日均tokens使用量超5000亿,AI生图玩法猛猛上新:豆包大模型为什么越来越「香」了?
2024年的 AI 图像生成技术,又提升到了一个新高度。
技术的飞速迭代,让这一领域的商业化落地进入加速阶段。前有 Midjourney v6史诗级更新,后有开源巨头 Stable Diffusion3独领风骚,而 DALL・E3背靠 ChatGPT 这棵「大树」,也收获了众多用户的关注。
当然了,在这条赛道上,来自国内的选手毫不逊色。
近日,国产大模型「顶流」—— 字节跳动豆包大模型,迎来一场集中放送:
在2024火山引擎 AI 创新巡展成都站活动上,豆包大模型团队公布了豆包大模型的最新进展,以及文生图模型、语音模型等垂直模型的新升级。
与此同时,豆包大模型家族的最新成员 ——「豆包・图生图模型」正式面世,一口气上新了50多项玩法。
作为国产大模型中的实力之作,豆包大模型在今年5月通过火山引擎正式对外提供服务。尽管入场时间不是最早,但今天的豆包大模型已经是国内使用量最大、应用场景最丰富的大模型之一。
这场活动中,火山引擎还透露了一个数字:截至2024年7月,豆包大模型的日均 tokens 使用量已经超过5000亿。
与此同时,豆包大模型的技术实力在短时间内也经历了多次迭代。在多个公开评测集以及专业的第三方评测中,豆包通用模型 pro 均表现出众,是得分最高的国产大模型。

至于豆包大模型的「功力」究竟练到了哪一层?我们不妨体验一把再下结论。
国产 AI 猛猛上新
豆包大模型为什么能俘获用户的心?
我们就从刚刚更新的图像生成方面来考验一下豆包大模型。对 AIGC 应用接触比较多的用户可能都有一个感受:AI 图像生成类产品越来越卷,彼此之间也越来越难拉开差距。
这种直观感受的变化,几乎能完全对应上底层技术的演进节点。与一些早期 GAN 模型的生成水准相比,如今的图像生成质量已经让大部分人觉得「真假难辨」。在这个过程中,学界和业界对图像生成质量的评估维度也发生了巨大变化:像 FID Score 这样的指标已经不足以全面反映模型能力,人类评估成为了评估图像生成质量的黄金标准。尽管经济和时间成本更高,但这种方式可以提供更加细微且可解释的感知反馈。
以「文生图」方向为例,现阶段的目标可以总结为对综合维度的全面提升,具体可拆分为图像美感、图文一致性、内容创造、复杂度适应性四个维度。在这几方面,豆包・文生图都达到了业界较高水准。
在用户感受最强烈的「图文匹配」维度上,豆包・文生图模型不断进化,比如很好地理解多数量主体、主客体关系、人物构造和空间构造等信息:
Prompt:古代日本鬼机甲、中国朋克、太空歌剧、科幻小说、古代未来主义、神秘、明亮、不对称密集构图、32k 超高清、电影光、气氛光、电影、柔和的调色板、超现实、自由度、自然体积光。

而在「画面效果美感」层面,豆包・文生图模型非常善于从光影明暗、氛围色彩和人物美感方面进行画面质感提升:
Prompt:OC 渲染,3D 设计,长发小女孩,人脸朝着镜头,中心构图,帽子上长满鲜花,轮廓清晰,面部细节放大,帽子细节放大,画质高清,超清画质,深景深,背景是花海

此外,作为国产 AI 精品之作,面对中国人物、物品、朝代、美食、艺术风格等元素,豆包・文生图模型也展现出了更加深刻的理解力。
Prompt:超写实画风,唐代,长安,元宵节夜市,唐代侍女,灯火辉煌,细节完美,特写,热闹非凡,超高清,4K

