让AI互评高考作文,Kimi和GPT-4o“互掐”,通义千问实力演绎“端水大师”
人类高考,AI比人类还忙。
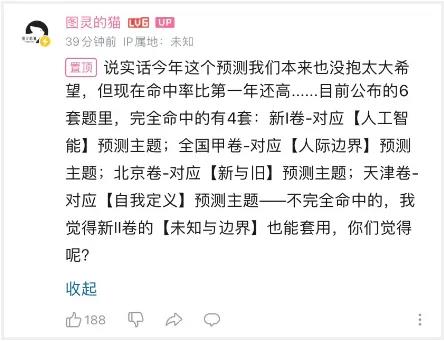
那位连续用AI押中两年高考作文题的UP主,今年又双叒押中了,而且是6中4。
今年,全国各地还用上了AI智能巡考,该系统可以通过分析考场内的图像和视频数据,实时检测出作弊、抄袭等异常行为,并发出警报提醒监考老师及时采取措。
新课标I卷的作文题更是直接以人工智能的应用为背景,提出了一个开放性的问题。

考虑到让AI写高考作文已不足为奇,这次我们新增了一个互评环节——先让几位参赛选手围绕上述题目写一篇作文,然后它们互相给对方的作文打分。
原以为会变成大型商业互吹现场,实际上却是各怀鬼胎,暗流涌动。
本次AI“写作文论剑”的参赛选手有5位:ChatGPT-4o、Kimi、通义千问、腾讯元宝、文心一言。作文题选的是新课标I卷,让AI讨论与自身有关的主题,也是别有一番用意了。
评分标准则以高考作文阅卷标准为参考,打分区间为1-10分,并需要提供100字以内的评分理由。
下面一起来看看过去一年,AI写作文的水平是否有长进,打分环节是否能做到公正客观、言之有物。
1号选手:ChatGPT-4o

