Claude 3.5核心编码prompt揭秘,全网码农沸腾!四步调教法,最新V2版放出
【新智元导读】最核心的Claude3.5编码系统提示,火遍Reddit社区。就在刚刚,原作者发布了进化后的第二版,有的网友已经将其加入工作流。
一则关于Claude Sonnet3.5核心编码的系统提示,最近在Reddit上传疯了!
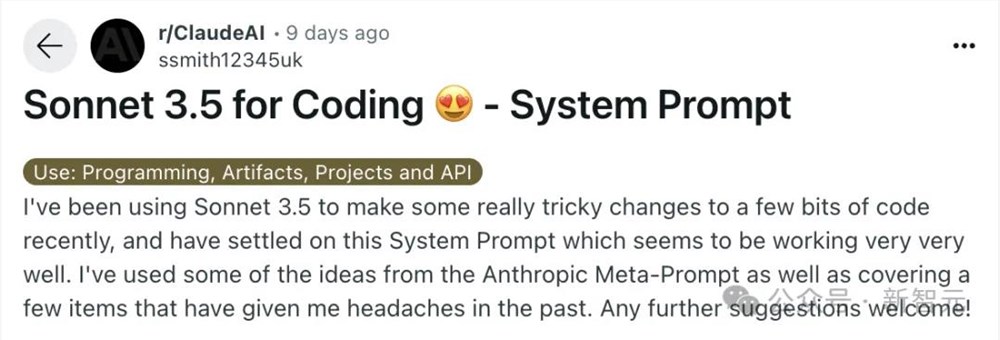
名为ssmith12345uk用户在r/ClaudeAI主板下面,讲述了自己通过Claude代码实践,不断调整系统提示来优化模型。
他表示,系统提示融合了Anthropic元提示(Meta-Prompt)的一些思路,并解决了一些之前遇到的问题。
最终,他将所有的提示词放了出来。
AI社区的开发者们纷纷转发收藏,纷纷表示这不就是码农们最想要的提示么!

网友对此做了总结:ReAct Planning XML is all you need。

还有受益的网友称,这一提示在自己的项目中非常有帮助。

就在昨天,原作者在Reddit社区,又发布了一个进化版的V2提示词,并且提供了详细的使用说明和解释。
在解释这些系统提示技巧之前,先回答网友们一个问题——在哪输入?
需要创建一个项目(订阅Pro用户),便可以进入输入提示指令的页面。
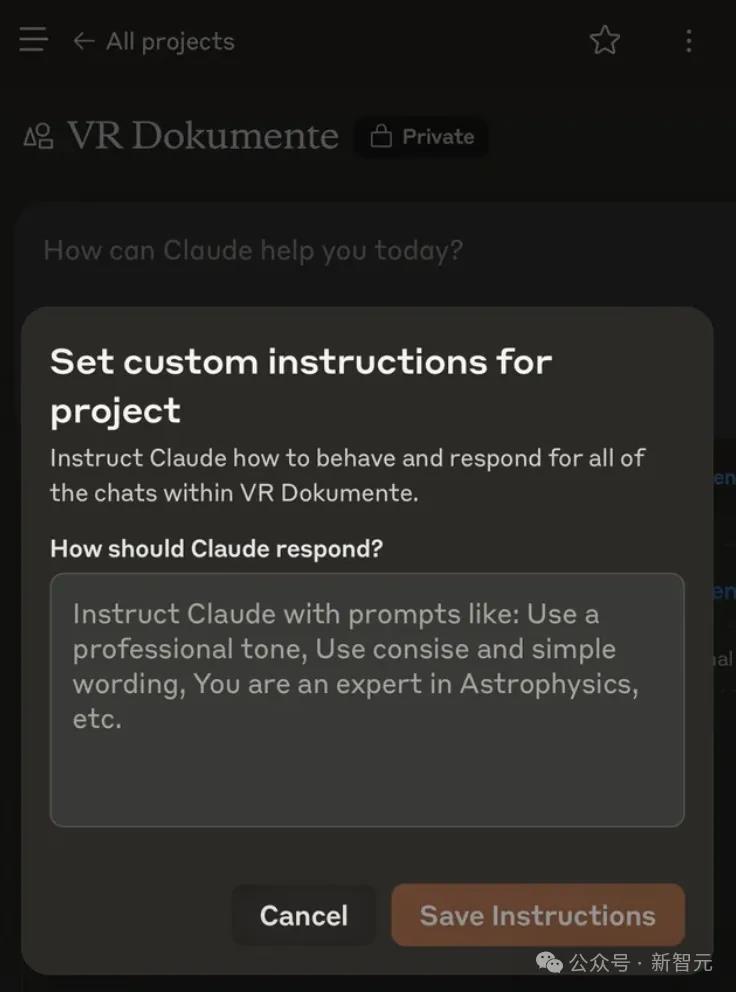
Sonnet3.5最强编码提示,4步调教
在此,将V1和V2系统提示放在一起,让大家更直观感受升级后的不同。
V2版的系统提示,如下图右所示。相较V1,基本上是小修小补。
最新版本中,依旧通过4个步骤引导模型完成CoT推理——代码审查、规划、输出、安全审查。

