对话网易伏羲赵增:开源VS自研?哪条路是通向AIGC的捷径?|WAIC2023
从去年底到现在,国内外肉眼可见地涌现出了一批文生图公司,这背后与基础架构开源有很大关系。
2022年8月,Stability.AI在GitHub上公开开源了Stable Diffusion模型的代码和训练数据集;当月底,基于Stable Diffusion的图像生成工具Stable Diffusion web UI也正式开源发布。

(Stable Diffusion模型基本架构 图源:网络)
自此,以“Stable Diffusion”命名的“扩散模型”响彻了整个AIGC,在落地中形成了由文字编码器(Text Encoder)、图像信息生成器(Image Information Creator)和图像解码器(Image Decoder)组成的扩散模型架构,技术的核心是在去噪的过程中逐渐还原出图片。
开源的春风吹到了国内,也给了正在独自摸黑探索的中国文生图公司送去了光明。
“开源了,我们既兴奋,但又更迷茫了。”
技术方向更加明确了,训练路径也更加清晰,中国文生图公司又面临着一个新问题:要不要全面拥抱开源模型?
对于这个问题,网易伏羲和赵增团队也曾反复思考。
赵增的答案是,只能借鉴,不能全盘照抄。“模型训练不能开黑盒,只要做不到完全透明、可控,就存在风险。”
基于这个逻辑,网易伏羲走上了中国式文生图的道路,其基本模型架构为“自研 开源”相结合,平台做到了全中文输入、理解。
之前大模型因为不理解中文“闹了不少笑话”,而网易伏羲从模型训练开始便意识到了这个问题,在思考如何把文生图用得更好方面更快人一步。
如今,文生图迈入了更高效、更稳定、更自由可控的里程碑阶段,也衍生出图生图、图生3D、多图生视频等技术路径。
在围观了国外文生图应用的热闹景象之后,网易伏羲也走向了更深的自我思考和升级。
近期2023世界人工智能大会上,光锥智能对话网易伏羲预训练及生成式人工智能平台负责人赵增,聊一聊他对于爆火的文生图现象和背后技术的理解。
1、文生图的模型参数不是越大,效果就越好。
2、技术是标准化的,但审美是非标准化的,要想提升生成的美术效果,需要有美术专家介入,提供反馈。文生图的模型上限在专家,下限在技术。
3、借鉴国外开源模型固然可以提升生成技术,但一味地拥抱开源并不可取,其中存在许多可控性、安全问题,还是要构建自主的生成模型。
4、总体来看,文生图应用还处于探索时期,没有进入工业化落地阶段。
光锥智能:网易伏羲生成平台的探索过程是怎样的?近期有哪些新的进展?
赵增:2018年开始,网易伏羲就开始尝试用GPT去做模型应用适配。但随着OpenAI公司逐渐关闭对国内的技术访问路口,2020年,我们开始自己组织团队,以文本预训练为切入点去训练模型。
2021年之后,结合网易自身业务需求和互联网发展历程,我们判断多模态将是未来发展趋势,因而开始大力做多模态理解和生成。去年Stable Diffusion开源后,开始将自身的模型训练路线与开源架构相融合。
今年年初,文生图再次被推到风口,开源生态也异常活跃,在此背景下,我们对技术架构路径再次做了调整:一方面,持续优化自身的中文生成模型,希望其能在中文领域达到顶尖的效果;另一方面,去做更加友好开放的生产管线,将具有AI技术的人和专业艺术家都纳入生态系统。
最近我们内部也正在做预研2.0,在能力得到充分验证以后,也会更多地对外开放,融合到业务场景中、伏羲有灵美术平台中。
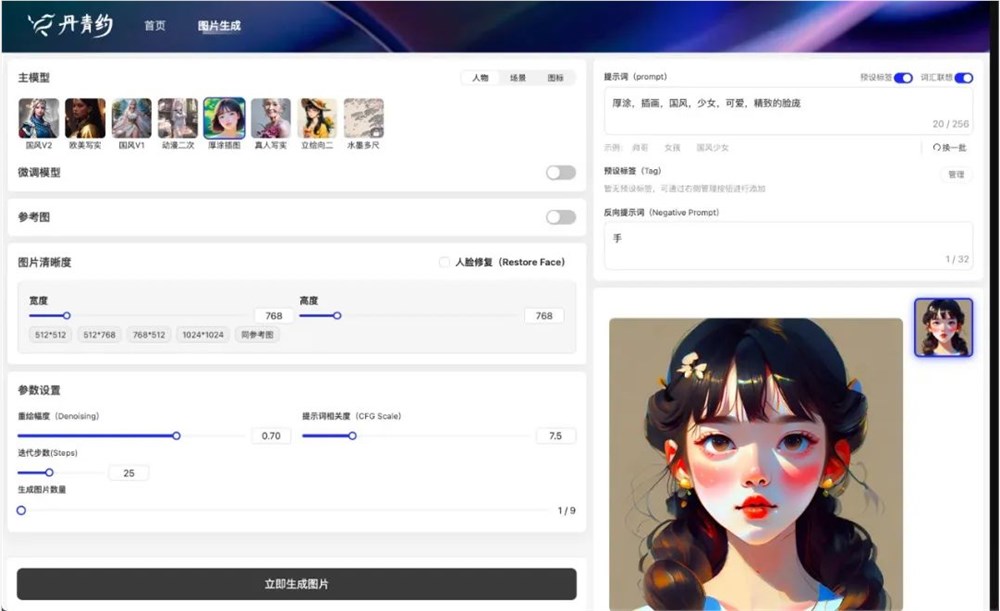
(AIGC绘画平台)
光锥智能:网易伏羲文生图大模型的参数是多少?
赵增:现在方案有很多套,有十几亿、三十几亿,也有几百亿的参数方案。一个很有趣的现象是,即使Stable Diffusion已经开源了多个版本,但现在最流行的还是早期的1.5版本,这就代表不是参数越大,效果就越好。我们的理念也是一样,会先尝试把数据变得越来越大,模型训练得越来越大,但也还会根据实际情况选择合适的尺寸去生成。
光锥智能:网易伏羲支持全中文操作,对比一些英中转换的模型,建立一个全新的中文语料库的难点在哪里?
赵增:最大的难点在于整个前期投入,就是要去系统性地构建高质量的中文数据集,然后喂给基础模型,从头去构建,不断地迭代,所以整个周期就会很长。我们的优势在于,起步比较早,在Stable Diffusion还没开源之前,我们就已经在不断地投入,到现在已经产生了很多积累。
光锥智能:如何在技术层面提升语义指导的精准程度,提升文生图的效果?
赵增:万变不离其宗。第一,在数据层面,要构建更符合用户输入内容的数据分布。在大模型背后的系统组件支持下,把这些数据更有效地串联和优化;
第二,在模型结构层面。我们在中文场景下做了很多调整,去尝试有效的结构,包括规模尝试。整体来讲,我们的模型结构跟开源模型结构不是完全一样的,无论是图片还是文本,都做了优化;
第三,是数据反馈。要获得有价值的评价,把干扰生成过程中的数据剔除掉,形成正向反馈机制,才能在训练过程中不断提高生成能力。

