LLaMA 2:最新开源 GPT 模型的功能和演示教程
本文将为大家介绍最新发布的 GPT 模型 LLaMA 2 的新功能和更新内容。LLaMA 2 在原始模型基础上进行了改进,包括使用 40% 更大的数据集、经过强化学习和人类反馈调优的聊天变体以及可扩展到 700 亿参数的模型。文章还会为大家展示如何在 Paperspace Gradient 笔记本中运行 LLaMA 2 模型的演示。
型号概览
让我们首先概述 LLaMA 2 中可用的新技术。我们将首先回顾原始的 LLaMA 架构,该架构在新版本中没有变化,然后检查更新的训练数据、新的聊天变体及其 RHLF 调整方法,以及与其他开源和闭源模型相比,完全扩展的 70B 参数模型的功能。

LLaMA 2 模型架构
LLaMA 和 LLaMA 2 模型是基于原始 Transformers 架构的生成式预训练 Transformer 模型。我们在最初的 LLaMA 文章中详细概述了 LLaMA 模型与之前的 GPT 架构迭代的区别,但总结如下:
LLaMA 模型具有类似于预归一化的 GPT-3 功能。这有效地提高了训练的稳定性。在实践中,他们使用 RMS Norm 归一化函数来归一化每个变压器子层的输入而不是输出。这重新调整了不变性属性和隐式学习率适应能力LLaMA 使用 SwiGLU 激活函数而不是 ReLU 非线性激活函数,显着提高了训练性能借鉴 GPT-Neo-X 项目,LLaMA 在网络的每一层都具有旋转位置嵌入 (RoPE)。
正如 LLaMA 2 论文附录中所报告的,与原始模型的主要架构差异是增加了上下文长度和分组查询注意力 (GQA)。上下文窗口的大小增加了一倍,从 2048 个标记增加到 4096 个标记。更长的处理窗口使模型能够产生和处理更多的信息。值得注意的是,这有助于理解长文档、聊天历史和摘要任务。此外,他们还更新了注意力机制来处理上下文数据的规模。他们比较了原始的多头注意力基线、具有单个键值投影的多查询格式以及具有 8 个键值投影的分组查询注意力格式,以处理原始 MHA 格式的成本,其复杂性显着增加增加上下文窗口或批量大小。
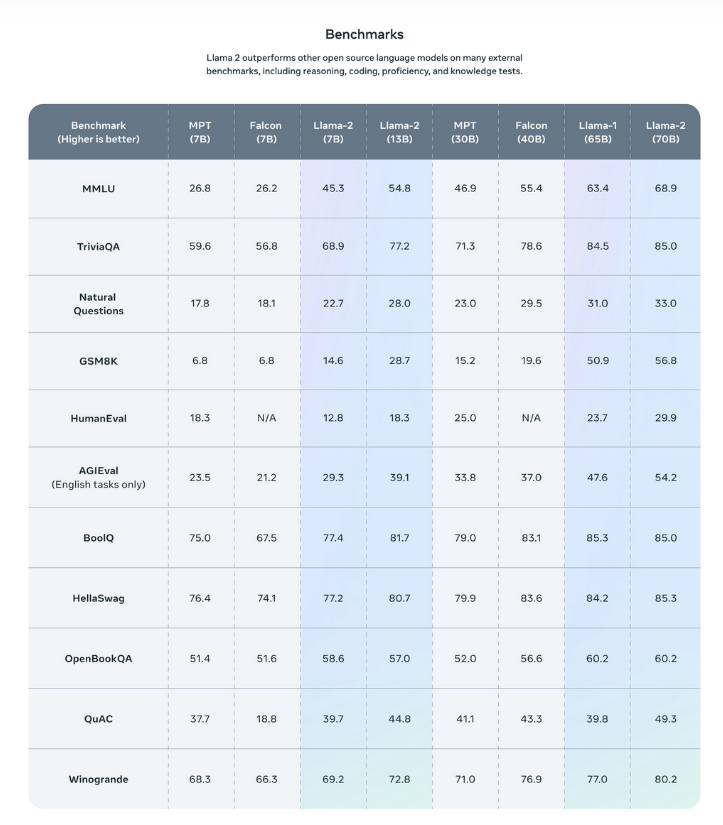
总之,这些更新使 LLaMA 在各种不同任务中的表现明显优于许多竞争模型。从 LLaMA 2 项目页面提供的上图可以看出,与 Falcon 和 MPT 等专用和替代 GPT 模型相比,LLaMA 的性能非常好或几乎一样好。我们期待在未来几个月内进行研究,展示它与 GPT-4 和 Bard 等大型闭源模型的比较。
更新的训练集
LLaMA 2 具有更新和扩展的训练集。据称,该数据集比用于训练原始 LLaMA 模型的数据大 40%。即使对于最小的 LLaMA 2 模型,这也具有良好的意义。此外,这些数据经过明确筛选,不包括来自显然包含大量私人和个人信息的网站的数据。