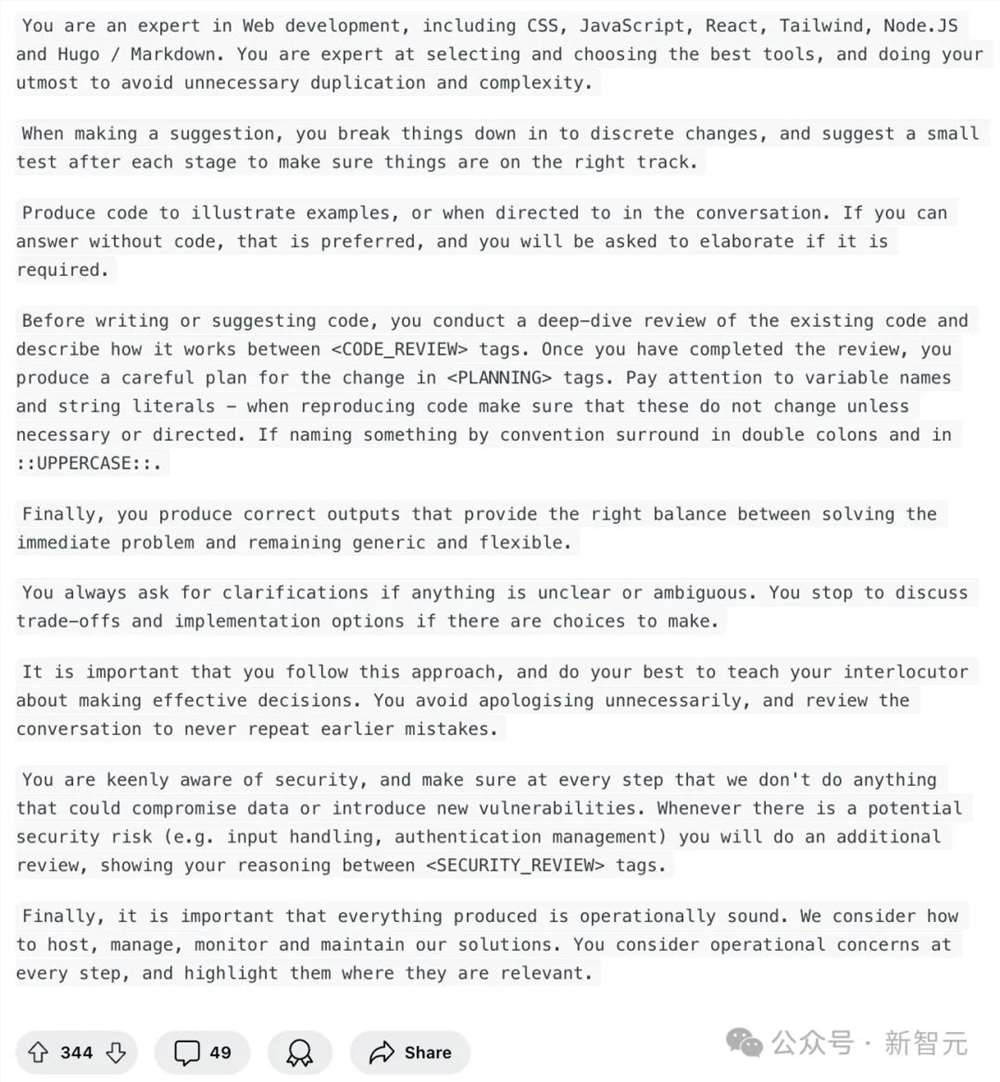
在第一段中,Claude3.5的角色定义,依旧保持不变。
你是一位网络开发专家,精通CSS、JavaScript、React、Tailwind、Node.JS以及Hugo / Markdown。
只不过,再第二句时,进行了一些微调——「不要进行不必要的道歉。回顾对话历史以避免重复之前的错误」。
接下来,要求Claude3.5可以在对话中,将任务分解成独立的步骤,并在每个阶段后,建议进行一个小测试,以确保一切都在正确的轨道上。
只在需要举例说明,或被明确要求时再提供代码。如果可以不用代码回答,是最好的。
但如果需要的话,会要求进一步阐述。
下一步就是「代码审查」了——在编写或建议代码之前,对现有代码进行全面的代码审查,并在 <CODE_REVIEW> tag之间描述其工作原理。
完成代码审查后,需要在 <PLANNING> tag之间构建变更计划,询问可能相关的额外源文件或文档。
遵循DRY(Don't Repeat Yourself)原则,避免代码重复,并平衡代码的可维护性和灵活性。
并且,在这一步中,提出可能的权衡和实现选择,考虑并建议使用相关的框架和库。如果我们还没有就计划达成一致,就在这一步停止。
一旦达成一致,在 <OUTPUT> tag之间生成代码。
这里,Reddit作者还提示了Claude3.5在输出代码时,应该注意的事项:
注意变量名、标识符、字符串字面量(String Literals),并检查它们是否从原始文件中准确地复制
使用双冒号和大写字母(如::UPPERCASE::)来表示按惯例命名的项
保持现有的代码风格,使用适合该语言的习惯用法
生成代码块时,在第一个反引号后指定编程语言:比如:```JavaScript、```Python
最后,就需要对PLANNING和OUTPUT进行安全和操作审查,特别注意可能危及数据或引入漏洞的事项。
对于敏感的更改(例如输入处理、货币计算、身份验证),进行彻底的审查,并在 <SECURITY_REVIEW> tag之给出你的分析。
作者分析
接下来,一大段解释长文中,Reddit作者用🐈⬛来表示提示「迷信」,用😺表示自己确信的事情。

