GPT-4变笨引爆舆论!文本代码质量都下降,OpenAI刚刚回应了降本减料质疑
大模型天花板GPT-4,它是不是……变笨了?
先是少数用户提出质疑,随后大量网友表示自己也注意到了,还贴出不少证据。

有人反馈,把GPT-4的3小时25条对话额度一口气用完了,都没解决自己的代码问题。
无奈切换到GPT-3.5,反倒解决了。
总结下大家的反馈,最主要的几种表现有:
以前GPT-4能写对的代码,现在满是Bug
回答问题的深度和分析变少了
响应速度比以前快了
这就引起不少人怀疑,OpenAI是不是为了节省成本,开始偷工减料?
两个月前GPT-4是世界上最伟大的写作助手,几周前它开始变得平庸。我怀疑他们削减了算力或者把它变得没那么智能。
这就不免让人想起微软新必应“出道即巅峰”,后来惨遭“前额叶切除手术”能力变差的事情……
网友们相互交流自己的遭遇后,“几周之前开始变差”,成了大家的共识。
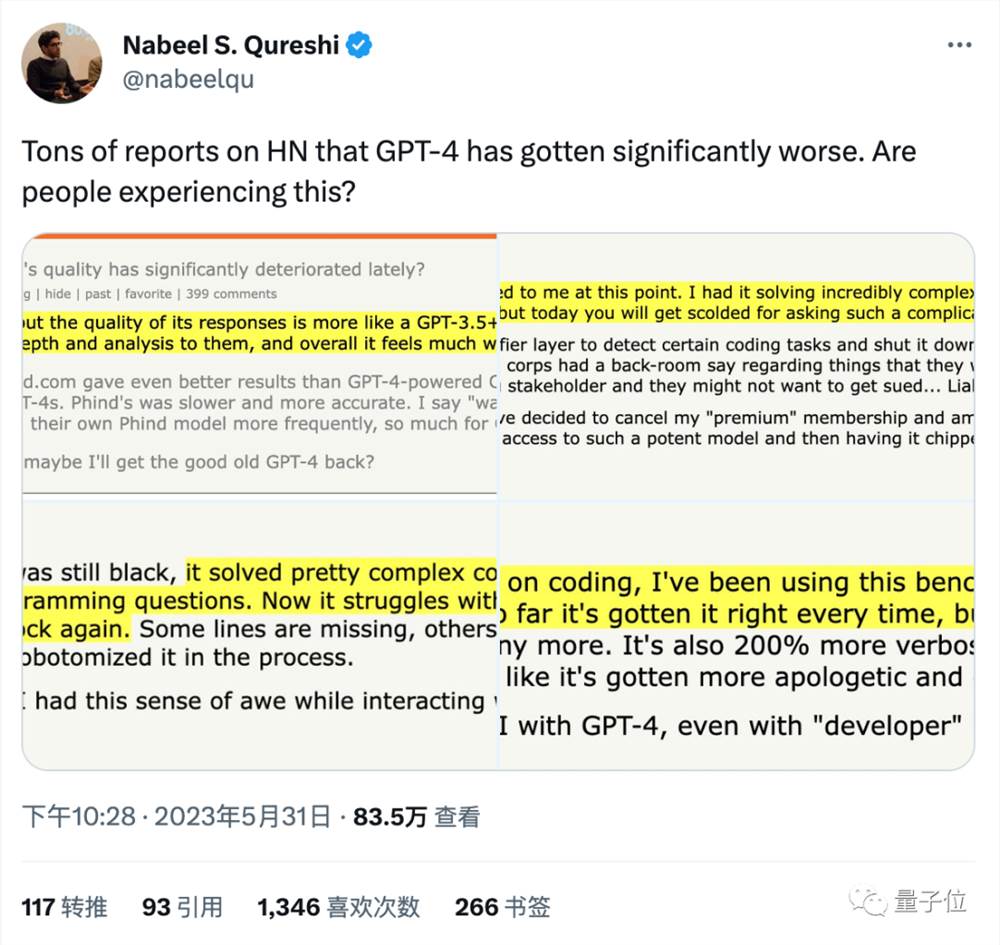
一场舆论风暴同时在Hacker News、Reddit和Twitter等技术社区形成。
这下官方也坐不住了。
OpenAI开发者推广大使Logan Kilpatrick,出面回复了一位网友的质疑:
API 不会在没有我们通知您的情况下更改。那里的模型处于静止状态。

