国产黑马与GPT-4o称霸中文榜首!Yi-Large勇夺国内LLM盲测桂冠,冲进世界第七
【新智元导读】真正与GPT-4o齐头并进的国产大模型来了!刚刚,LMSYS揭开最新榜单,黑马Yi-Large在中文分榜上与GPT-4o并列第一,而在总榜上位列世界第七,紧追国际第一阵营,并登上了国内大模型盲测榜首。
几周前,一个名为「im-also-a-good-gpt2-chatbot」的神秘模型突然现身大模型竞技场Chatbot Arena,排名直接超过GPT-4-Turbo、Gemini1.5Pro、Claude3Opus、Llama3-70B等各家国际大厂的当家基座模型。
随后OpenAI揭开了「im-also-a-good-gpt2-chatbot」神秘面纱——正是GPT-4o的测试版本。
OpenAI CEO Sam Altman也在GPT-4o发布后亲自转帖引用LMSYS Arena盲测擂台的测试结果。
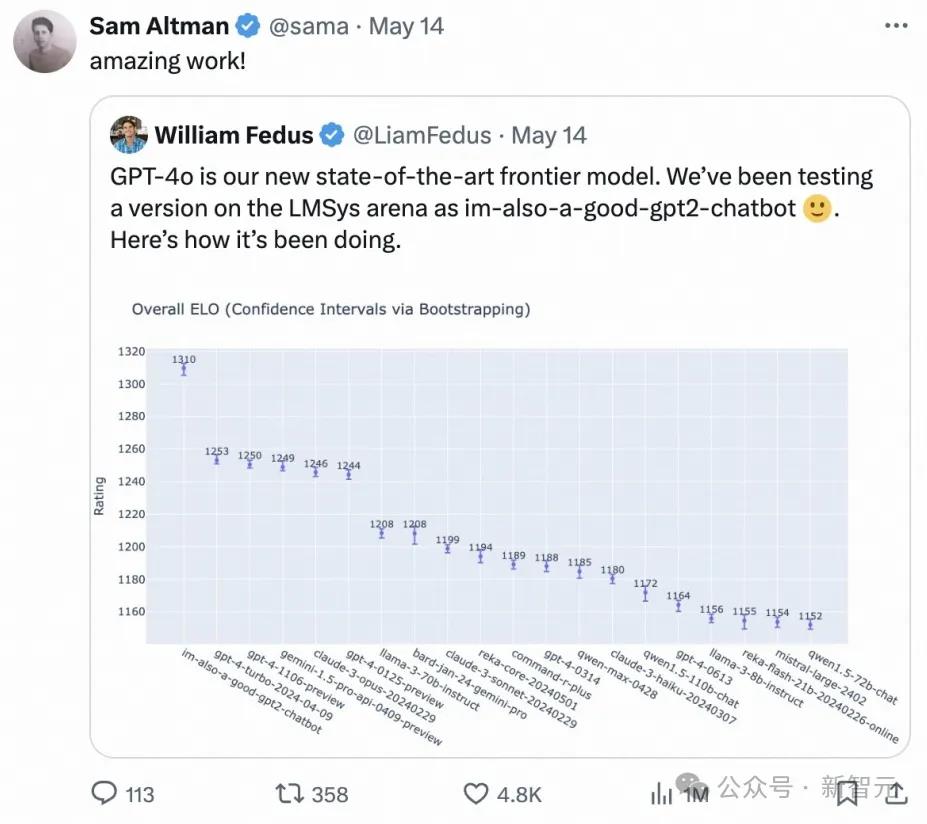
由开放研究组织LMSYS Org(Large Model Systems Organization)发布的Chatbot Arena已经成为OpenAI、Anthropic、Google、Meta等国际大厂「龙争虎斗」的当红擂台,以最开放与科学的评测方法,在大模型进入第二年之际开放群众投票。
时隔一周,在最新更新的排名中,类「im-also-a-good-gpt2-chatbot」的黑马故事再次上。