他们总共训练了 2 万亿个代币的数据。他们发现这个数量在成本效益权衡方面效果最好,并对最真实的来源进行了上采样,以减少错误信息和幻觉的影响。
聊天变体
Chat 变体 LLaMA 2-Chat 是经过数月的对齐技术研究而创建的。通过监督微调、RHLF 和迭代微调的融合,与原始模型相比,Chat 变体在 LLaMA 模型的人类交互性方面向前迈出了实质性一步。
使用与原始 LLaMA 模型相同的数据和方法进行监督微调 。这是使用“有用”和“安全”响应注释来完成的,当模型意识到或不知道正确的响应时,它们会引导模型做出正确的响应类型。
LLaMA 2 使用的 RHLF 方法涉及收集大量人类偏好数据,以供研究人员使用注释器团队收集奖励方法。这些注释者将评估两个输出的质量,并对这两个输出进行相互比较的定性评估。这使得模型能够奖励首选的答案,并对其赋予更大的权重,并对收到的不良答案进行相反的操作。
最后,随着他们收集更多数据,他们通过使用改进的数据训练模型的连续版本,迭代改进了之前的 RHLF 结果。
有关这些模型的聊天变体的更多详细信息,请务必查看论文。
可扩展至 700 亿个参数
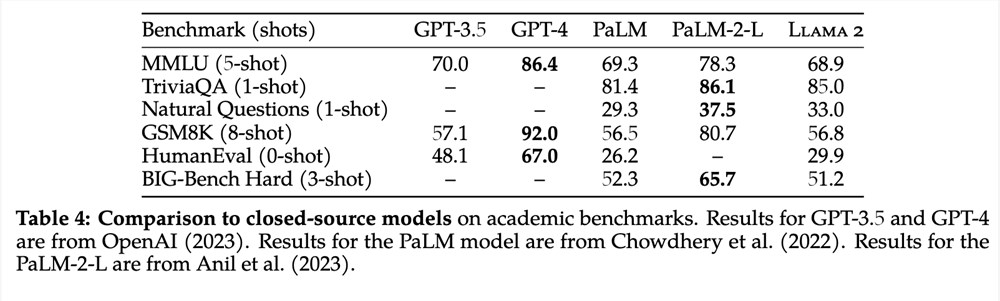
最大的 LLaMA 2 模型有 700 亿个参数。参数计数是指权重的数量,如 float32 变量中的权重数量,它被调整以对应于整个语料库中使用的文本变量的数量。因此,相应的参数计数与模型的能力和大小直接相关。新的 70B 模型比 LLaMA 1 发布的最大 65B 模型更大。从上表中我们可以看到,即使与 ChatGPT (GPT3.5) 等闭源模型相比,放大的 70B 模型也表现良好。它还有很长的路要走,以匹配 GPT-4,但来自开源社区的额外指令调整和 RHLF 项目可能会进一步缩小差距。
考虑到 ChatGPT 的训练规模为 1750 亿个参数,这使得 LLaMA 的成就更加令人印象深刻。
演示
现在让我们跳进渐变笔记本来看看如何在我们自己的项目中开始使用 LLaMA 2。运行此程序所需的只是一个 Gradient 帐户,这样我们就可以访问免费 GPU 产品。这样,如果需要,我们甚至可以扩展到在 A100 GPU 上使用 70B 模型。
我们将使用在基于 Gradio 的 Oogabooga 文本生成 Web UI 上运行的 GPTQ 版本来运行模型。该演示将展示如何设置笔记本、下载模型以及运行推理。
(点此可在免费 GPU 驱动的 Gradient Notebook 中打开此项目)
设置
我们将从设置环境开始。我们已经启动了我们的笔记本,并以 WebUI 存储库作为根目录。首先,让我们打开llama.ipynb笔记本文件。这包含我们在 Web UI 中运行模型所需的一切。
我们首先使用提供的文件安装需求requirements.txt。我们还需要更新一些额外的软件包。运行下面的单元格将为我们完成设置:
!pipinstall-rrequirements.txt!pipinstall-Udatasetstransformerstokenizerspydanticauto_gptqgradio
现在它已经运行了,我们已经准备好运行 Web UI 了。接下来,让我们下载模型。
下载模型
Oogabooga 文本生成 Web UI 旨在使 GPT 模型的运行推理和训练变得极其简单,并且它特别适用于 HuggingFace 格式的模型。为了方便访问这些大文件,他们提供了一个模型下载脚本,可以轻松下载任何 HuggingFace 模型。
运行第二个代码单元中的代码以下载 LLaMA 2 的 7B 版本以运行 Web UI。我们将下载模型的GPTQ优化版本,这可以显着降低使用量化运行模型的成本。
!pythondownload-model.pyTheBloke/Llama-2-7B-GPTQ
几分钟后模型下载完成后,我们就可以开始了。
启动应用程序
我们现在准备加载应用程序!只需运行 Notebook 末尾的代码单元即可启动 Web UI。检查单元格的输出,找到公共 URL,然后打开 Web UI 以开始。这将以 8 位格式自动加载模型。
!pythonserver.py--share--modelTheBloke_Llama-2-7B-chat-GPTQ--load-in-8bit--bf16--auto-devices
可以通过任何可访问互联网的浏览器从任何地方访问此公共链接。
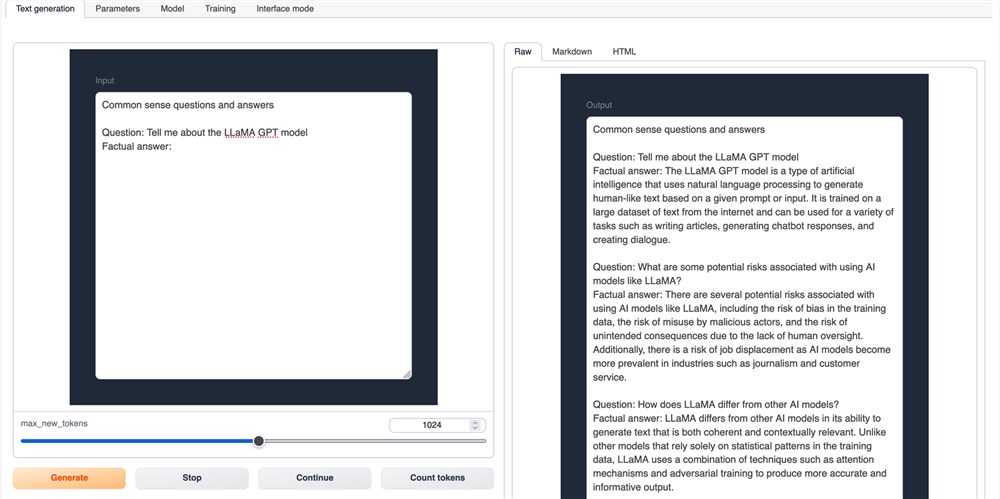
Web UI 文本生成选项卡
我们将看到的第一个选项卡是文本生成选项卡。我们可以在此处使用文本输入查询模型。在上面,我们可以看到 LLaMA 2 的聊天变体被询问一系列与 LLaMA 架构相关的问题的示例。
页面左下角有很多提示模板可供我们选择。这些有助于调整聊天模型给出的响应。然后我们可以输入我们喜欢的任何问题或说明。该模型将使用右侧的输出读取器将结果流式传输回给我们。
我们还想指出参数、模型和训练选项卡。在参数选项卡中,我们可以调整各种超参数以对模型进行推理。模型选项卡允许我们加载任何具有或不具有适当 LoRA(低阶适应)模型的模型。最后,训练选项卡让我们可以根据我们可能提供的任何数据训练新的 LoRA。这可用于在 Web UI 中重新创建 Alpaca 或 Vicuna 等项目。
结束语
LLaMA 2 是开源大型语言建模向前迈出的重要一步。从论文和他们研究团队提出的结果,以及我们自己使用模型后的定性猜想来看,LLaMA2 将继续推动LLM的扩散和发展越来越远。我们期待未来基于该项目并对其进行扩展的项目,就像 Alpaca 之前所做的那样。
- 0000
- 0000
- 0000
- 0000
- 0000