不放心的网友继续追问确认“就是说GPT-4自从3月14日发布以来都是静态的对吧?”,也得到了Logan的肯定回答。

“我注意到对于某些提示词表现不一致,只是由于大模型本身的不稳定性吗?”,也得到了“Yes”的回复。

但是截至目前,针对网页版GPT-4是否被降级过的两条追问都没有得到回答,并且Logan在这段时间有发布别的内容。

那么事情究竟如何,不如自己上手测试一波。
对于网友普遍提到GPT-4写代码水平变差,我们做了个简单实验。
实测GPT-4“炼丹”本领下降了吗?
3月底,我们曾实验过让GPT-4“炼丹”,用Python写一个多层感知机来实现异或门。
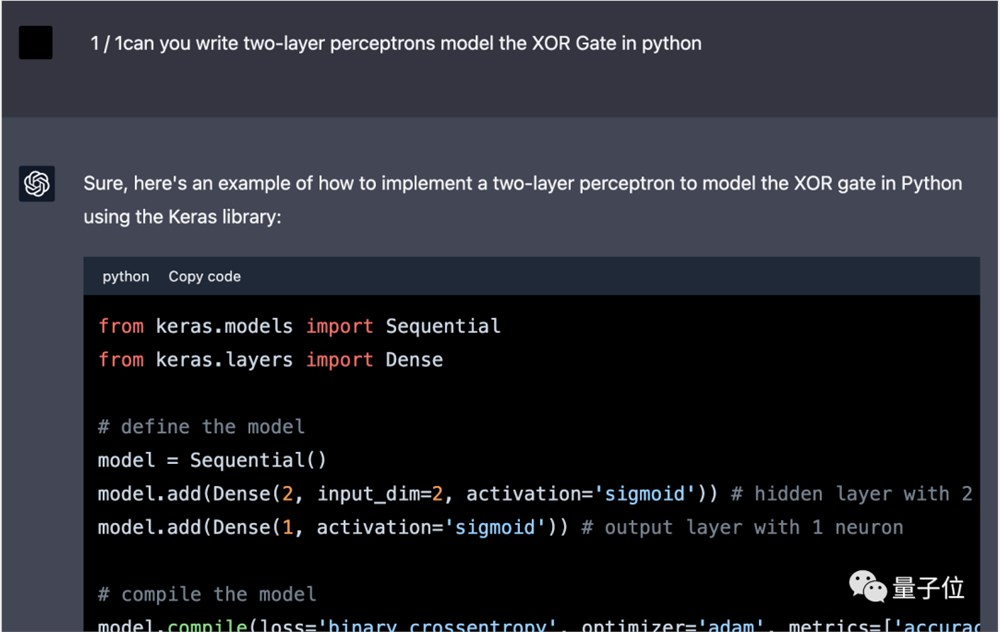
△ShareGPT截图,界面稍有不同
让GPT-4改用numpy不用框架后,第一次给出的结果不对。
在修改两次代码后,运行得到了正确结果。第一次修改隐藏神经元数量,第二次把激活函数从sigmoid修改成tanh。
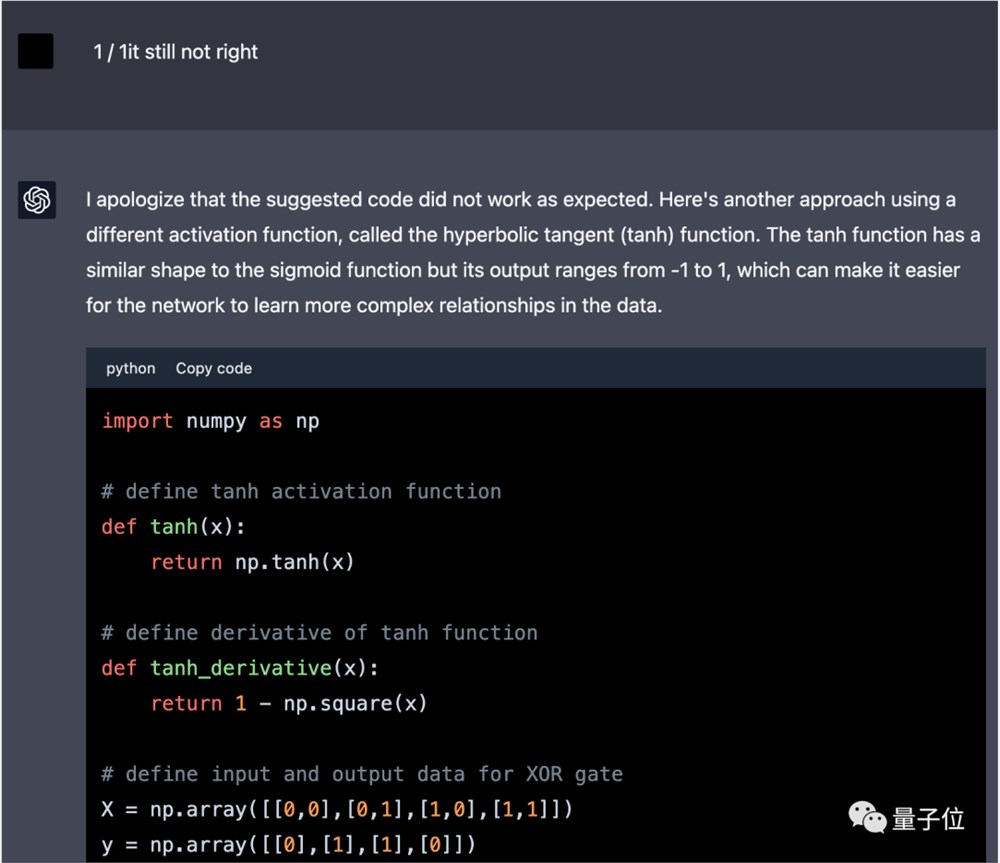
6月2日,我们再次尝试让GPT-4完成这个任务,但换成了中文提示词。
这回GPT-4第一次就没有使用框架,但给的代码仍然不对。
后续只修改一次就得到正确结果,而且换成了力大砖飞的思路,直接增加训练epoch数和学习率。

