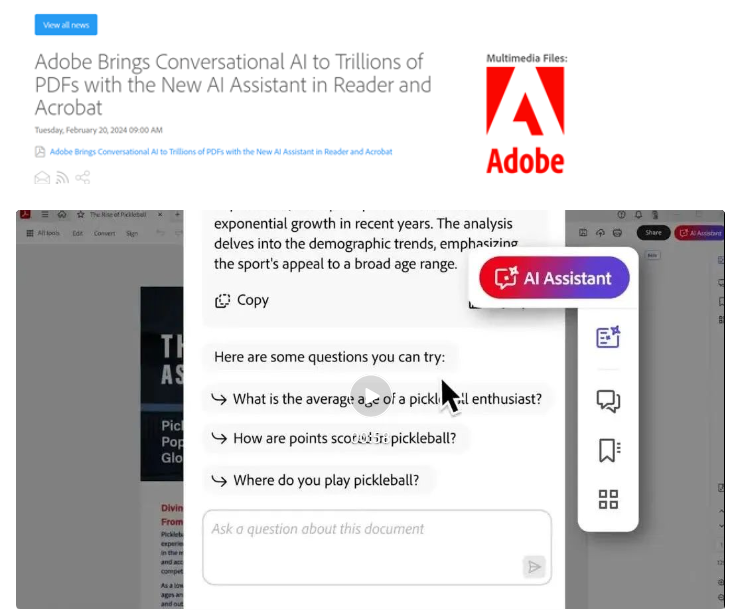
谷歌发布 MediaPipe Diffusion 插件 推理效率比ControlNet高20倍以上
谷歌最近发布了 MediaPipe Diffusion 插件,这是一个可在移动设备上运行的低成本可控文本到图像生成解决方案。该插件可以提取条件图像中的特征,并将其注入到扩散模型的编码器中,以实现对图像生成过程的控制。
与 ControlNet 相比,MediaPipe Diffusion 插件的推理效率提高了20 倍,在 v100上运行甚至可以提速高达100倍。
扩散模型是一种在文本到图像生成中取得成功的方法,它通过迭代去噪的方式逐步生成目标概念的图像。通过将文本提示作为条件,可以大大提高图像生成的效果。然而,仅凭文本来控制图像的生成往往难以获得理想的结果,例如具体的人物姿势和面部表情。
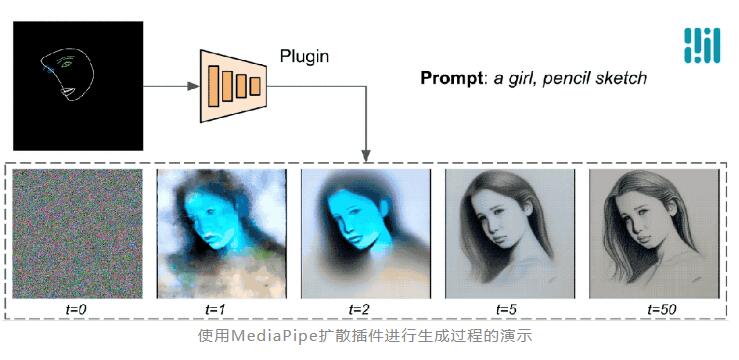
为了解决这个问题,谷歌研究人员设计了 MediaPipe Diffusion 插件,该插件是一个轻量级的模型,具有600万参数,使用 MobileNetv2中的深度卷积和反向瓶颈实现快速推理。
插件可以连接到预训练的文本到图像生成模型中,并提供额外的条件信号,从而实现对图像生成过程的控制。
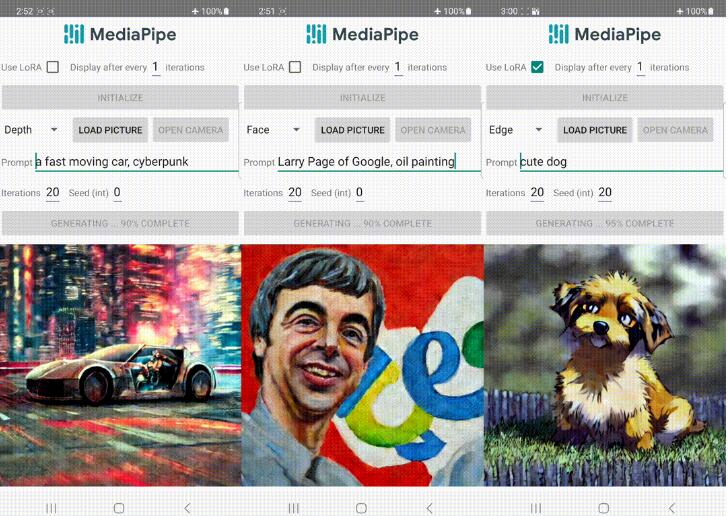
研究人员还开发了基于扩散的文本到图像生成模型与不同插件的应用示例,包括人脸标记、全身标记、深度图和 Canny 边缘。通过调节插件的参数,可以生成不同风格和特征的图像。
对于 face landmark 插件,研究人员进行了定量评估,并与 ControlNet 进行了比较。实验结果表明,插件生成的样本质量比基础模型好得多,而推理时间只增加了2.6%。此外,在移动设备上的性能测试中,MediaPipe 插件表现出明显的优势。
总之,谷歌的 MediaPipe Diffusion 插件是一个可在移动设备上运行的图像生成控制模型,可以提高推理效率并实现对图像生成过程的精确控制。这将为移动端应用提供更灵活和定制化的生成式 AI 能力。
- 0000
 0000
0000- 0000
 0000
0000- 0000


