力压70B Llama 3,Gemma 2成最强开源模型,大佬质疑用榜单prompt微调引全网热议
导读:时隔4个月上新的Gemma2模型在LMSYS Chatbot Arena的排行上,以27B的参数击败了许多更大规模的模型,甚至超过了70B的Llama-3-Instruct,成为开源模型的性能第一!
谷歌出手,果然非同凡响。

Gemma2上周刚刚发布,就在LMSYS竞技场上取得了亮眼的成绩。
在整体评分上Gemma2拿到了开源模型最高分,而且用27B的参数「以小搏大」,超过了Llama3-70B-Instruct、Claude3Sonnet等更大量级的知名模型。
开源模型的头把交椅真的要易主Gemma了?
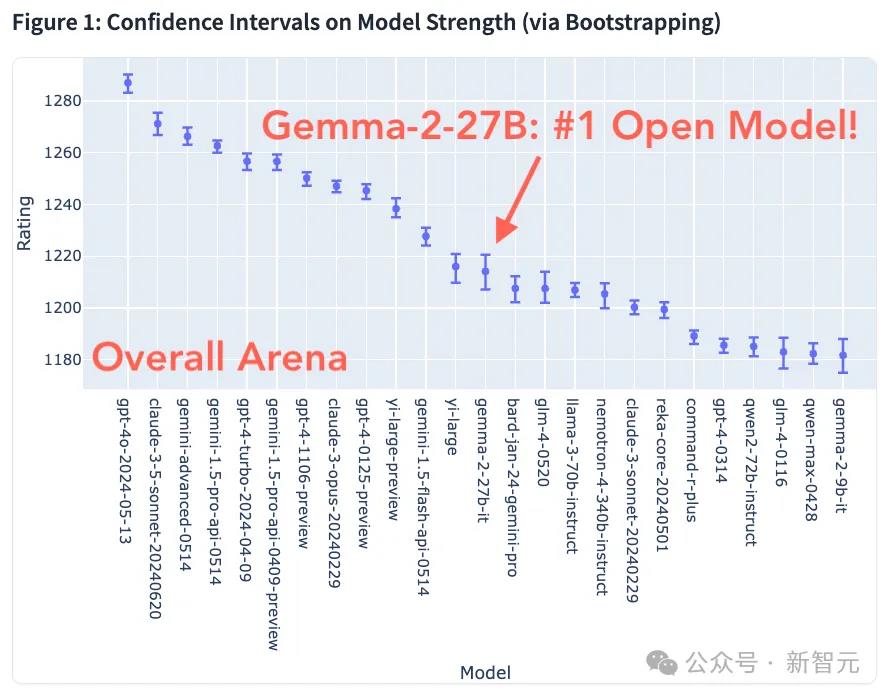
对于这个成绩,谷歌研究院首席科学家Jeff Dean也发文庆祝。

很高兴看到新版Gemma-2-27B模型成为LMSYS上最好的开源模型(击败了一些相当大的模型)。
我们认为,27B对于很多场景来说确实是一个非常好的规模,而Gemma-2-27B也是一个非常好的模型!
不仅是总体评分,在LMSYS昨天刚发布的「多轮对话」排行榜上,Gemma2的表现依旧强劲。
LMSYS表示,LLM的多轮对话在当今许多应用场景中非常重要。
在竞技场的投票中,多轮对话的占比为14%,占到了不可忽视的比例。
因此他们推出了新的排行类别「多轮对话」,其中包括两轮或多轮的测试,以衡量模型在更长时间内交互的能力。