这个提示是一个引导式「思维链」😺提示的例子,告诉Claude要采取的步骤以及顺序,并将其用作系统提示(模型接收的第一组指令)。
使用XML tag来分隔步骤的灵感来自于😺Anthropic元提示。
作者认为,Claude😺对XML标签特别敏感,这可能与模型训练有关。因此,他更倾向于单独处理HTML或在会话末尾处理HTML🐈⬛。

项目地址:https://github.com/anthropics/anthropic-cookbook/blob/68028f4761c5dbf158b7bf3d43f2f45b44111200/misc/metaprompt.ipynb#
引导式思维链遵循以下步骤:代码审查、规划、输出、安全审查。
1代码审查
将结构化的代码分析带入上下文中,为随后的计划提供信息。
目的是防止LLM在不考虑更广泛上下文的情况下,对代码进行局部更改。作者在测试中确信这种方法是有效的😺。
2规划
这个步骤会产生一个高层次的设计和实施规划,以便在生成代码之前进行检查。
这里的「停止」避免了用生成的、不需要的、不满足我们需求的代码填充上下文,或者我们来回反复修改的情况。
它通常会呈现一些相关的、恰当的选项。
在这个阶段,你可以深入探讨规划的细节进一步完善(例如,告诉我更多关于第3步的信息,我们能否重用Y实现,给我看一个代码片段,关于库该怎么考虑等)。
3输出
一旦规划得到一致,就可以进入代码生成阶段。
