这个新方法有点牛,无需数据训练就能改善Stable Diffusion
站长网2023-07-18 00:04:361阅
受到大型语言模型的微调的启发,研究人员现在正试图使用强化学习来微调生成AI模型以实现特定目标,例如提高图像的美学质量,从而干预这一过程。
最近,伯克利人工智能研究中心(BAIR)的研究人员使用强化学习来进一步优化生成式人工智能模型用于改善图像生成的效果。
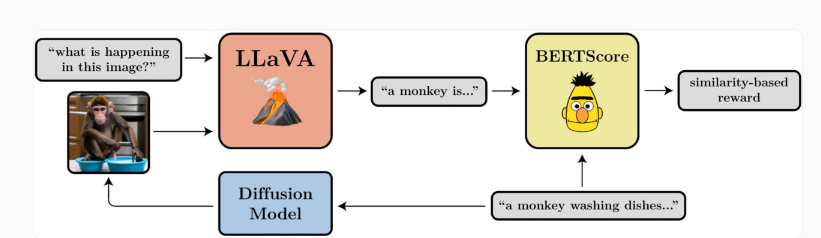
通过测试,他们发现去噪扩散策略优化(DDPO)在优化图像的压缩性、不可压缩性、美学质量和提示图像对齐方面表现出了有效性。