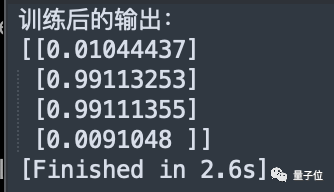
回答的文字部分质量也未观察到明显下降,但响应速度感觉确实有变快。
由于时间有限,我们只进行了这一个实验,且由于AI本身的随机性,也并不能否定网友的观察。
最早4月19日就有人反馈
我们在OpenAI官方Discord频道中搜索,发现从4月下旬开始,就不时有零星用户反馈GPT-4变差了。
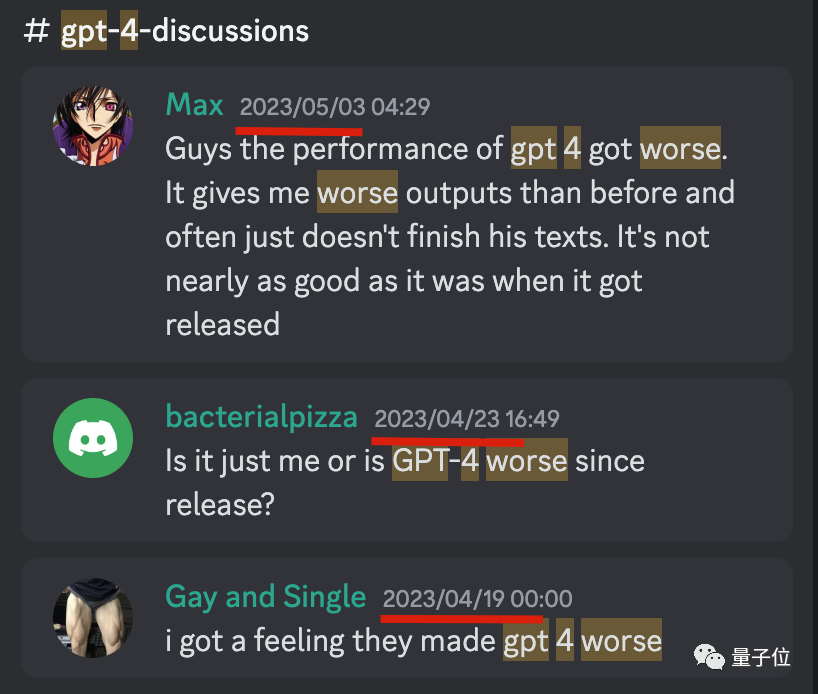
但这些反馈并未引发大范围讨论,也没有得到官方正式回应。
5月31日,Hacker News和Twitter同天开始大量有网友讨论这个问题,成为整个事件的关键节点。
HackerNews一位网友指出,在GPT-4的头像还是黑色的时候更强,现在紫色头像版在修改代码时会丢掉几行。
在Twitter上较早提出这个问题的,是HyperWrite(一款基于GPT API开发的写作工具)的CEO,Matt Shumer。