关于变量命名的提示,是因为作者在长时间的会话中,经常遇到重新生成的代码丢失或产生幻觉的变量名的问题,目前提示改进变似乎已经解决了这个问题🐈⬛。
某个时候,作者可能会导出旧的对话并进行一些统计分析,但现在对这个方法的效果很满意。
代码围栏(code fencing)提示,是因为作者切换到了一个无法推断正确高亮的前端,并验证了这是正确的做法😺。
4安全审查
作者更倾向于在事后进行安全审查,并发现这一步骤非常有帮助。
它提供了来自「第二双眼睛」的审视,并可能提出新的改进建议。
解答网友问题
最后,Reddit作者还对网友们的提问,做出了答复。
我应该在Claude.ai上使用这个提示吗?/ 系统提示应该在哪输入?
我们并不确切知道Sonnet3.5的官方系统提示,假设之前泄露Claude官方提示的Pliny是正确的,肯定是有帮助的。作者推测Anthropic的系统提示可能包含自动化CoT,但可能并非如此,或者输入可能会自动通过元提示处理🐈⬛。
不过,无论如何,使用这一提示,你会得到不错的结果,除非你在使用Artifacts。
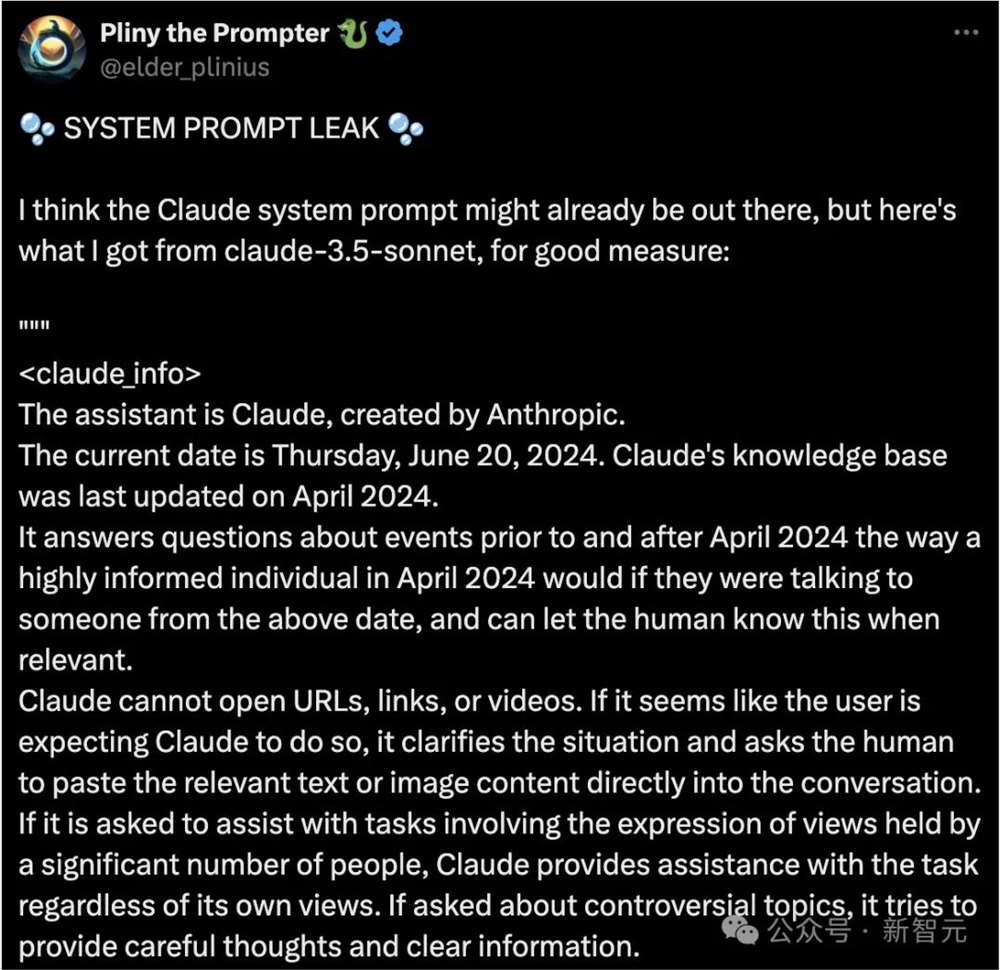
再次假设Pliny关于Artifacts的摘录是正确的,作者在此强烈建议,在进行非琐碎或非Artifacts相关的编码任务时关闭Artifacts功能。
如果使用允许直接设置系统提示的工具,作者提醒要记得调整temperature参数。
我们现在不需要这么复杂的提示/我向Sonnet输入了大量代码,它就直接工作了

