「豆包」拉低价格线 全球大模型开卷性价比
大模型也开始打起价格战。
5月15日,字节跳动旗下火山引擎发布豆包大模型,除了针对C端用户的豆包APP可免费使用该模型的应用外,豆包大模型将B端用价拉至行业最低。
按照火山引擎总裁谭待的说法,豆包主力模型(≤32K)在企业市场的定价只有0.0008元/千Tokens,0.8厘就能处理1500多个汉字,比行业便宜99.3%。
豆包以高性价比亮相之前,通义千问、智普AI、DeepSeek等国内很多大模型都开始“卷”起价格,百模大战也随着集体降价进入了新阶段。正如谭待所说,降低成本是推动大模型快进到“价值创造阶段”的一个关键因素。
「豆包」将B端用价拉至行业新低
豆包大模型的前身是云雀大模型,也是2023年8月字节跳动旗下发布的首个基于Transformer架构的大模型。半年后,豆包大模型不仅出了全家桶,还将针对行业B端用户降价。
豆包主力模型在企业市场的定价只有0.0008元/千Tokens,0.8厘就能处理1500多个汉字,比行业便宜99.3%。据此计算,1块钱就能买到豆包主力模型的125万Tokens的用量,大约为200万个汉字,相当于三本《三国演义》。而128K的豆包通用模型也只需要0.005元/千Tokens,比行业价格低95.8%。
要知道GPT-4Turbo输入1000Tokens为0.01美元,输出1000Tokens价格为0.21元。相比之下,字节跳动直接把价格“打骨折”,堪称AI界的拼多多。
不止“豆包”,国内不少大模型都在降价。
不久前,百度发布了文心大模型轻量版,其中ERNIE Tiny版本的价格降到了0.001元每千Tokens,相当于1元100万Tokens。
今年5月,智谱AI的大模型商用价格也大幅降价。入门级产品GLM-3Turbo模型调用价格下调80%,从5元/百万Tokens降至1元/百万Tokens,足以让更多企业和个人都能用上这款入门级产品。
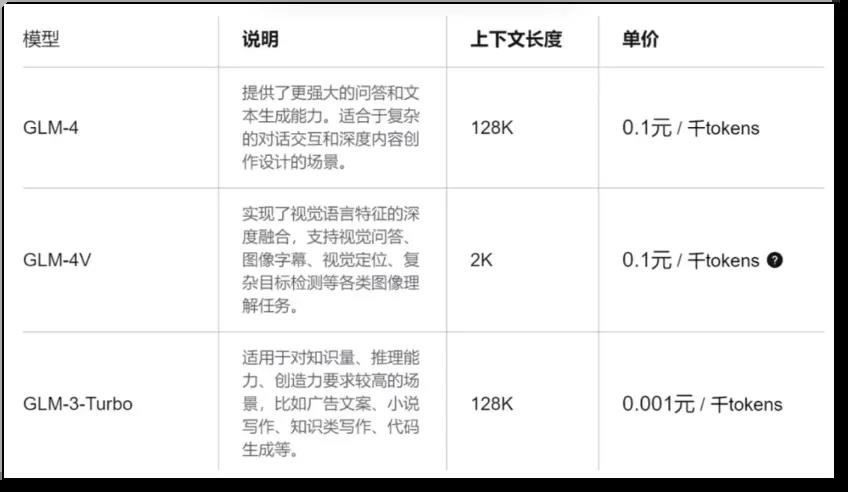
智谱AI的大模型的价格
5月6日,国内知名私募巨头幻方量化旗下的AI公司DeepSeek发布全新第二代MoE大模型DeepSeek-V2,DeepSeek-V2API定价为每百万Tokens输入1元、输出2元(32K上下文)。
5月9日,阿里云正式发布通义千问2.5,根据OpenCompass的测评结果,通义千问2.5得分追平GPT-4Turbo,与此同时,个人用户可从App、官网和小程序免费使用。
5月14日,腾讯的混元文生图大模型直接开源,免费商用。
在海外,OpenAI刚刚发布的GPT-4o也大幅度降价,不仅供所有用户免费使用,在API调用方面也比去年11月发布的GPT-4-turbo降价一半,但速度提升两倍。这是OpenAI大模型产品的第三次降价。
法国人工智能企业Mistral AI大模型Mistral Large的输入、输出价格目前也比GPT-4Turbo便宜约20%,一度引起广泛关注。
无论国内还是海外,大模型正在集体降价。
大模型降本 应用落地增效
各个厂商“价格战”已经开打,而在大半年前,人们获知的常识是大模型训练很烧钱,为何仅仅半年时间,厂商们就能将价格“打下来”、纷纷卷了起来?
火山引擎总裁谭待认为,降低成本是推动大模型快进到“价值创造阶段”的一个关键因素。对于中小型企业客户而言,调用大模型的一个重要考虑就是成本。谭待透露,字节跳动在模型结构、训练、生产等各种技术层面有很多优化手段能够实现降价。
OpenAI CEO Sam Altman也为人们不用在ChatGPT上看广告就能使用它而感到骄傲,“我们的一个关键使命就是将AI产品免费提供给人们。”
的确,低价正在帮助大模型研发企业抓住市场机会,以占据一席之地。而用户体量的增加也能反过来帮助研发训练出更好模型。那么,大模型的训练成本真的降低了吗?
去年GPT-4发布时,Sam Altman曾透露,OpenAI最大模型的训练成本“远远超过了5000万美元”。据斯坦福大学发布的《2024年人工智能指数报告》估算,OpenAI的GPT-4训练成本为7800万美元。
高昂的大模型训练成本也直接推高的使用费用,直接将很多企业用户阻拦在外。
不过,研究人员们正在寻找更低成本的训练方法。去年,新加坡国立大学和清华大学的研究者提出了一个名为VPGTrans框架,以极低成本训练高性能多模态大模型,相比于从头训练视觉模块,VPGTrans框架可以将BLIP-2FlanT5-XXL的训练开销从19000 人民币缩减到不到1000元。
国产大模型中,研发人员也各个方面找到降本增效的办法。DeepSeek-V2提升数据集质量、优化架构后,AI异构计算平台“百舸”将训练和推理场景的吞吐量最高提升30%和60%。
除了训练过程外,一些大模型训练的基础设施——芯片也在降价,比如英伟达AI芯片Nvidia A100的降价直接将大模型训练成本降低了约60%。
大模型价格战最直接的影响就是应用落地开始提速。豆包平台上,已经有超过800万个智能体被创建。GPT Store已有超过300万个依托GPT模型的APP被创建。
仅半年时间,砸钱拼大模型性能的时代似乎已经是过去式。现如今,市场用户也随着各家大模型的降价更看重谁家大模型又实惠又好用。这将推动大模型应用更快在场景和商业上实现落地。
 0000
0000- 0000
- 0003
- 0001
- 0000