(AIGC生成的古风人物形象)
光锥智能:技术是标准化的,可是审美是非标准化的。网易伏羲在做文生图的时候,是怎样标准化生成结果?优化生成效果的呢?
赵增:反馈是很重要的,网易有非常多的顶尖的艺术家,他们会在使用过程中提供很多专业意见,帮助我们找到需要优化的点。我们也会把当前的版本发到伏羲有灵众包平台上,来获取用户匿名反馈。
举个例子,之前3月的时候,我们做了一款二次元模型,初步觉得效果不错,但美术专家一看,就说头身比不行、姿势不行,在他们的反馈之下,我们从模型数据层面做了重构,才调整过来。
这也给我们一个启示,从系统的层面我们只能去增加量,但是想要做顶尖的内容生成,就要有顶尖的审美,需要跟行业有深度的合作。我们和美工在内部分工很明确,模型的上限在他们,下限可能在我们技术上。

(AIGC生成的二次元形象)
光锥智能:除了审美,专家的介入还会提带来哪些反馈优化,可以举个例子吗?
赵增:主要基于他们的生产过程。
比如说处理图的时候,他们需要什么样的风格。如果是通用风格,例如二次元,我们就会把它做成基础模型;但是如果特别小众,例如厚涂,就做成二级模型,去开放自主仿真的能力,让专家自己去定制模型。
而在图生成以后,他们可能需要能在PS里自动分层的图片。还有,对于具体内容的理解,例如,专家们需要榫卯结构、中国古代盔甲......这就需要我们不断去构建相应的数据,根据已有范式,补充相应的内容。
光锥智能:网易伏羲有没有针对用户展开具体的用户画像分析,比如专业的、业余的等等。
赵增:目前,是希望服务专业生产。因为这部分用户离我们最近,我们最能知道他们想要什么,也能很明确的算出来,等到他们真正用起来以后,我们才能产生巨大的收益。
光锥智能:如何看待使用国外开源模型的问题?
赵增:我们内部对要不要直接拥抱开源的这个问题,做了很多次讨论,最后的答案是明确的:要构建自己的生成模型。
直接使用国外开源模型,存在几个非常大问题,首先是对生产能力可控性的把握。以文生图为例,从特征提取到真正拿来用,这中间还有很多环节,模型要怎样去理解一些非常领域化和中国化的内容变得很关键,如果直接调用国外模型肯定会出现水土不服。
另外,在跟进国外开源生态的过程中,我们发现,一些生成效果比较好的模型,背后其实是庞大数据在支持,如果技术不加以控制,就可能出现失控。其次是数据合规性问题。虽然技术没有国界,但事实证明现在生成的内容的确是有偏见的,我们需要保证最后生成的内容要符合实际生产需求。
总而言之,我们的目标是去构建更有中国特色的生成模型,对于这个生成模型,我们希望从底子上它就是可控的,所有构建过程都是白盒状态,模型、数据、工程框架优化、迭代演进等都是清晰透明化的,而不是只知道一个模型的版本号,开源后拿过来改改再用。
光锥智能:国外已经出现了几款爆款软件,进入大规模应用阶段。但目前在国内,这样的感知似乎不是很强烈。以您的观察来看,国内文生图应用发展到了什么阶段?
赵增:其实,无论国内外,我们认为现在文生图的应用基本都还处于探索阶段。因为以我们的标准来看,只有出现像Photoshop这样现象级的产品,能实现为整个行业去服务、产生巨大收益的时候,才算是进入一个工业化落地的阶段。
目前,短暂的体验型产品还远远不够。从纯图文层面来讲,现在的工具功能都是碎片化的,没有一个能够解决全流程的问题,我们的用户需要不断地在各个AI生产工具中切换,因此他们的支付意愿不高,对单个产品的依赖度也很低。
不过,虽然现在生产规模还在起点阶段,但各种从业人员包括高层都看到了图文的价值,还需要时间去探索如何规模化。
光锥智能:国外公司从文生图转向了文生视频,在文生视频方面,网易伏羲有做尝试探索吗?
赵增:文生视频我觉得是一个非常有价值的场景,但是从落地的角度来讲,还是需要持续投入,它的成熟度会比文本、图文更滞后一些。从技术难点看,它的数据量可能更大,需要处理前后帧的相关性。
- 0000
- 0000


 0000
0000- 0000
- 0000