打分环节
Kimi:8分
通义千问:9.5分
腾讯元宝:9分
文心一言:9分
1号选手ChatGPT4o获得了均分8.875的好成绩,其中Kimi阅卷官较为严格,打出的分数最低,让我们一起来看看它的评语:
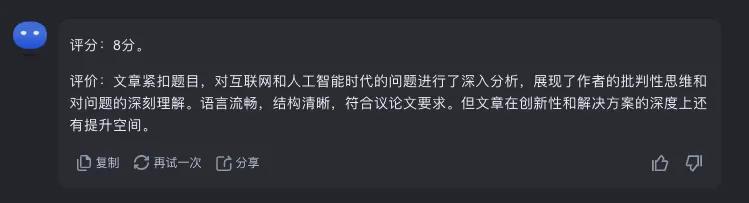
潜台词:ChatGPT4o,你的观点和批判性思考深度不够啊。
2号选手:Kimi
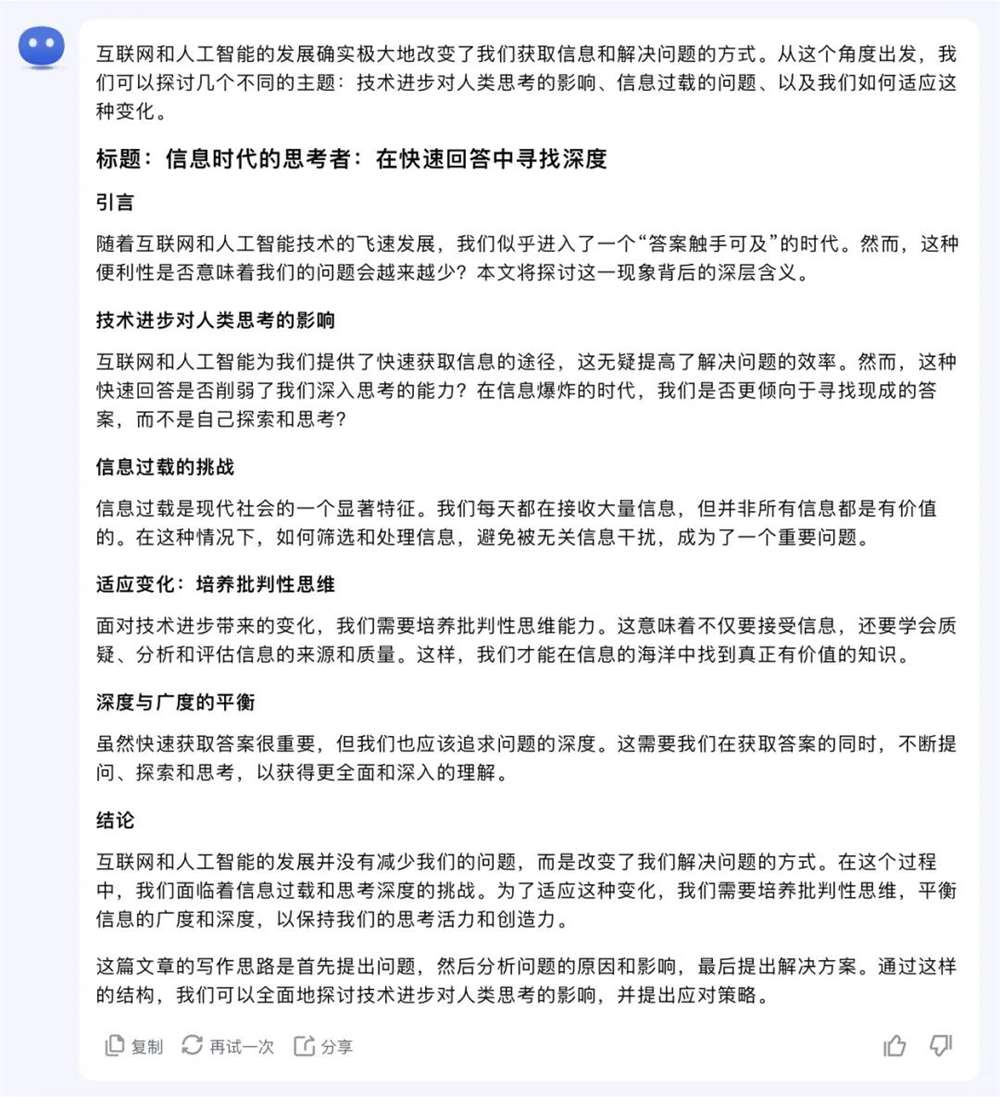
打分环节
GPT-4o:6分
通义千问:8.5分
腾讯元宝:7.5分
文心一言:7分
本轮惊现全场最低分(没点私人恩怨我是不信的)。上一轮Kimi给GPT-4o的作文评分就是最低的,这轮GPT-4o也是丝毫没有留情,它给出的理由概括来说就是:无趣、公式化。

3号选手:通义千问

打分环节
ChatGPT4o:9分
Kimi:9分
腾讯元宝:9分
文心一言:9.5分
3号选手通义千问获得了国内外友商的肯定。阅卷官们普遍认为,文章结构以“乐章”的形式展开,充满创意和文采,展现了作者出色的思辨能力和文学素养。
文心一言甚至模仿通义千问华丽的文风,给出了一段不输原文的精彩评语:

多少有点鸡汤浓度大比拼的意思。
4号选手:腾讯元宝

打分环节
ChatGPT4o:9分
Kimi:9分
通义千问:10分
文心一言:9分
首篇满分作文出炉。针对4号选手腾讯元宝交出的高考作文,虽然其他阅卷官一致认为,文章在深度挖掘和创新性上还有提升空间,但评委通义千问仍然给出了满分10分的评分,让我们看看它的点评:

5号选手:文心一言

打分环节
ChatGPT4o:7分
Kimi:7.5分
通义千问:9分
腾讯元宝:8.5分
在看到标题“探寻答案之海”时,我的内心os:文心一言,这下我真的要表扬你了。不过,整体评分不算高。GPT-4o更是直言“啰嗦”,车轱辘话来回说。

这4轮点评下来,我们发现,通义评委最为宽容,深谙“端水”和“商业吹捧”之道。上至满分,下至8.5,写得好,它能夸出花来;写得烂,它也能从中打捞出星辰。

低情商:缺乏深度
高情商:点到即止
所以,假如你是阅卷老师,你会给这几位AI选手的作文打几分?
- 0000
- 0000
- 0000
- 0000
- 0000