在他们的测试中,该团队表明DDPO可以有效地用于优化四个任务。此外,它们还显示出一定的可推广性:例如,对45种常见动物物种进行了美学质量或提示图像对齐的优化,但也可以转移到其他动物物种或无生命物体的表示上。

这种方法不需要训练数据,为基于人工智能的图像合成开辟了新的可能性,但仍需要进一步探索。
与强化学习中常见的一样,DDPO也表现出奖励过度优化的现象:该模型在某个节点之后破坏所有任务中所有有意义的图像内容,这个问题需要在进一步的工作中进行调查。
0001
评论列表
共(0)条相关推荐
- 0000
- 0000
- 0000
- 0000
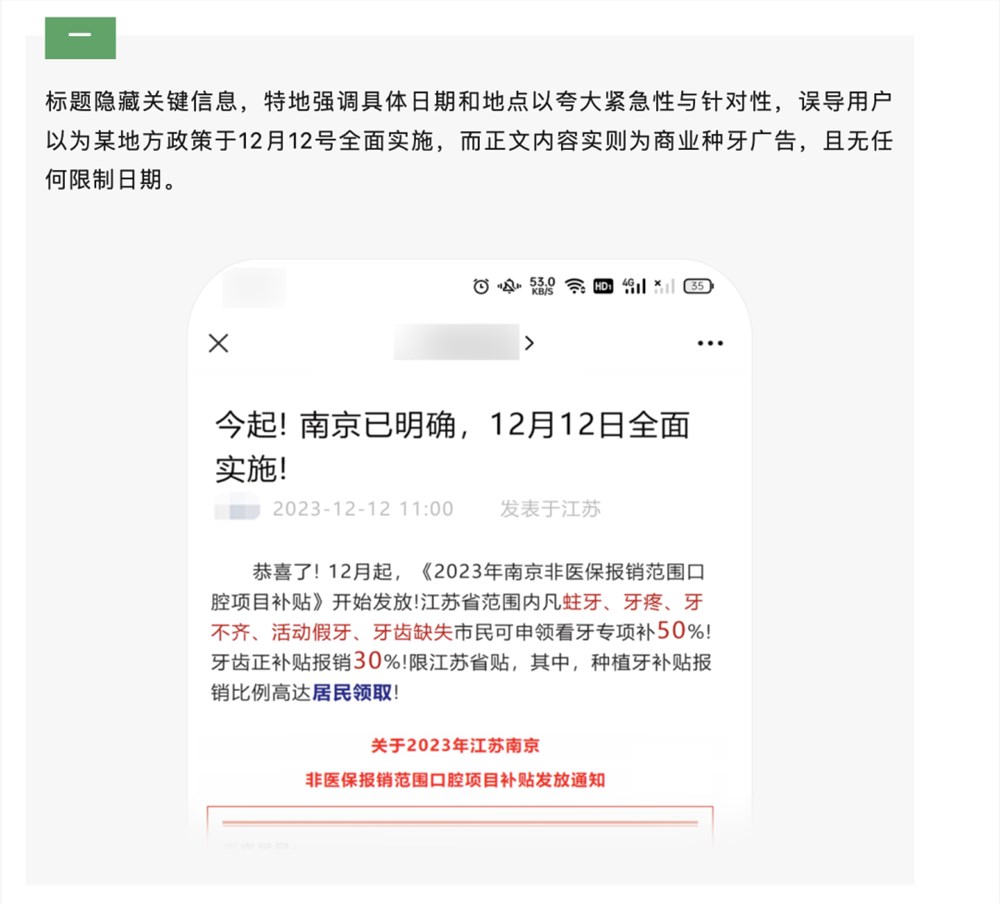

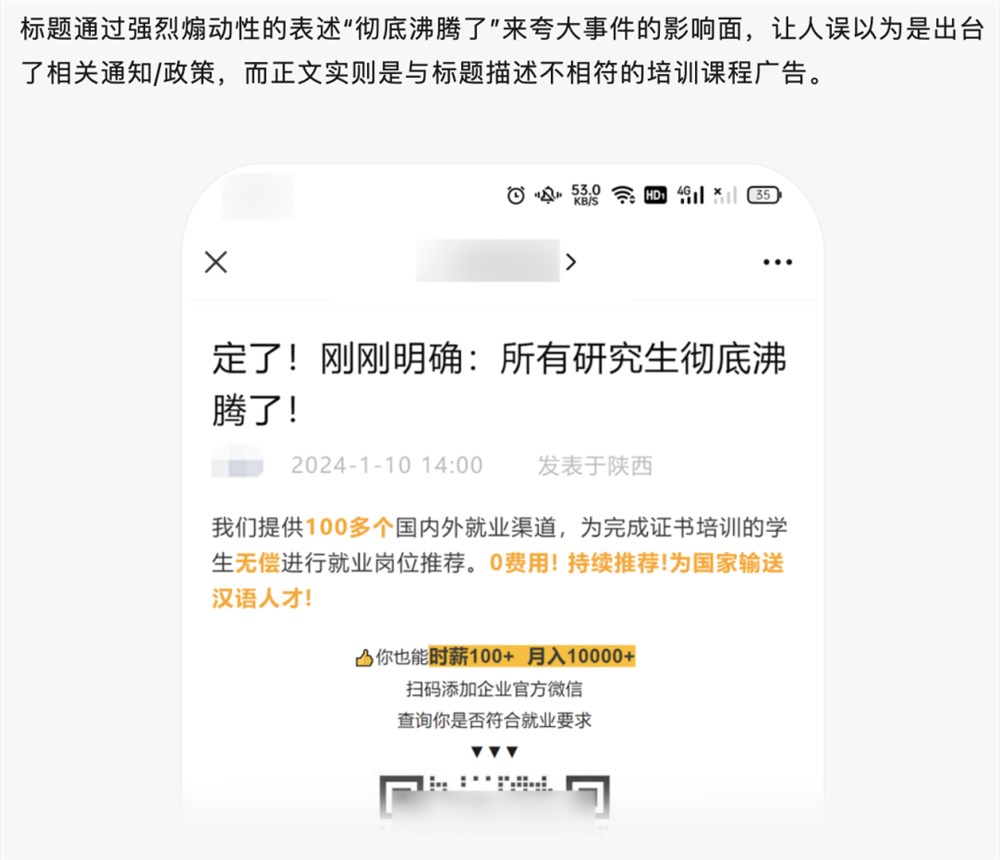 0000
0000
