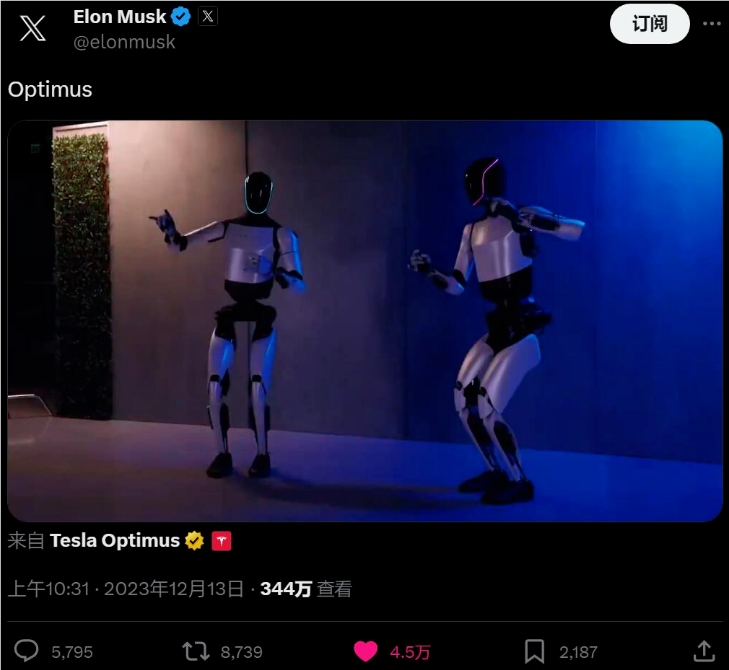大型科技公司拥才有承担 AI 训练数据成本的能力
划重点:
⭐️ AI 模型训练数据的重要性越来越显著,使得除了最富有的科技公司外,其他公司难以承担成本。
⭐️ 数据采集与整理对生成式 AI 的改进至关重要,这为大型科技公司带来了竞争优势。
⭐️ 尽管一些非营利组织正在尝试开放式数据集的创建,但大型科技巨头仍占据着 AI 训练数据市场的主导地位。
AI 的发展离不开数据,而这种数据的成本越来越高,这使得除了最富有的科技公司外,其他公司难以承担这一成本。根据去年 OpenAI 的研究人员 James Betker 的文章,AI 模型的训练数据是决定模型能力的关键因素。传统的 AI 系统主要是基于统计机器,通过大量示例来猜测最 “合理” 的数据分布,因此模型所依赖的数据量越大,性能就越好。

AI 研究非营利机构 AI2的高级研究科学家 Kyle Lo 指出,Meta 的 Llama3模型在数据量方面明显优于 AI2的 OLMo 模型,这解释了其在许多流行 AI 基准测试中的优势。然而,并不是数据量越大,模型性能就会线性提升,数据质量和整理同样重要,有时甚至比数量更重要。一些 AI 模型是通过让人类标注数据来进行训练的,质量较高的标注对模型性能有巨大影响。
然而,Lo 等专家担心,对大型、高质量训练数据集的需求将 AI 发展集中在少数具备数十亿美元预算的公司手中。尽管一些非法甚至犯罪行为可能会对数据获取方式提出质疑,但技术巨头凭借资金实力能够获取数据许可。这些数据交易的过程并未促进一个公平开放的生成式 AI 生态系统,让整个 AI 研究社区备受其害。
一些独立、非营利性的组织尝试开放大规模数据集,如 EleutherAI 和 Hugging Face,但它们是否能赶上大型科技公司的步伐仍是一个未知数。只有当研究突破技术壁垒,数据收集和整理成本不再是问题时,这些开放性的数据集才有希望与科技巨头竞争。


 0001
0001- 0001
- 0000
- 0001
- 0002