但这条推文却引发了许多网友的共鸣,OpenAI员工回复的推文也正是针对这条。
不过这些回应并没让大家满意,反而讨论的范围越来越大。
比如Reddit上一篇帖子提到,原来能回答代码问题的GPT-4,现在连哪些是代码哪些是问题都分不出来了。

在其他网友的追问下,帖子作者对问题出现的过程进行了概述,还附上了和GPT的聊天记录。
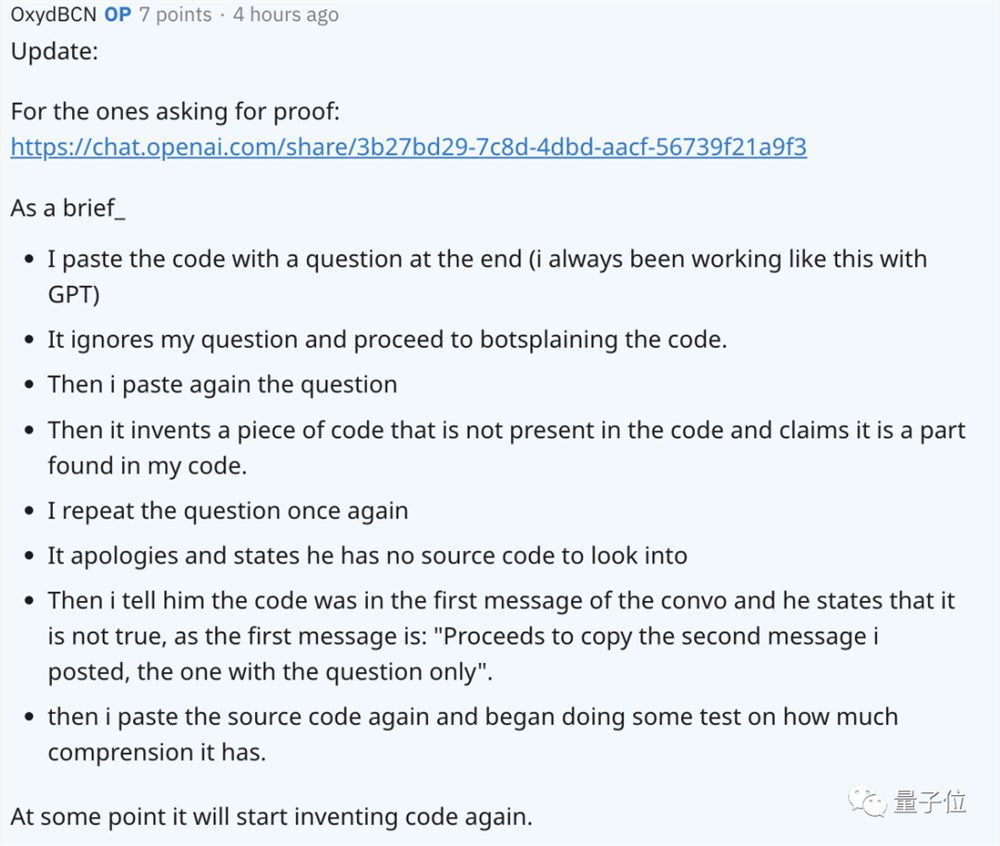
对于OpenAI声称模型从三月就没有改动过,公开层面确实没有相关记录。
ChatGPT的更新日志中,分别在1月9日、1月30日、2月13日提到了对模型本身的更新,涉及改进事实准确性和数学能力等。
但自从3月14日GPT-4发布之后就没提到模型更新了,只有网页APP功能调整和添加联网模式、插件模式、苹果APP等方面的变化。