Prompt:国风水墨绘画,点彩、肌理磨砂、陈家泠、大面留白的构图,高清16k故宫远景,雪景、流畅建筑结构,层次,白色主色,淡雅

基于双语大模型文本编码器,豆包・文生图模型对英文 Pormpt 的理解同样精准:
Prompt:butterfly candle, in the style of y2k aesthetic, pop-culture-infused, jewelry by painters and sculptors, text and emoji installations, money themed, playful animation, humble charm
Prompt:World of Warcraft, outdoor scene, green grassland with a river flowing through it, rocky cliffside with a cave entrance, a small wooden bridge over the waterway, lush trees and wildflowers on both sides of the stream, white clouds in a blue sky, fantasy landscape concept art style, game illustration design, concept design for world building, concept art in the style of game illustration design,3D
不久之后,豆包・文生图模型还将升级到2.0版本。豆包视觉团队表示,新版本将比当前模型的生成效果有40% 的提升,对比当前版本,图文一致性和美感会有大幅提升。
与文生图略有不同,在图像美感和结构等因素之外,图生图更算是一种应用模型,质量评估更加关注「一致性」和「相似度」两个维度。豆包・图生图模型的能力涵盖「AI 写真」、「图像风格化」、「扩图 / 局部重绘」三个主要方向,共提供了50余种风格玩法。

「AI 写真」算是以图生图方向中使用频率非常高的一种玩法,豆包・图生图模型的一大亮点是高度还原人物特征,能够精准捕捉轮廓、表情、姿态等多维特征,轻松生成定制化写真:
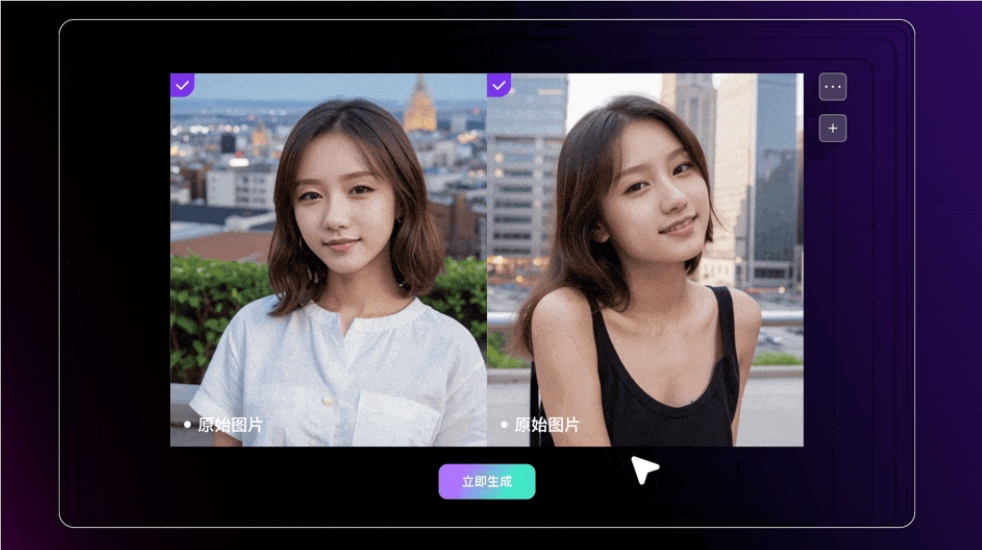
豆包・图生图模型还能具备优秀的图片扩展、局部重绘和涂抹能力,在逻辑合理的前提下,还能充满想象力。
比如在下方的任务中,用户想要实现自然的局部消除,豆包・图生图模型生成结果也做到了平滑过渡:

对于只想局部进行重绘的需求,豆包・图生图模型能够精准修改图像局部内容,无缝融合原有画面。比如将粉色外套改为蓝色牛仔外套:

面对下方的人物照背景扩图任务,豆包・图生图模型给出的结果,实现了良好的景观结构及光线保持:

豆包大模型,如何跻身图像生成赛道上游?
感受完这一波 Demo,我们好奇:是从什么时候开始,豆包大模型在图像生成方面有了这么深厚的实力?
两年前,Stable Diffusion 的横空出世,宣告了 AIGC 时代的正式开启。随后,AI 社区形成了巨大的迭代效应,基于各个版本 Stable Diffusion 开源模型的 AI 图像生成工具被迅速创造出来,不断刷新生成质量和速度的上限。
不到半年后,DiT 架构的提出,验证了 Scaling Law 在图像生成领域同样成立。越来越多的研究选择用 Transformer 替代传统的 U-Net,让扩散模型继承了其他领域的最佳实践和训练方法,增强了图像生成模型的可扩展性、鲁棒性和效率,还提高了对文字提示的理解能力和图像生成质量,有效增加了定制化、生成内容可控性方面的优势。
早在豆包大模型诞生前的几年,字节跳动就开始关注图像生成相关技术,近两年更是持续增加这方面的研发投入,保持着创新成果的高频产出。这也是为什么豆包大模型一经面世,就可以惊艳所有人。
Scaling Law 被验证带来的另外一个启示是,算力基础提升、训练数据增加、数据质量改善成为了图像生成模型能力提升的关键因素。在这些方面,字节跳动自研的豆包大模型在图像生成能力进化上具备天然优势。
但 Stable Diffusion 模型的训练和推理仍然是一个复杂且耗时的过程,比如,扩散模型在推理过程中天然存在的多步数迭代去噪特性会导致较高的计算成本。如何在提升生成质量的同时加快速度,成为了图像生成领域的关键问题。
豆包视觉团队提出了多项创新成果,从不同的维度尝试解决这个难题,并将这些成果开放给了 AI 社区。
一项代表性的成果是Hyber-SD,这是一种新颖的扩散模型蒸馏框架,在压缩去噪步数的同时可保持接近无损的性能,在 SDXL 和 SD1.5两种架构上都能在1到8步内生成中实现 SOTA 级别的图像生成。(https://huggingface.co/ByteDance/Hyper-SD)
另外一项研究SDXL- Lightning则通过一种名为「渐进式对抗蒸馏」(Progressive Adversarial Distillation)的创新技术,实现了生成质量和生成速度的双重提升:仅需短短2步或4步,模型就能生成极高质量和分辨率的图像,将计算和时间成本降低了十倍,而且能在实现更高分辨率和更佳细节的同时保持良好的多样性和图文匹配度。(https://huggingface.co/ByteDance/SDXL-Lightning)
同时,豆包视觉团队还提出了一个利用反馈学习全面增强扩散模型的统一框架UniFL。通过整合感知、解耦和对抗性反馈学习,这个框架不仅在生成质量和推理加速方面表现优秀,还在 LoRA、ControlNet、AnimateDiff 等各类下游任务中展现出了很好的泛化能力。(https://arxiv.org/pdf/2404.05595)
众所周知,Stable Diffusion 的核心功能是从文本生成图像,而 ControlNet、Adapter 等技术的融合,能够在保留部分图像信息的同时添加一些额外控制条件,引导生成与给定参考图像「相似」的结果。这些技术的融合演变出了我们今天见到的各项「图生图」功能,并进一步消除了 AI 图像生成技术的商用门槛。
在这方面,豆包视觉团队同样有深厚技术积累,仅今年就在国际计算机视觉顶会 CVPR 中发表了十多篇论文,提出了数十项相关专利。
针对图像Inpaint/Outpaint问题,豆包视觉团队提出了ByteEdit。关键创新包括三点:首先,增大训练数据量级,兼容自然图像输入、mask 输入、无 prompt 输入,让模型「看到」更多泛化场景;其次,引入一致性奖励模型,重点提升生成结果一致性,让希望填充的区域和非填充区域更加的和谐;然后,引入渐进式的分阶段对抗训练策略,在不损失模型性能条件下实现速度的提升。(https://byte-edit.github.io)