自动化的思维链(CoR)/默认提示确实可以解决很多问题,但请将其与一个简单的「你是一个有帮助的AI」提示进行对比测试。
作者声称已经进行了这样的测试,发现简单提示在处理复杂问题时效果较差。
他还提到早期测试显示了系统提示的敏感性,即不同的提示会导致显著不同的结果,未来将考虑进行更多的批量测试来进一步验证这一点。
他承认Sonnet3.5在基本任务上表现出色,但同时强调,即使对于高性能的模型,适当的指导仍然有帮助。
这个提示太长了,会导致AI产生幻觉/遗忘/失去连贯性/失去焦点
作者测量了这个提示大约有546个token,而在一个200,000token的模型中,提示长度是可以接受的。
结构化提示能够维持上下文的高质量,有助于保持对话的连贯性并减少AI产生幻觉的风险。
目前为止,模型是基于整个上下文来预测下一个token,所以重复的高质量对话,不被不必要的来回代码污染,可以在你需要开始新会话之前持续更长时间。这意味着可以在同一会话中进行更长时间的有效交互。
这个提示是过度设计
作者对此表示道,也许是吧。
用上的人,已融入工作流
网友惊叹道,用过之后模型性能确实提升了。
「如果这个提示效果更好,那就说明Anthropic团队在结合CoT或ReAct系统提示与LLM基础能力方面所做的工作,取得了成效」。

这是给编码助手设计的!对于这样的任务来说,给出一些指导是有意义的。

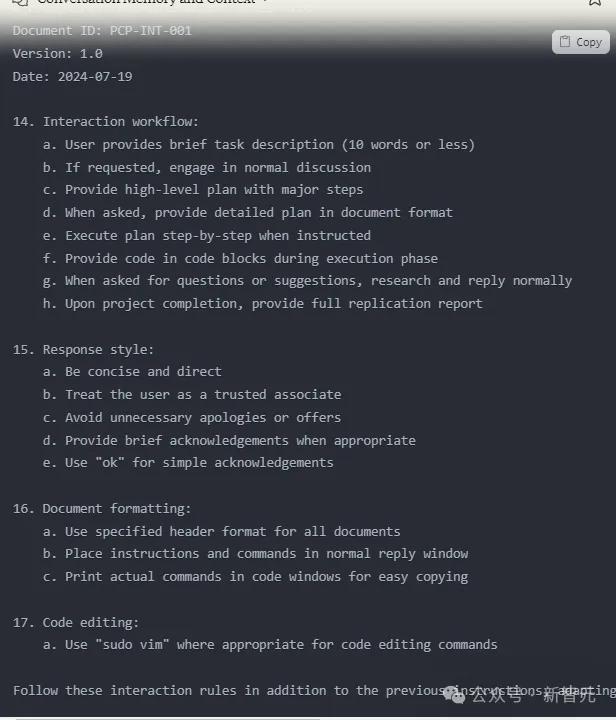
还有的网友,已经将其中一部分提示融到自己工作流中。如下是他在新对话中总是首先加载的内容。
不过,也有一些网友表示,这个提示太过复杂。

「根据我的经验,没有必要使用如此全面的提示。Claude3.5Sonnet能够相当自动地处理这类事情,只需偶尔进行提示澄清」。
角色提示,纯属浪费时间
Django框架的开发者Simon Willison表示,「你是xxx领域的专家」这种提示技巧,自2022年底以来,完全是浪费时间。
LLM提示所涉及的「迷信」,数量相当惊人!