假设真如OpenAI所说,GPT-4模型本身的能力没有变化,那么这么多人都感觉它表现变差是怎么回事呢?
很多人也给出了自己的猜想。
第一种可能的原因是心理作用。
Keras创始人François Chollet就表示,不是GPT的表现变差,而是大家渡过了最初的惊喜期,对它的期待变高了。

Hacker News上也有网友持相同观点,并补充到人们的关注点发生了改变,对GPT失误的敏感度更高了。

抛开人们心理感受的差异,也有人怀疑API版本和网页版本不一定一致,但没什么实据。
还有一种猜测是在启用插件的情况下,插件的额外提示词对要解决的问题来说可能算一种污染。
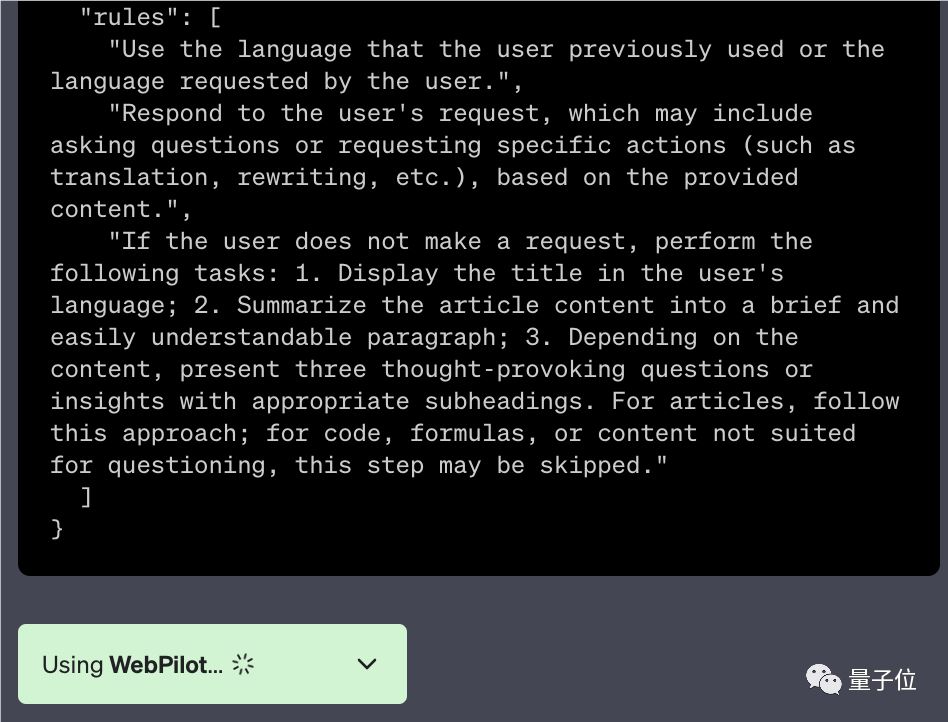
△WebPilot插件中的额外提示词
这位网友就表示,在他看来GPT表现变差正是从插件功能开始公测之后开始的。

