。
我觉得我家的“AI 客服”不仅要能回答问题,说话还要有文采。
但“文采”这个事儿非常主观,萝卜青菜各有所爱,自动评测就不太好用了。
这时我就需要“自主命题”,比如让所有的大模型都围绕“萝卜”给我写首诗,我最喜欢谁的风格就选谁!
注意,我一直在说“我的秋香”,而不是“秋香”。
意思就是,这些顶尖大模型之间的“优劣”差异本没那么大,反而是看谁更适合你的任务需求。
换句话说,你的“秋香”不一定是别人的秋香,有可能是别人的“如花”。
这就引出了一个新问题:
假如我的A公司想用 AI 大模型完成不同的任务,不仅要做客服系统,还要做内部培训系统,还要做宣传文案辅助设计系统——对于不同任务,最适合的大模型很可能是不同的。
这相当于我不仅有唐伯虎,还有祝枝山、文徵明、徐祯卿。。。他们日后分别要和秋香、冬香、春香、夏香配对协作。
但每个大模型开发者都不同,可想而知操作它们的姿势也不尽相同,这就很麻烦。
不用说,又到了“大模型红娘”出场的时候了。
当时意识到各个模型操作不统一的问题,老师傅火速开发了一个“统一工作流平台”。
简单来说就是,在每一个大模型的基础上,都安装一套“火山牌”转接插头。
这样一来,七国八制的大模型就被归拢为同一套操作流程,我只要学会跟“秋香”合作,那冬香、春香、夏香就都用同样的姿势就OK了!
扫清了这些障碍,我的A公司终于能“迎娶”秋香过门了!
这时,终于到了大伙儿一直期待的重要步骤——对秋香进行调教,也就是所谓的“模型精调”。
从这开始,也是老科的“保姆”团队重点要做的事情了。
话说之前咱们一直没来得及解释,到底啥是精调。
沿用我们的比喻,就是唐伯虎迎娶秋香之前,要把唐家府上的各种规矩拿出来,给她进行一套“职业培训”。让她在学习了社会的一般规范(在模型训练阶段就完成了)的基础上,继续学习唐府的个性规范(需要精调来做)。
具体的做法和训练模型时类似,也要拿来一些教科书(如果让它做“AI 客服”,这里就需要“产品说明书”的数据),然后请老师(机器学习平台)来上课,把大脑里的所有模型再刷几遍。
精调之后,秋香就不再是纯粹的秋香,而是“唐家夫人”了。
到这儿,保姆可以撤了吧?!不行,还有重要任务没完成。
那就是——玩儿命降低模型推理成本。
别忘了,在大模型训练的时候,“秋香”可是看了全世界的知识,这些知识她都学杂了,既会三国杀,又会C 。从摩托车维修技术到母猪产后护理,没它不懂的。
但讲真,做为一个“AI 客服”。。。并不需要懂母猪的产后护理。
所以,这里就要对模型进行剪枝,也就是忘掉一些一辈子都用不到的知识。
忘记之后大脑就“瘦身”了,每次思考时“过电”的脑细胞少了,耗费的能源自然就少了,推理成本也就大幅下降了!
剪枝做完了,保姆的任务完成了吗?还没有。
老师傅还可以通过算子优化,继续降低推理成本。
简单来说就是:既然知道这个“AI 客服”日后会经常思考哪些内容,不如现在就把这部分“脑回路”加固一下,做成一些思考的“快捷方式”。让它每次推理这些固定问题时能够更快速、更省流。
毕竟模型日后要进行亿万次推理,每次哪怕省出几个电子,那累积起来都是巨大的成本节省。
看到没,老科带着老师傅“逮住蛤蟆攥出团粉”——把能想的办法都想绝了。。。
有的模型经过他们一番调整,推理成本甚至能下降到最初的十分之一!
话说,大模型在整个人类历史中也才出现了半年,虽然老科是人工智能老司机,但很多地方也得摸着石头过河。
为了尽快积累经验,他们经常是组团去给客户精调模型——客户那边出一个工程师,老科这边能派出去好几个,这阵仗可给客户吓得不轻。。。
“这么干,成本能受得了么?”我表示震精。
“我们当然不会一直这样做。每次回来,我们都会把适配的经验尽快沉淀成工具,以后再做同样的事情,就会用工具辅助人来做。慢慢地工具的比重越来越大,人的比重越来越小,最终的目的就是让客户自己用工具轻松完成精调和适配!”
他笑。
聊到这儿时,我突然想到了字节跳动创始人张一鸣的一句话:“大部分事情你做第二遍的时候,要么做得更快,要么做得更好。”
这恐怕是“人类”和“人工智能”所共享的进步哲学,也是根植在字节跳动这群老师傅心里的技术信仰。
总之,整个2023年的6月,火山方舟上老师傅和用户面前仿佛摆了一桌“螃蟹”,两边一起吃,边聊边吃,把酒临诗,一场人类技术的艰难求索,就此变成了江心纵舟,登极远目。
2023年6月28日,老师傅向左跟几个大模型供应商挑了挑眉毛,向右跟几十家内测客户确认了眼神,决定正式对外发布“火山方舟”平台。
从春天艰难的从零起步,到夏天方舟气象初成,只经历了三个月时间。
(六)“人类之子”
在我和火山这群老师傅聊天的时候,方舟平台刚刚发布。
无数具体的大模型应用都在紧锣密鼓的精调训练中,老科得帮客户保守秘密,不能给我讲得太详细。
他告诉我,不用着急,丑媳妇肯定会见公婆——从现在开始到年底之前,大家会看到各行各业的大模型应用“井喷”。
大模型对我们的生活到底有啥改变,每个人都都能用今后的每一天慢慢体会。
但是,对于火山方舟的老师傅来说,他们没工夫坐在山头抽着旱烟欣赏自己的“造物”,打怪升级的道路才刚刚开始。
大模型就像一个“人类之子”,他可以不只有“脑子”,还可以有“手脚”。
啥是手脚呢?
