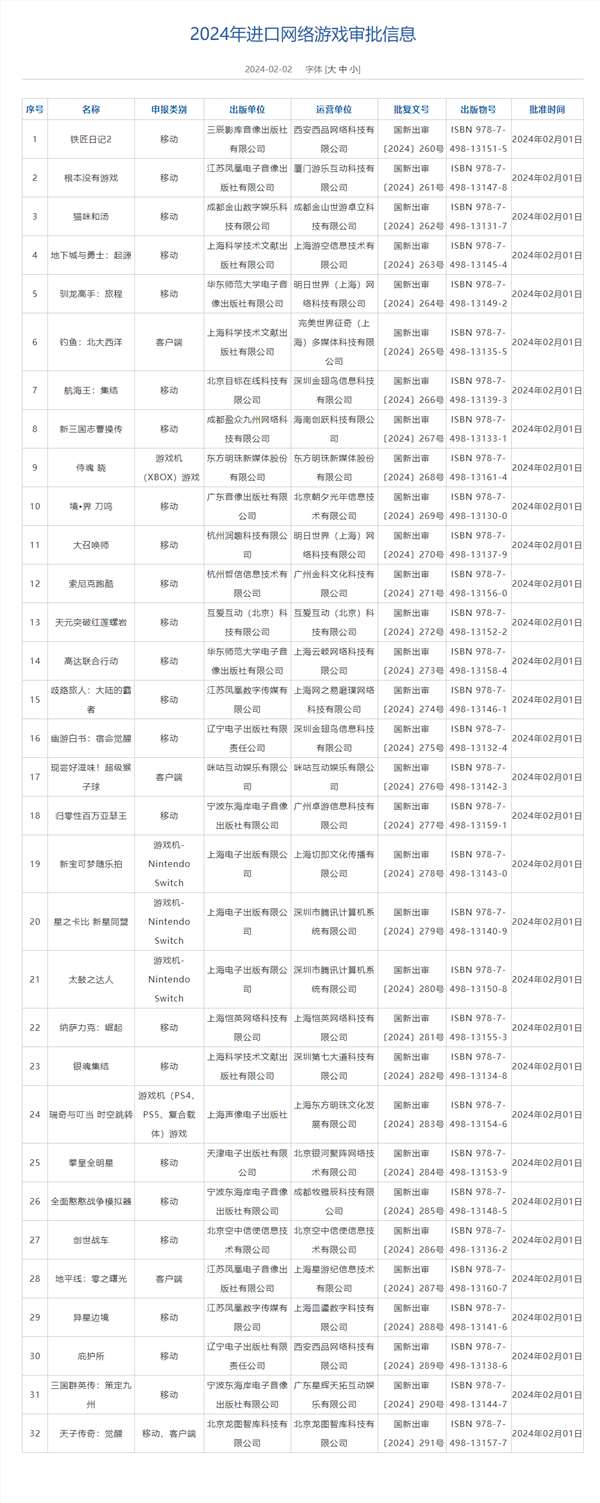
商汤国产中文大模型全面领先ChatGPT 部分接近GPT-4
快科技6月21日消息,在AI大模型领域,OpenAI的ChatGPT成为当前最火的大模型,也是标杆性的,多个国产大模型都要对标它,今天商汤科技公布了自己的大模型测试结果,三个测试项目中都超越了ChatGPT。
商汤科技自研中文语言大模型名为商量SenseChat 2.0”,日前公布的测试显示,MMLU、AGIEval、C-Eval三个权威大语言模型评测基准的成绩。
根据评测结果,商量SenseChat 2.0”在三个测试集中表现均领先ChatGPT,部分已十分接近GPT4的水平,实现了我国语言大模型研究的重要突破。
这三个测试分别如下:
由美国加州大学伯克利分校等高校构建的多任务考试评测集MMLU;
微软研究院推出的学科考试评测集AGIEval(含中国高考、司法考试及美国SAT、LSAT、GRE和GMAT等);
由上海交通大学、清华大学和爱丁堡大学合作构建的面向中文语言模型的综合性考试评测集C-Eval;

在MMLU测试中,商量SenseChat 2.0”综合得分为68.6,远超GLM-130B(45.7分)的得分,同时还超过了ChatGPT(67.3分)、LLaMA-65B(63.5分)仅落后GPT-4(86.4分),位居第二。
在AGIEval测试中,商量SenseChat 2.0”测出49.91的分数,遥遥领先GLM-130B(34.2分)、LLaMMA-65B(34.0分),并再次超越ChatGPT(42.9分),仅次于GPT-4的56.4分。
在其中的AGIEval(GK)评测子集中,商量SenseChat 2.0”以58.5分全面领先,仅微弱差距落后GPT-4(58.8分)。
在C-Eval测试中,商量SenseChat 2.0”拿到了66.1的分数,在参评的18个大模型中,仅次于GPT-4(68.7分),全面领先ChatGPT、Claude、Bloom、GLM-130B、LLaMA-65B等一众海内外大模型。
截至目前,已有近千家企业客户通过申请,应用和体验商量SenseChat 2.0”超强的长文本理解、逻辑推理、多轮对话、情感分析、内容创作、代码生成等综合能力,并且商量SenseChat 2.0”还在服务客户过程中,持续实现着快速迭代和提升,以及知识的实时更新。
- 0000

 0001
0001- 0000
 0000
0000- 0000