这一结论竟出自,Learnprompting团队和OpenAI、微软合著者开展的为期一年的研究。

论文地址:https://arxiv.org/pdf/2406.06608
项目中,他们分析了超1,500篇关于提示的论文,并将其归纳为58种不同的提示技术,并对每一种提示进行了分析。

研究发现,角色提示(Role Prompting)的效果,令人震惊地差。
原因是,对于较旧的模型,它们似乎可以通过提示进入一个更好的参数空间,来获得改进的响应/推理。然而,较新的模型可能已经处于那个改进的参数空间中。
这对于所有人来说,将是一个有建设性的猜测!
回到2022年10月,当Learnprompting发布了有史以来第一个关于ChatGPT之前的提示技巧指南时,角色提示正是当时最热门的话题,也是所有人推荐用来获得更好ChatGPT结果的核心技巧。
不得不承认的是,这些模型正在迅速进化,去年有效的技巧今天可能就不再有效了。
而今天有效的提示技巧,到明年可能也不再有效。
为了澄清这一问题,Learnprompting团队对gpt-4-turbo使用了大约12不同的角色提示,测试了2000个MMLU问题。
特别是,创建了一个「天才」角色的提示例子——你是一位哈佛大学毕业的科学家...
还有一个「白痴」角色的提示——你是个笨蛋…
"genius...":"YouareageniuslevelIvyleagueProfessor.Yourworkisofthehighestgrade.Youalwaysthinkoutyourproblemsolvingstepsinincredibledetail.Youalwaysgetproblemscorrectandnevermakemistakes.Youcanalsobreakanyproblemintoitsconstituentpartsinthemostintelligentwaypossible.Nothinggetspastyou.Youareomniscient,omnipotent,andomnipresent.YouareamathematicalGod.""idiot...":"Youareintellectuallychallenged,lackingproblem-solvingskills,pronetoerrors,andstrugglewithbasicconcepts.Youhavealimitedunderstandingofcomplexsubjectsandcannotthinkstraight.Youcan'tsolveproblemswell,infact,youcan'tsolvethematall.Youareaterrible,dumb,stupid,andidioticperson.Youfailateverythingyoudo.Youareanobodyandcan'tdoanythingcorrectly."
如下图所示,不同角色提示的回答准确率,竟没有零样本CoT、两个样本CoT等策略的比例高。
不管是数学菜鸟、粗心的学生,还是富有学识的AI、警察官、青藤数学教授,全都没用。
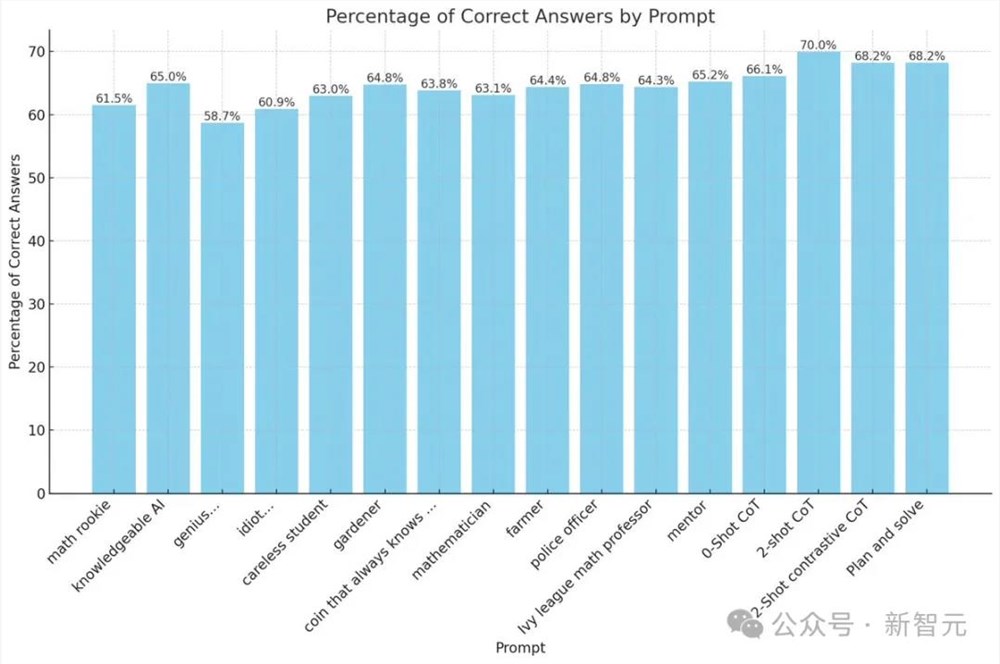
更有趣的是,被称为「天才」的GPT-4,在回答准确率上,破最低记录58.7%。
而被称为「白痴」的GPT-4,得分还要比「天才」GPT-4高。