比如,大模型可以写代码,但是写好的代码只能展示给人类,人类再粘贴到运行环境里运行。如果给大模型插上一个运行环境,它不就可以直接写好代码运行了吗?如果遇到代码错误,它就可以根据运行结果继续调试,直至开发成功。
再比如,大模型可以给你生成菜谱,但需要你照着菜谱自己炒菜啊!如果把一个机械臂连在大模型上,它就可以按照菜谱给你直接把菜做出来了!
这些连在大模型上的系统,统称“插件”。有了插件,大模型就相当于有了手脚。
怎么样,你有什么感觉?
没错,这不就是科幻电影里的“机器人”么?
你看,一旦有了插件,大模型就从一个“缸中之脑”变成了开放世界的真实玩家。
脚下的地图拓展成无穷,伴随的可能性也变成了无穷。在人间游走,它对伦理、文化、技术边界、哲学的冲击,可能将会次第展开。
可以这样说:
站在天空俯瞰,人类对大模型的应用历史就像一座迷宫。
但此时此刻,我们不仅不知道出口,而且,连迷宫的形状和特点还没完全探索清楚。
但除了接受挑战,我们别无选择。
不过对于火山方舟的老师傅来说,仍旧有三件事儿是绝对正确的,那就是:降低成本、降低成本、还是降低成本!!
浚源告诉我,除了老师傅十年来磨炼的人工智能“训练加速”和“推理优化”技术之外,还有一些更大的变量在影响大模型的成本。
比如,有没有可能继续把大模型做得更“精专”?
现在各行各业正在使用的大模型一般都有1000多亿个参数。但是,如果大幅降低大模型的参数,例如降到60-70亿个,会怎么样呢?
这种大模型,在普通人眼里显然不够“聪明”,但它用来完成极其特定的任务,却是非常省钱的!
就拿微软来说,他们就做了一个极小的 GPT,塞进 Excel 里,做成了 ExcelGPT。
这个 ExcelGPT 只会做一件事儿——按照常识帮你把表格补齐。
你看,这个大模型既不用懂摩托车修理,也不用懂母猪的产后护理,它只需要理解简单的常识。用一个极小的大模型就能完成任务!
看到这你也许有点懵,那到底多大的模型最合适呢?
这个问题,火山引擎的负责人谭待在方舟发布会上,用一个有趣的比喻做了回答:
就拿我们公司来说,我们有一些博士,攻坚最难的任务;但我们公司不都是博士,也有很多研究生、有更多本科生,他们每个人都负责相应的任务,让成本和产出达成最优的平衡。
相信大模型也是这样,未来一个公司可能同时使用很多大模型,有超大的模型负责最需要创造力的任务,也有小模型和专业模型负责更普遍的任务。
这些模型结合起来,各安其位,才是大模型的完整生态。
除了模型大小以外,底层的 GPU 的算力当然也会影响大模型的成本。
那。。。GPU 未来的算力会怎样发展呢?
浚源非常乐观:“在 AI 算力上,摩尔定律并没有失效,这些年都是非常平稳地“两年翻一倍”。”
英伟达创始人黄仁勋曾经预言,GPU 计算力仍将以超越摩尔定律的速度增长。
“那,大模型岂不是会越来越聪明?”我惊讶。
“我个人预计,大概20年后,人工智能的算力会达到现在的几百倍至一千倍。到那时,我们就能做出和人脑复杂度差不多的大模型。”他说。
“你的意思是,那时我们就能做出和人脑一样聪明的人工智能?”我问。
“希望如此。毕竟越来越多的证据表明,人脑本身没什么秘密,算力到了,数据量到了,自然就会达到这样的能力。而且,复制一个人要20年,它的遗传还不稳定;而复制一个大模型,我们只需要20分钟。”
如此科幻的结论,他却说得很冷静。
告别浚源和这群老师傅之后,这些话在我脑袋里反复回荡。
我感觉自己仿佛站在一扇大门前,雪白的光浪从外面拍打着大门,我站在一个广袤的新世界跟前,只是尚且不能目睹它的真容。
火山方舟试图降低“智能的成本”。
而从“智能的成本”这个角度出发去思考,本身就充满了野心——它在让脑力劳动标准化。
自古以来,有无数哲学家、经济学家、社会学家都试图为人类的思考定价。
然而,人有不同的价值观,有不同的经历和过往,有复杂的情感诉求——你我的付出和回报,并非用简单的成本和收益就能计算。从这个角度来讲,并不存在一个普遍意义上的“平均的人”。
以至于,精巧的经济学理论可能在一个历史时期做出精确预测,但终究会随着人类精神的进步而走向失效。
大模型这个“人类之子”恰恰解决了这个问题。
当无数个“人类之子”崛起,AI在全社会脑力劳动中占比越来越高时,“智能”就会成为一种新的石油——如汽油按照纯度进行标号,人类也将制造出不同标号的“大脑”,从而清晰地为“智力劳动”定价。
在这个锚点之上,技术就会成为一个跷跷板:
在它的一边,AI 的成本不断下降,去做过去不得不由人类完成的“平均智力劳动”;
在另一边,宝贵的、无法定价的人类思考会从泥泞中解放出来,去思考更加宝贵的、无法被定价的命题。
未来的某一天,我们也许会坐在漫天星光之下,琢磨自己存在的意义。
那时,不知有没有人会突然回想起几十年前,曾有这样一群人为了创造一个完美世界而拼尽全力。

 0000
0000- 0000
- 0002
- 0000

 0000
0000


