微软 Azure 发布能跨多种模态生成内容的 CoDi 模型:同时处理和生成文本、图像、视频和音频
作为人工智能领域的一项显著进步,微软 Azure 认知服务研究中心和北卡罗来纳大学 NLP(自然语言处理)团队的研究人员日前推出了 CoDi,这是一种尖端的生成模型,能够跨多个领域无缝生成高质量内容。
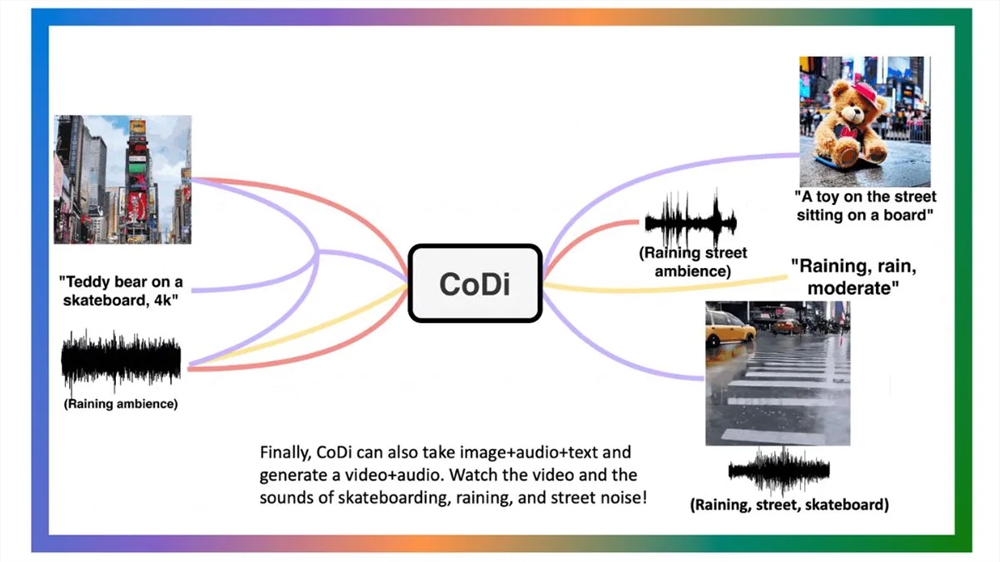
图片来自 Microsoft
这一突破性的发展为更全面地理解世界和人类理解提供了新的可能性,为沉浸式人机交互提供了平台,改变了人类与计算机的互动方式。
这篇名为《Any-to-Any Generation via Composable Diffusion(通过可组合扩散进行任意到任意生成)》的研究论文将 CoDi 引入作为一种创新的生成模型,能够同时处理和生成文本、图像、视频和音频等多种模态的内容。通过允许从不同输入模态的多样组合中进行协同生成内容,CoDi 在追求集成和可组合的多模态人工智能系统的过程中迈出了重要一步。
CoDi 的出现是微软雄心勃勃的 i-Code 项目的一部分,该项目致力于推进多模态人工智能能力的发展。凭借其无缝整合来自多种来源的信息并生成连贯输出的能力,CoDi 有望彻底改变人机交互的多个领域。
探索 CoDi 人工智能模型的实际应用
CoDi 在辅助技术领域具有变革性的潜力,使残障人士能够更有效地与计算机进行交互。通过在文本、图像、视频和音频等多种模态下无缝生成内容,CoDi 可以为用户提供更沉浸、更易访问的计算体验。
此外,CoDi 还有潜力通过提供全面互动的学习环境来重塑定制化学习工具。学生可以接触与各种来源整合的多模态内容,增强对学科的理解和参与度。
环境计算的概念,即技术与我们的日常生活无缝集成,也可以从 CoDi 的能力中获益匪浅。该模型能够即时生成多模态内容,为跨设备和环境的体验创造更加沉浸和个性化的体验,提升整体用户体验。
CoDi 也将彻底改变内容生成。该模型能够跨多种模态生成高质量的输出,从而简化内容创作流程并减轻创作者的负担。无论是生成引人注目的社交媒体帖子、制作互动多媒体演示,还是打造引人入胜的故事体验,CoDi 的能力有可能重塑内容生成领域的格局。
随着人工智能领域的不断进展,像 CoDi 这样的模型代表着多模态人工智能系统发展的重要里程碑。CoDi 能够无缝生成文本、图像、视频和音频的高质量内容,展示了打造更加身临其境、互联的人类人工智能未来的潜力。研究人员的工作使我们离释放人工智能在各个领域的全部潜力和彻底改变我们与计算机交互的方式又近了一步。
微软 CoDi 模型包含演示和代码的项目页面位于:codi-gen.github.io。
- 0000
- 0000


 0001
0001- 0001
 0000
0000