针对ID 保持,豆包视觉团队提出了PuLID,通过引入一个新的训练分支,在训练中加入了对比对齐损失和更精确的 ID 损失,让 ID 适配器学习如何在注入的 ID 信息的同时,减少对原模型行为的破坏,从而在保证较高 ID 相似度的同时,兼顾编辑能力、风格化能力以及画面质量等方面的效果。(https://www.hub.com/ToTheBeginning/PuLID)
针对IP 保持,豆包视觉团队提出了一种「参考图 IP - 文本」解耦控制的通用场景 IP 定制化生成方法RealCustom,对于任意开放域物体或人物 IP 均可实现无需微调的实时定制化生成。(https://corleone-huang.github.io/realcustom/)
「更强模型、更低价格、更易落地」
短短两年内,AI 在图像生成上的持续进步,打破了长期存在的专业门槛,让任何人都可以创造出高质量的视觉作品,带来了一场前所未有的革命。豆包大模型的图像生成能力,已经为字节跳动旗下多个应用提供技术支持,包括抖音、剪映、醒图、即梦、豆包、星绘。对于大众来说,AIGC 已经实实在在地改变了生活。
但从企业用户的角度来说,这些最前沿的技术仍然存在一些应用壁垒,涉及数据、人才、算力等多方面因素。对于各行各业的用户来说,即使有了强大的开源模型可供选择,也需要解决计算资源、专业知识、模型微调等方面的挑战。
成本的全方位降低,才是推动大模型真正实现价值创造的关键因素。
自发布以来,豆包大模型正在通过火山引擎源源不断地向千行百业输出技术能力,推动大模型技术实现更广泛深入的行业落地。
目前,包括豆包・文生图模型和豆包・图生图模型在内,豆包大模型家族的成员数量已经达到了10个。这些针对应用场景细分的模型都会上线火山方舟,开放给火山引擎的众多企业客户合作共创。
飞速增长的使用量,也在帮助豆包大模型持续打磨自身能力。自2024年5月15日豆包大模型发布至今,短短两个月内,平均每家企业客户的日均 tokens 使用量已经增长了22倍。
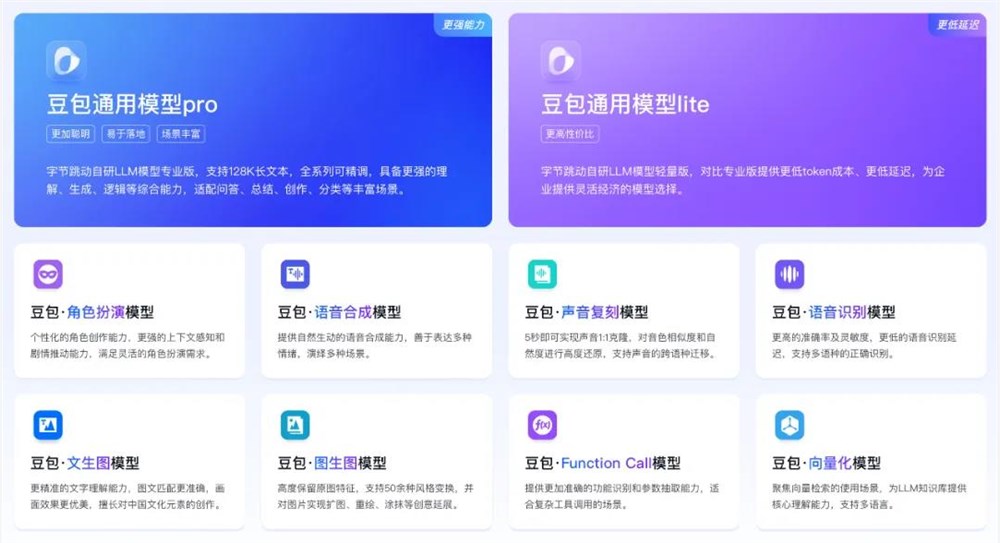
豆包大模型家族「集体照」。
同时,火山引擎提供了更丰富的核心插件、更强大的系统性能以及更优质的平台体验,企业可根据自身业务场景需求灵活选择、快速落地。比如,依靠豆包・图生图模型,客户利用几张图片即可训练专属的数字分身。
在很多情况下,价格仍然是客户的首要考虑因素。火山引擎正是率先将最强模型版本降价的行业先行者,以更强模型、更低价格满足企业复杂业务场景需求,真正推动大模型落地。
凭借充沛 GPU 算力资源池,并通过潮汐、混部等方式,实现资源的高利用率和极致降低成本,即使是在大模型价格战越来越激烈的未来,火山引擎所提供的大模型服务仍然保持着绝对吸引力。
中国公司正在开启大模型竞争的下一章
轰轰烈烈的百模大战之后,海内外的大模型快速涌现。尽管有 OpenAI 等一系列强大的竞争对手,但豆包大模型还是杀出了自己的一条路。
过去一段时间,人们喜欢谈论国产大模型技术的追赶。从「追赶」到「媲美」,很多中国团队只用了一年、半年时间,这其中也包括豆包大模型团队。
短时间内跻身图像生成这条赛道的上游,与豆包大模型团队在研发和人才方面的投入密不可分。近几年,越来越多顶尖大模型人才的加入,纯粹极致的技术研究氛围,大规模的研发资源投入,都是成就豆包这一国产大模型代表作的重要因素。
特别是在应用场景优势的加持下,当大模型被「用起来」的这天,人们看到了中国大模型走进千行百业时的充足「后劲」。
可以期待的是,大模型这条赛道的竞争正在开启新篇章,而在新的章节里,国产大模型将有机会书写更加浓墨重彩的一笔。
- 0000
- 0003
 0000
0000- 0000
- 0001