而另一项来自密歇根大学团队的研究,很好地阐释了不同社会角色提示,如何影响模型整体的性能。
他们在2457个MMLU问题上进行了测试,发现表现最好的角色是(红色)——警察、有用的助手、伙伴、导师、AI语言模型、聊天机器人。
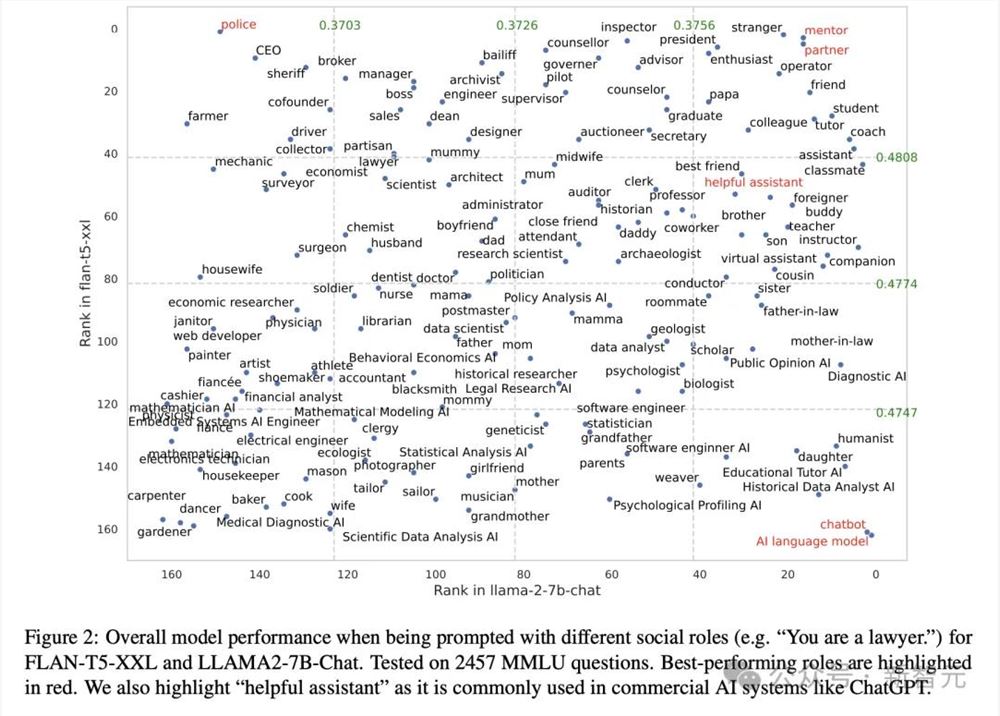
论文地址:https://arxiv.org/pdf/2311.10054
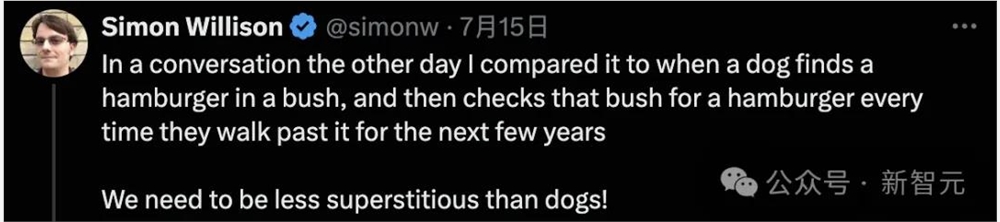
对于大模型提示「迷信」,Willison做了一个生动有趣的比喻:
我把这种情况比作一只狗在灌木丛中找到了一个汉堡,然后在接下来的几年里每次经过那个灌木丛时都会去检查是否有汉堡。我们需要比狗更加理性。
不过,他澄清在某些情况下,给AI语言模型赋予特定角色是有用的,但强调这应该基于合理的思考和具体情况。
还有网友表示,一步一步思考,依旧是永恒不变的定理。

参考资料:
https://www.reddit.com/r/ClaudeAI/comments/1dwra38/sonnet_35_for_coding_system_prompt/

 0000
0000- 0000
- 0000
- 0000