为什么斯坦福大学生要抄袭中国大模型?
“他们会设法复制一切,却无法复制我的思想,我让他们辛苦偷窃,却永远落后我一年半载。”——Rudyard Kipling(印度作家)
美国大模型抄袭了中国?
6月初,一些眼尖的网友发现,一个来自美国斯坦福大学的AI团队于5月29日发布了一款名为Llama3V的大模型,号称只要500美元就能训练出一个 SOTA多模态模型,且效果比肩OpenAI的GPT-4V、谷歌DeepMind开发的Gemini Ultra与Anthropic目前能力最强的模型Claude Opus。
然而,经过网友仔细查验,这款大模型疑似抄袭、“套壳”一家由中国大模型公司面壁智能的开源成果——MiniCPM-Llama3-V2.5,后者是在5月中旬发布的。
所谓“套壳”,深度科技研究院院长张孝荣对小巴解释道:“通常是指在不改变核心算法和架构的情况下,对模型进行一些表面的调整或包装,并声称是原创。”
FutureLabs未来实验室首席专家胡延平进一步科普表示:模型开源本身就意味着开放给他人使用,可以说所有基于开源大模型的微调等二次开发都是在套壳。
区别在于,是明确声称基于别人的开源大模型来做——一个比较流行的规范做法是明示:同时感谢或致敬。
但很多只眼睛看了又看斯坦福团队的Llama3V后发现,并没有相关标识。
据雷锋网的观察,一开始,由于这款产品的主创团队有斯坦福背景,又集齐了特斯拉、SpaceX、亚马逊与牛津大学等机构的相关经历,因此模型发布后备受瞩目。
发现不对劲后,6月2日,网友试图在Llama3V的Github项目下抛出事实性质疑,但很快被Llama3V的团队删除,网友被这种不坦诚的举动激怒,开始在论坛公开曝光,并提醒面壁智能团队“打假”。
被抄袭方面壁智能是一家已完成数亿元融资的国内知名创业公司,拥有100多名研发人员,其中80%来自清华北大。
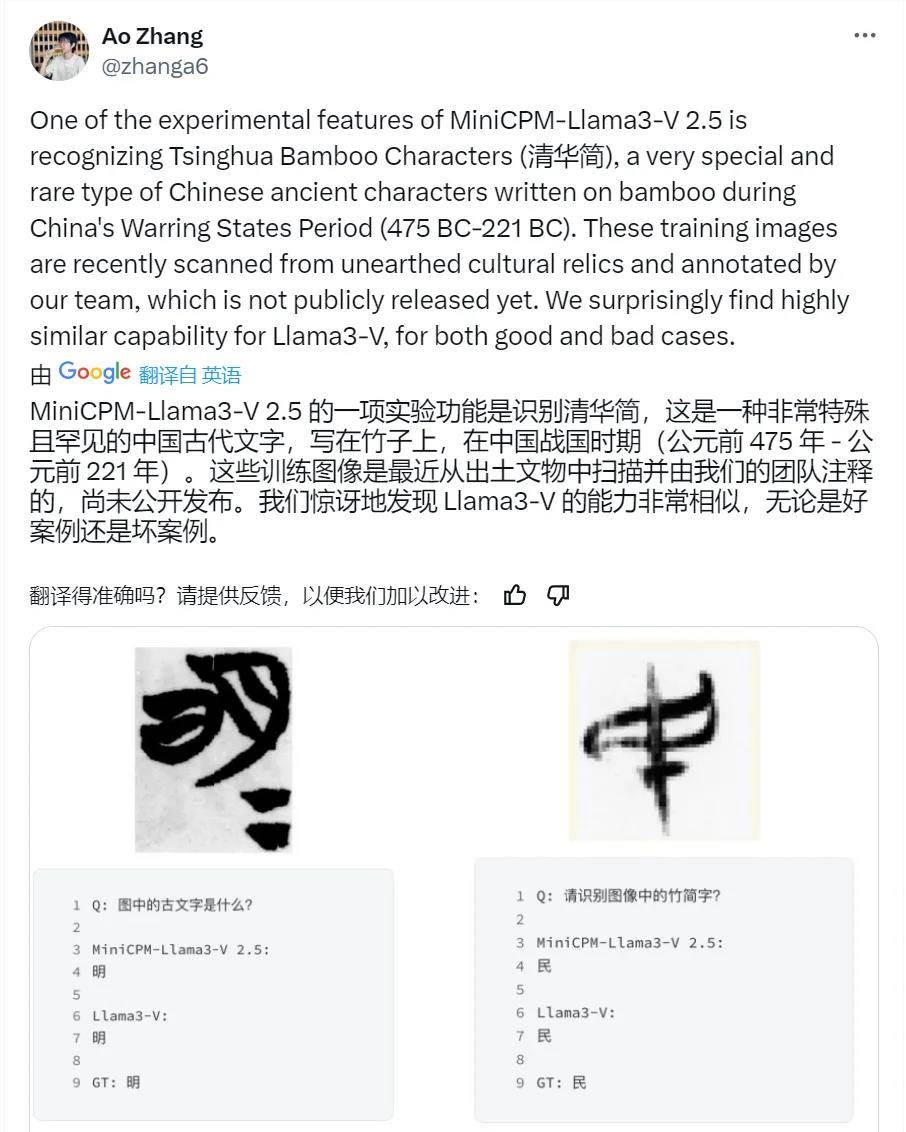
6月2日,面壁智能团队深夜回应,MiniCPM-Llama3-V2.5曾被用于识别清华大学藏战国竹简(后简称“清华简”)上的战国古文字,团队花费数月在清华简上逐字扫描并人工标注,且从未对外公开。
然而,测试后团队发现,斯坦福的模型不仅能识别出“清华简”中的战国古文字,而且连错误的识别结果都与MiniCPM模型完全一致,由此坐实抄袭。
消息传到国内,一石激起千层浪。
卧龙抄袭了凤雏?