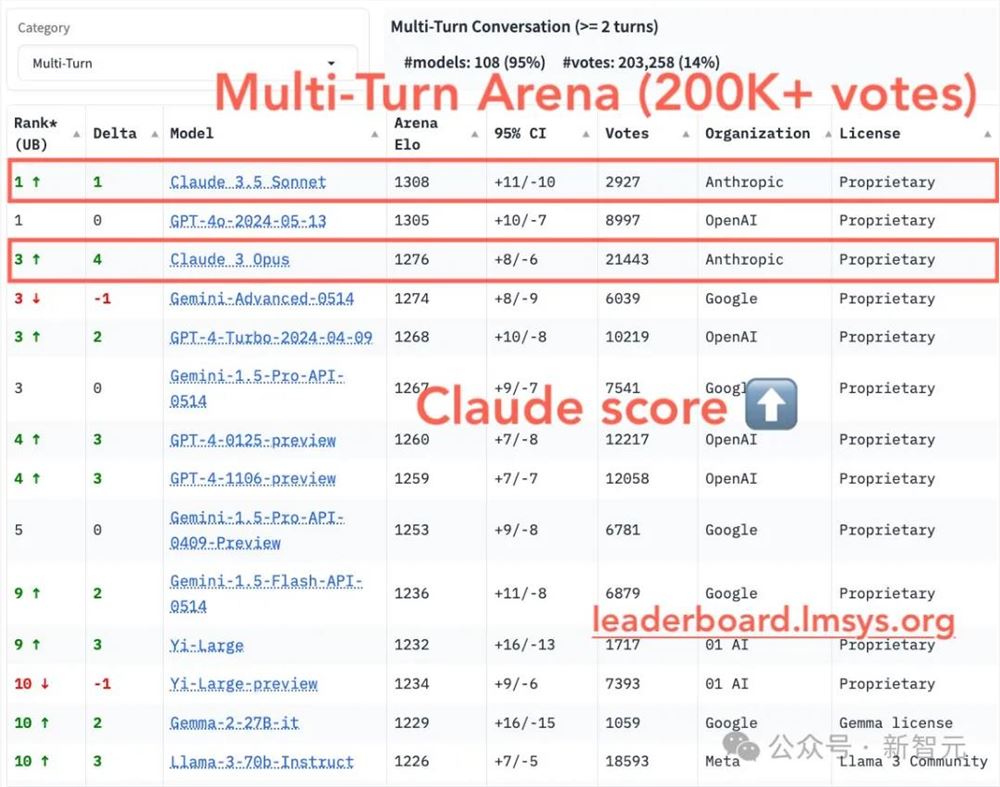
在这个全新的排行榜中,Claude家族的排名显著提升。
总分屈居亚军的Claude3.5Sonnet,成功地与GPT-4o并列第一;Claude3Opus也从原来的第8名跃居第三。
我们本次的主角Gemma2也实现了2个名次的进步,进入前十行列,而且压了Llama3-70B-Instruct一头。
在Gemma2放出9B和27B两个版本的同时,DeepMind研究员Clement在推特上透露,接下来还会有2B版本和大家见面!

曾经只靠开源「一招鲜」的Meta终于迎来了强劲对手。Gemma2和Llama3的竞争想必会在未来一段时间内持续下去。
Gemma为什么这么强?
为什么27B的Gemma2能打败70B的Llama3?谷歌究竟用了什么技术实现如此高的参数效率?
或许我们可以从官方发布的技术报告中找到蛛丝马迹。

报告地址:https://developers.googleblog.com/en/fine-tuning-gemma-2-with-keras-hugging-face-update/
训练数据方面,可想而知,并没有具体的数据来源和组成,只有数据量。
由于Gemma既没有多模态又不针对多语言任务,因此训练语料只包含各种类型的文本和代码,且主要语言为英语。
27B模型的训练数据有13万亿token,9B模型和2.6B模型则分别为8万亿、2万亿token。

架构上,Gemma2从Gemini团队和Gemma1沿用了很多方面,包括旋转位置编码(RoPE)、SentencePiece分词器、Logit软上限、GeGLU激活函数等等。
相比Gemma1,Gemma2采用了更深的网络,且在某些部分做了更新——
局部滑动窗口和全局注意力
Gemma2交替使用局部滑动窗口和全局注意力,滑动窗口大小设置为4096token,而全局注意力层的设置为8192token。
这种方法在正确捕捉文本细节的同时,又能保持对上下文和全局的正确理解。
知识蒸馏
能够训练出有竞争力性能的9B和27B模型,成功的知识蒸馏过程估计是最为重要的环节。
传统训练大语言模型的方法主要是根据之前的token,预测下一个token,需要大量的数据进行训练。
但是,人类的学习过程并不依赖走量的知识输入。比如,一位学生由于阅读原著的需要学习一门外语,他并不需要看遍所有的书籍,只需要以一本书为纲,通过理解后融会贯通。
而知识蒸馏法与人的学习过程更加类似。一个小模型向另一个已经进行过预训练的大模型学习,通过这种方式助产小模型对于token的预测。
站在老师模型的肩膀上,学生模型能用较少的训练数据、更少的参数量提升性能。

