昆仑万维宣布开源2千亿稀疏大模型Skywork-MoE 性能强劲成本更低
在大模型技术迅速发展的背景下,昆仑万维公司开源了一个具有里程碑意义的稀疏大型语言模型Skywork-MoE。这个模型不仅在性能上表现出色,而且还大幅降低了推理成本,为应对大规模密集型LLM带来的挑战提供了有效的解决方案。
Skywork-MoE模型特点:
开源和免费商用:Skywork-MoE的模型权重、技术报告完全开源,且免费商用,无需申请。
推理成本降低:该模型在保持性能强劲的同时,大幅降低了推理成本。
稀疏模型:Skywork-MoE是一个专家混合模型(MoE),通过将计算分配给专门的子模型或“专家”,提供了一种经济上更可行的替代方案。
支持单台4090服务器推理:是首个支持用单台4090服务器推理的开源千亿MoE大模型。
技术细节:
模型权重和开源仓库:模型权重可在Hugging Face上下载,开源仓库位于GitHub。
推理代码:提供了支持8x4090服务器上8bit量化加载推理的代码。
性能:在8x4090服务器上,使用昆仑万维团队首创的非均匀Tensor Parallel并行推理方式,Skywork-MoE可以达到2200tokens/s的吞吐量。
模型性能和技术创新:
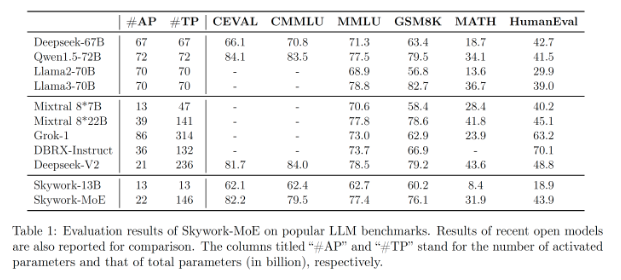
参数量:Skywork-MoE的总参数量为146B,激活参数量22B,共有16个Expert,每个Expert大小为13B。
性能对比:在相同的激活参数量下,Skywork-MoE的能力在行业前列,接近70B的Dense模型,推理成本有近3倍的下降。
训练优化算法:Skywork-MoE设计了两种训练优化算法,包括Gating Logits归一化操作和自适应的Aux Loss,以解决MoE模型训练困难和泛化性能差的问题。
大规模分布式训练:
Expert Data Parallel:提出了一种新的并行设计方案,可以在Expert数量较小时高效地切分模型。
非均匀切分流水并行:提出了非均匀的流水并行切分和重计算Layer分配方式,使得计算/显存负载更均衡。
实验和经验规则:
Scaling Law实验:探究了影响Upcycling和From Scratch训练MoE模型好坏的约束。
训练经验规则:如果训练MoE模型的FLOPs是训练Dense模型的2倍以上,则选择From Scratch训练MoE更好;否则,选择Upcycling训练MoE可以减少训练成本。
Skywork-MoE的开源为大模型社区带来了一个强大的新工具,有助于推动人工智能领域的发展,特别是在需要处理大规模数据和计算资源受限的场景中。
项目页:https://top.aibase.com/tool/skywork-moe
模型下载地址:https://huggingface.co/Skywork/Skywork-MoE-Base
- 0000
- 0000
- 0000
- 0000
- 0001