这次的抄袭事件之所以备受瞩目,在于事件主角的特殊性:斯坦福大学和清华大学,以及一些“意外感”加持——是美国团队抄袭了中国团队(细想反而有些心酸)。
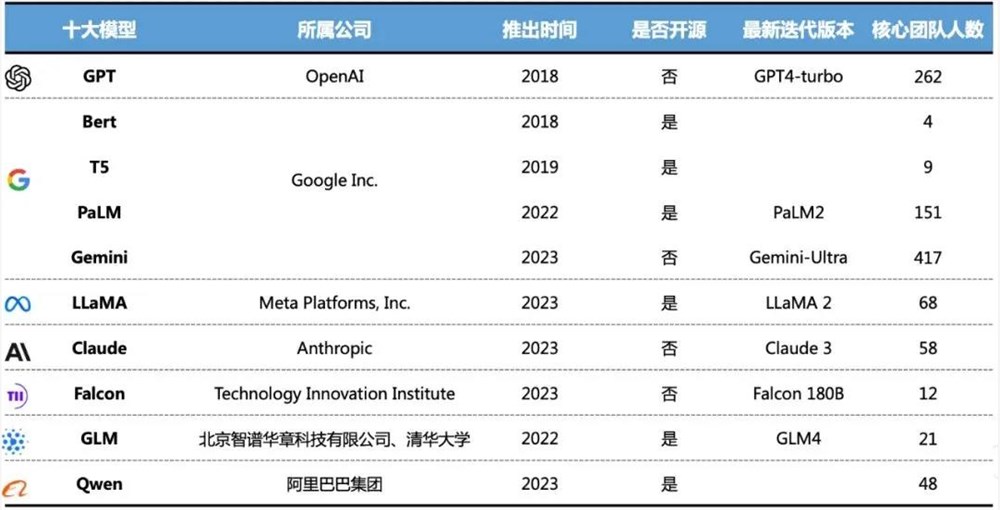
根据AMiner发布的《全球十个大模型核心团队成员分析报告》,十款全球著名的大模型GPT、Gemini、Claude、GLM、LLaMA、Qwen、Falcon、PaLM、BERT、T5的全部核心成员中,大都经过加州大学系统和斯坦福大学培养,而清华大学是其中唯一一所上榜的中国高校。
*小巴注:加州大学不是一所大学,而是由加州的公立大学所组成的大学系统,分别位于加州不同的市,但十所不同的分校大多都有名。
此外,熟悉大模型行业的有心人会发现,国内大模型的公司介绍里,往往会强调:公司的七成到九成都是研发人员,而必要时,他们还会写上清华创始团队。
甚至在斯坦福自己发布的《2024年人工智能指数报告》中,在讨论全球AI模型时,清华大学成为被提及为非西方机构中发布基础模型数量最多的学术机构之一。
由此,这次事件似乎发展成了“美国卧龙抄袭了中国凤雏”的走向,引发热议也就不足为奇了。
但从身份上细看,两个团队却有明显差距。
6月2日,斯坦福团队其中一名成员Aksh Garg(加格)在社交平台X上正式道歉,并对本次事件公开道歉,并进行了解释,他的推文称之所以会如此,主要是他们“信错了猪队友”。
据其原文,抄袭团队共有三位美国年轻人,Siddharth Sharma(夏尔马)、Aksh Garg(加格)、Mustafa Aljadery(阿尔贾德里)。
夏尔马和加格是斯坦福大学本科生,主要负责Llama3-V模型的宣传推广。阿尔贾德里是毕业于南加州大学的年轻创业者,主要负责Llama3-V模型的代码开发。在Llama3-V模型开发过程中,阿尔贾德里为了快速出名,抄袭了来自中国的MiniCPM-Llama3-V2.5大模型。
我们翻了翻另一位成员夏尔马以往的推文,如其所言,他确实是一位技术圈的KOL(意见领袖),给很多产品做过宣传,不只是Llama3-V。
因此事件的实质,是南加州大学背景的人抄袭了清华背景的大模型。

而面壁智能一边,他的联合创始人兼首席科学家是刘知远。
据官网介绍,刘知远在人工智能领域著名国际期刊和会议发表相关论文200余篇,Google Scholar统计引用超过3.1万次,曾获教育部自然科学一等奖。
他的老师孙茂松的头衔更长——欧洲人文和自然科学院外籍院士,国际计算语言学协会会士,中国人工智能学会会士,中国中文信息学会会士,清华大学计算机科学与技术系长聘教授、博士生导师——同时也是桃李满天下,包括刘知远在内的三个学生同时都是国内知名AI创业公司的成员。
实际上,出自明星团队的面壁MiniCPM-Llama3-V2.5大模型在中国AI界颇有知名度,但大部分美国人并不知道。
界面报道中就提到,针对此事,谷歌DeepMind研究员Lucas Beyer在点评此事时说,有同样表现的MiniCPM-Llama3-V2.5得到了太少的关注,而这似乎仅仅因为这个模型不是来自一所“美国常青藤名校”。