用LMSYS数据微调,引AI2研究员质疑
开源模型界终于在Llama之后迎来了Gemma2这个最新的扛把子选手,就在大家忙着兴奋的同时,Allen AI的研究员Nathan Lambert冷静地在技术报告中发现了华点:
微调数据的来源包括LMSYS的聊天数据集!
似乎是预想到了可能的质疑,论文中特意强调只使用了prompt,把答案剔出去了。

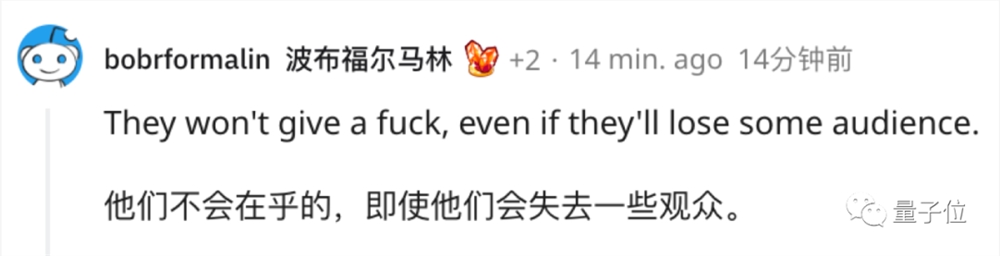
Lambert依旧不认可这种行为。他发了一篇推特,疑惑的语气中带着一丝嘲讽:为了在竞技场上刷分数,你们谷歌团队挺有想象力的。

这位Nathan Lambert其实算是LLM领域比较资深的专业人士,他博士毕业于UC伯克利大学,在DeepMind和FAIR都有实习经历。
针对Lambert的质疑,LMSYS随后回复了一篇意义不明的超长推特,似乎透露出了为谷歌辩护的隐晦立场。

推特全文如下:
从一开始,Chatbot Arena的使命就是通过人类偏好来解决LLM的评估问题。
通过开放我们的数据集和论文,我们希望社区能研究真实世界的prompt,并利用这些数据改进模型(就像ImageNet的训练集一样)。
我们相信,通过实时和新鲜的用户投票,Arena比静态基准测试如MMLU更不容易过拟合。
现在,有些人可能对以下两个方面存在质疑——(1)prompt重复的程度和(2)数据分布。这正是我们开放数据和论文研究的原因。
我们的Llama-3博客文章显示,经过去重之后,大约10%的重复对结果的影响很小。此外,论文还包括对prompt分布的主题建模,展现了跨语言的多样化使用案例。
展望未来,我们计划深入了解数据的新鲜度和分布。也欢迎大家用新任务来挑战模型,研究我们的100万prompt和偏好数据,或者加入我们的Kaggle挑战。
这有些让人摸不着头脑,既说「用数据改进模型是受欢迎的」,又说「我们开放数据和论文是为了回应质疑」。
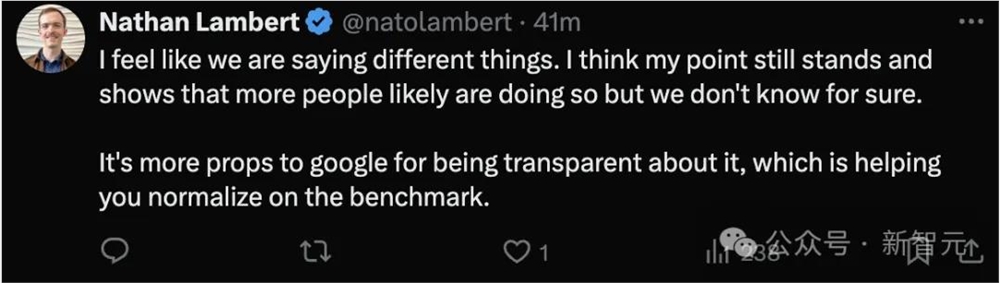
发帖的Lambert也同样被搞糊涂了,他进一步阐明了自己的立场。
「感觉我们讨论的不是同一件事,我的观点依旧成立。很可能有更多的人也在这样做,但我们并不知道。」
LMSYS最新回复的内容更加让人内心复杂——
「对不起,虽然我贴上了你的推特,但不是在特意回复你。」

