媲美Sora?快手文生视频模型可灵开放测试 更懂物理,最长可生成2分钟视频
昨天,快手公司推出了一款名为「可灵」的全新视频生成大模型,该模型采用了与Sora相似的技术路线,并结合了快手自研的多项技术创新。这款模型不仅能够生成长达2分钟、30fps、1080p分辨率的超长视频,支持多种宽高比,还能模拟物理世界的特性,精准建模复杂运动。
亮点:
1、生成能力强大:
支持长达2分钟的30fps高清视频生成,分辨率高达1080p。
支持多种宽高比,包括竖版视频,非常适合快手的短视频生态。
2、运动和物理模拟:
准确刻画复杂、大幅度的运动,如公路上奔跑的老虎、宇航员在月球上行走等。
能够模拟物理特性,如重力、液体流动和光学反射等,生成的画面更符合真实物理规律。
3、应用场景广泛:
从娱乐到教育,可灵的应用场景广泛。
支持文本转视频、多种控制信息输入、以及丰富的内容控制能力。
「可灵」大模型够准确刻画复杂、大幅度的时空运动,如公路上高速奔跑的老虎,画面连贯,动作协调,甚至奔跑过程中躯干的抖动也得到了细致展现。它还能模拟真实物理世界的特性,比如倒牛奶时的重力规律和液面上升,以及光学上的反射规律。此外,「可灵」还能真实反映与真实物理世界的交互,如小男孩吃汉堡时齿印的变化等。
以下是官方发布的视频案例及提示词:
prompt:一个戴眼镜的中国男孩在快餐店内闭眼享受美味的芝士汉堡
prompt:一名宇航员在月球表面奔跑,低角度镜头展现了月球的广阔背景,动作流畅且显得轻盈
一只戴着眼镜的兔子在看报纸
厨师正在切菜
一只蓝色的鹦鹉
技术特点
1、原生视频生成技术:
采用类似Sora的DiT结构,用Transformer代替传统的卷积网络U-Net。
3D VAE网络用于时空同步压缩,提高重建质量和训练性能。
3D Attention机制用于时空建模,提升复杂时空运动的建模能力。
2、高质量数据支持:
构建了完备的标签体系,对训练数据进行精细化筛选和分布调整。
专用的视频描述模型生成精确、详尽的结构化视频描述,提升模型的文本指令响应能力。
3、高效训练策略:
使用分布式训练集群和优化策略提高运算效率。
分阶段训练策略:初期低分辨率阶段侧重数量,后期高分辨率阶段侧重质量,确保模型在各阶段的优化。
实际应用
1、快影APP:
可灵大模型已在快影APP中开启邀测,当前版本支持生成720P视频,竖版视频生成能力即将开放。
2、其他应用:
“AI舞王”:上传全身照,生成人物跟随音乐跳舞的视频。
“AI唱跳”:生成跳舞并唱歌的视频。
未来还将推出图生视频功能。
快手在大模型技术方面动作迅速,与多个高校或科研机构合作发布了多项关键技术,为「可灵」大模型积累了深厚的技术沉淀。现在,快手的文生视频功能已正式亮相,期待其在短视频场景中的应用落地。
对AI视频创作感兴趣的用户,可以在快影APP中体验「可灵」大模型的功能。
体验方法:快影 APP-AI 玩法-AI 视频生成中申请。
官网地址:https://top.aibase.com/tool/kelingdamoxing
- 0000
- 0000
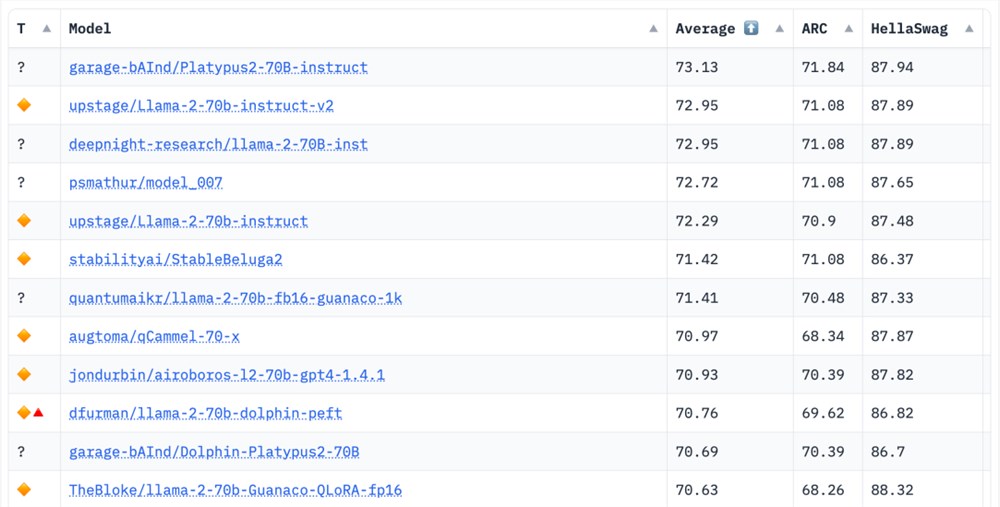

 0000
0000- 0000

 0000
0000