因此,事件最终发展成了一场闹剧——一些有斯坦福大学和加州大学背景的草台班子,利用中美之间的信息差,抄袭了中国尖端研究团队的作品。
当事人刘知远,在斯坦福团队道歉后的一天,在知乎感慨道:
人工智能的飞速发展离不开全球算法、数据与模型的开源共享,让人们始终可以站在SOTA的肩上持续前进。我们这次开源的 MiniCPM-Llama3-V2.5就用到了最新的Llama3作为语言模型基座。
而开源共享的基石是对开源协议的遵守,对其他贡献者的信任,对前人成果的尊重和致敬,Llama3-V团队无疑严重破坏了这一点。他们在受到质疑后已在Huggingface删库,该团队三人中的两位也只是斯坦福大学本科生,未来还有很长的路,如果知错能改,善莫大焉。
“你中有我,我中有你”
梳理完事件的来龙去脉,大家或许会感慨,事情的真相,似乎与人们看到新闻时,第一时间脑补的“中国清华系与美国斯坦福系的PK大赛”“中国的大模型崛起了”剧情走向有着很大的距离。
但情绪的落差也未必真有这么大。
胡延平就认为,这件事之所以引起广泛关注,主要在于“反向抄袭”这类情况比较少见。以往国内AI团队基于国外开源大模型来开发的比较多,国外团队使用国内大模型来开发的很少见。说明国产大模型虽然整体落后,但局部也有可圈可点之处。
比胡延平更有信心的专家则表达了不同的看法。
一位业内人士在看完这个事件后就对小巴感叹:“单就大语言模型来说,我一直相信中美差距会缩小,但美国会出新东西。而这个事情,确实可以说明中美在大语言模型上的差距正在缩小,技术层面上至少可以证明你中有我、我中有你。”
张孝荣也表示,斯坦福团队抄袭中国团队的行为确实可以反映出中国团队在大模型应用开发领域,处于基本与美国相当的水平。
不过,此事件另一个值得留意的地方,是本次事件中作为“发现者”“曝光者”以及“提醒者”的有心网友。
如果没有他们对于新大模型产品的严格审查,第一时间的质疑与提醒,这件事恐怕也很难从一个小众的领域里这么快破圈而出。
“只要眼睛多,bug容易捉。”这是1999年出版的《大教堂与集市》一书中的一句话,也是本书的核心奥义。
这个书名人文气息浓郁的作品,被称作互联网开源运动的“圣经”。
作者Eric S·Raymond埃里克·雷蒙在二十多年前,倡议用“集市”模式开放源代码,鼓励全球的软件开发者一起参与开发软件,从而取代过去大公司闭门造车的“大教堂”模式。
换言之,是成千上万的臭皮匠能顶一个诸葛亮。
他的预言成了我们的现实,他的理念是我们习以为常的价值观——如今人们所使用的所有软件、网络、操作系统无一不是开源下发展而来的产品。
开源贯穿互联网发展的始终,也延绵到了人工智能时代,幸好,雷蒙的“眼睛多”定律,不止有助于发现bug,也有助于发现抄袭。
这次事件,在某种程度上也让我们再次感受到了来自互联网开放精神的魅力,从某种意义上来说,这个斯坦福团队犯得最大的错,在于他们利用了互联网的开放性,却忽略了开放性的另一个重要特点:全民监督。
事后,就有网友疑惑评论:“难道他们不怕被发现么?”
也许,再开放的世界,也敌不过一个自我封闭的大脑和视野。
 0000
0000- 0000
- 0000
- 0001
 0000
0000