对于微调应不应该使用LMSYS数据这个问题,评论区的网友也吵得热火朝天。
有些人觉得Lambert的质疑毫无道理。毕竟LMSYS公开了数据集,用来做微调有什么不可以的?而且只使用了prompt,答案是教师模型生成的。
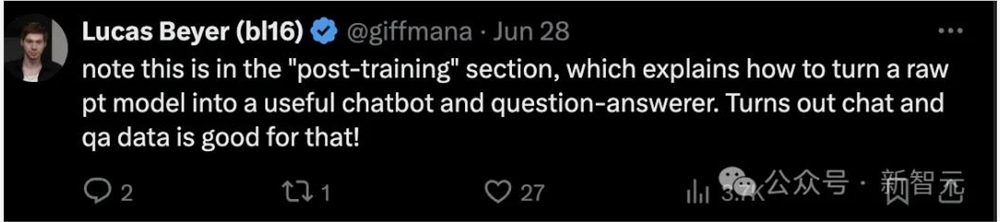
毕竟大家都在看LMSYS的聊天机器人Arena的分数,如果大家都不用这个数据才比较出乎意料。
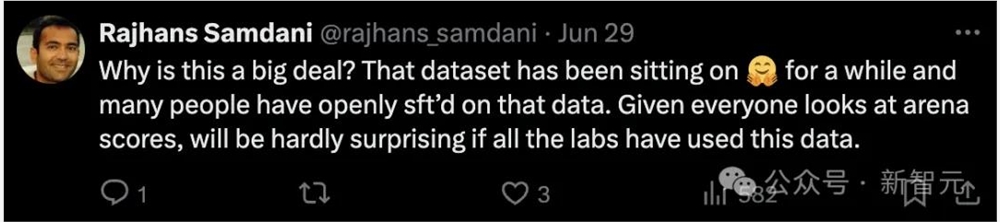
这个立场得到了大部分人的认同。虽然谷歌是为数不多的坦诚,敢把用了LMSYS数据这件事写进论文,但他们绝对不是第一个使用这些数据的人。
「我打赌GPT-4o和Llama3也这么干了。」

毕竟在一段时间内,LMSYS竞技场曾经是唯一可信的基准测试。

而这也正是Lambert所担心的——LMSYS是业界为数不多的得到大多数人认可的基准测试,如果大家再用它的数据微调甚至训练,岂不很快又会失去公信力?
更糟糕的情况是,不是每一个模型都像Gemma2这样会承认这件事。
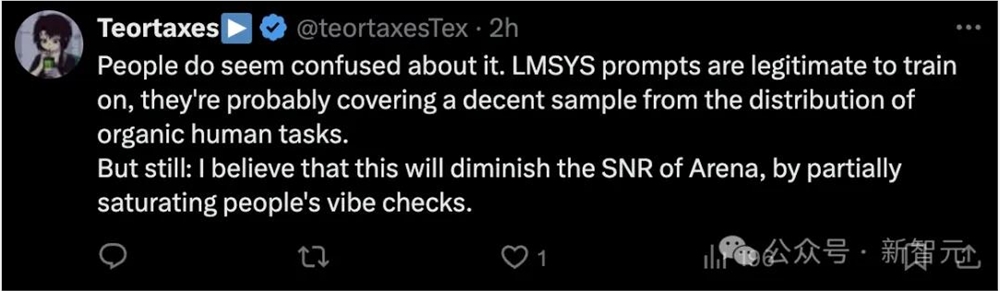
不少观点比较中肯的网友也点出了这一点。
「我相信这会降低Arena的信噪比。」
看来在基准测试领域,重复的历史总在不断上演,而那个金句也总是适用——
「当一个衡量标准成为目标时,它就不再是一个好的衡量标准了。」

参考资料:
https://x.com/JeffDean/status/1807407880766726464
https://x.com/lmsysorg/status/1807503885181006236
https://x.com/natolambert/status/1806384821826109597
https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf
- 0001
 0000
0000- 0000
- 0000
- 0000