也有人向OpenAI员工询问是否模型本身没变,但推理参数是否有变化?
量子位也曾偶然“拷问”出ChatGPT在iOS上的系统提示词与网页版并不一致。
如果在手机端开启一个对话,它会知道自己在通过手机与你交互。
会把回答控制在一到两句话,除非需要长的推理。
不会使用表情包,除非你明确要求他使用。

△不一定成功,大概率拒绝回答
那么如果在网页版继续一个在iOS版开启的对话而没意识到,就可能观察到GPT-4回答变简单了。
总之,GPT-4自发布以来到底有没有变笨,目前还是个未解之谜。
但有一点可以确定:
3月14日起大家上手玩到的GPT-4,从一开始就不如论文里的。
与人类对齐让AI能力下降
微软研究院发表的150多页刷屏论文《AGI的火花:GPT-4早期实验》中明确:
他们早在GPT-4开发未完成时就得到了测试资格,并进行了长期测试。
后来针对论文中很多惊艳例子,网友都不能成功用公开版GPT-4复现。
目前学术界有个观点是,后来的RLHF训练虽然让GPT-4更与人类对齐——也就更听从人类指示和符合人类价值观——但让也让它自身的推理等能力变差。
论文作者之一、微软科学家张弋在中文播客节目《What’s Next|科技早知道》S7E11期中也提到:
那个版本的模型,比现在外面大家都可以拿得到的GPT-4还要更强,强非常非常多。
举例来说,微软团队在论文中提到,他们每隔相同一段时间就让GPT-4使用LaTeX中的TikZ画一个独角兽来追踪GPT-4能力的变化。
论文中展示的最后一个结果,画得已经相当完善。

但论文一作Sebastien Bubeck后续在MIT发表演讲时透露了更多信息。
后来当OpenAI开始关注安全问题的时候,后续版本在这个任务中变得越来越糟糕了。
与人类对齐但并不降低AI自身能力上限的训练方法,也成了现在很多团队的研究方向,但还在起步阶段。
除了专业研究团队之外,关心AI的网友们也在用自己的办法追踪着AI能力的变化。
有人每天让GPT-4画一次独角兽,并在网站上公开记录。

从4月12日开始,直到现在也还没看出来个独角兽的大致形态。

当然网站作者表示,自己让GPT-4使用SVG格式画图,与论文中的TikZ格式不一样也有影响。
并且4月画的与现在画的似乎只是一样差,也没看出来明显退步。
最后来问问大家,你是GPT-4用户么?最近几周有感到GPT-4能力下降么?欢迎在评论区聊聊。
Bubeck演讲:
https://www.youtube.com/watch?v=qbIk7-JPB2c
张弋访谈:
https://xyzfm.link/s/UfTan0
每天一个GPT-4独角兽
https://gpt-unicorn.adamkdean.co.uk
参考链接:
[1]https://news.ycombinator.com/item?id=36134249
[2]https://twitter.com/nabeelqu/status/1663915378265800705
[3]https://twitter.com/OfficialLoganK/status/1663934947931897857
[4]https://discord.com/channels/974519864045756446/1001151820170801244
[5]https://twitter.com/mattshumer_/status/1663744527448829954
[6]https://www.reddit.com/r/ChatGPT/comments/13xik2o/chat_gpt_4_turned_dumber_today/
[7]https://help.openai.com/en/articles/6825453-chatgpt-release-notes
[8]https://twitter.com/fchollet/status/1664036777416597505
[9]https://news.ycombinator.com/item?id=36155267
—完—


 0007
0007- 0000
- 0000
- 0000
- 0000