这次排名飞速上涨的模型正是由中国大模型公司零一万物提交的「Yi-Large」千亿参数闭源大模型。
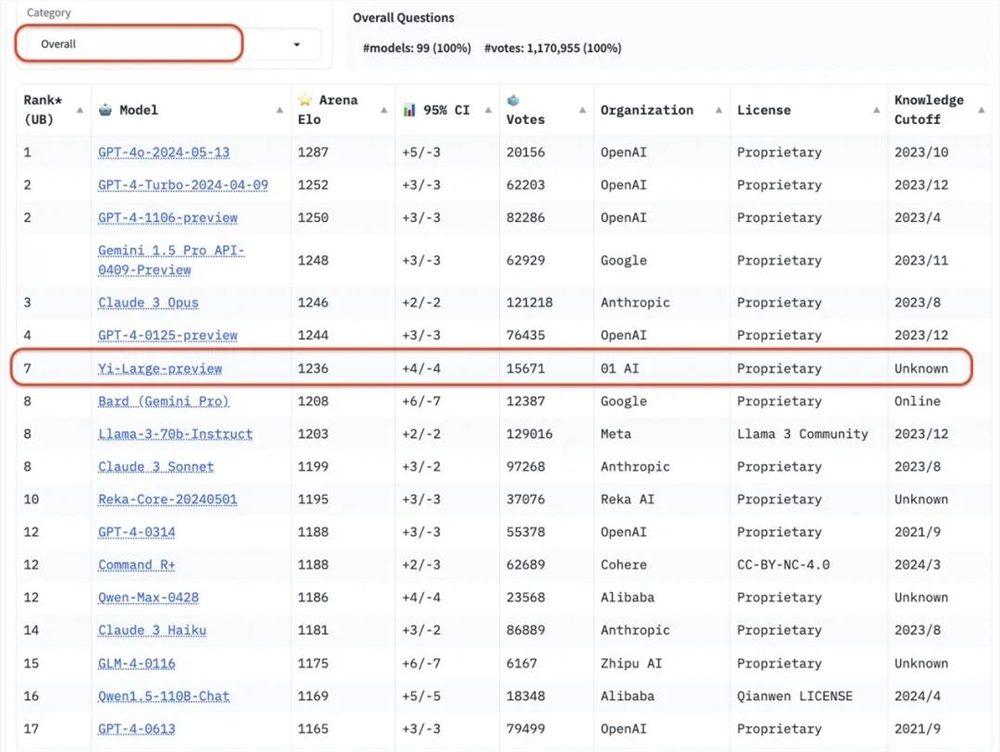
在LMSYS竞技场最新排名中,零一万物的最新千亿参数模型Yi-Large总榜排名世界模型第7,中国大模型中第一,已经超过Llama3-70B、Claude3Sonnet;其中文分榜更是与GPT-4o并列世界第一。
零一万物也由此成为了总榜上唯一一个自家模型进入排名前十的中国大模型企业。
在总榜上,GPT系列占了前10的4个,以机构排序,零一万物01.AI仅次于OpenAI、Google、Anthropic之后,以开放金标准正式进击国际顶级大模型企业阵营。
美国时间2024年5月20日刚刷新的LMSYS Chatboat Arena盲测结果,来自至今积累超过1170万的全球用户真实投票数:
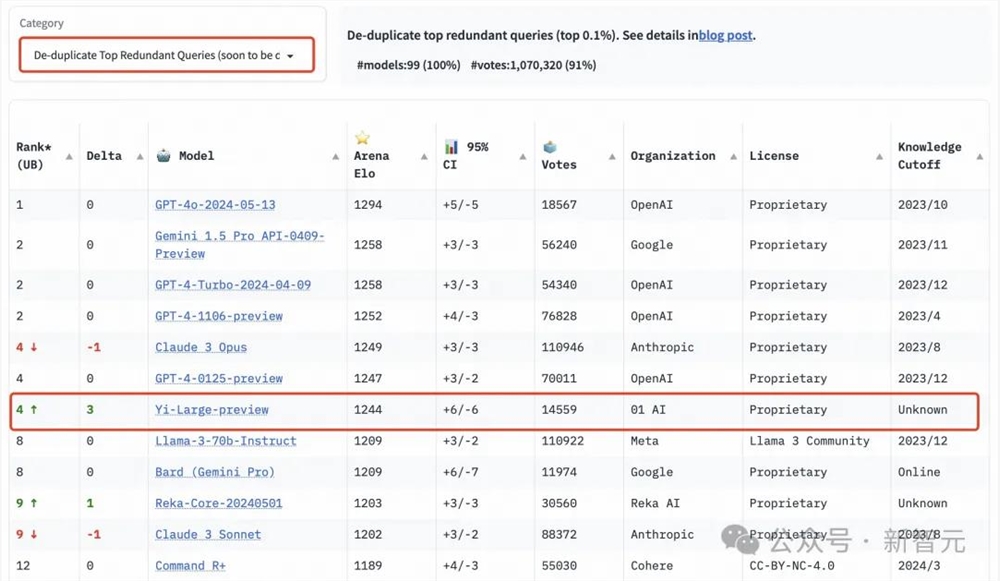
值得一提的是,为了提高Chatbot Arena查询的整体质量,LMSYS还实施了重复数据删除机制,并出具了去除冗余查询后的榜单。
这个新机制旨在消除过度冗余的用户提示,如过度重复的「你好」。这类冗余提示可能会影响排行榜的准确性。
LMSYS公开表示,去除冗余查询后的榜单将在后续成为默认榜单。
在去除冗余查询后的总榜中,Yi-Large的Elo得分更进一步,与Claude3Opus、GPT-4-0125-preview并列第四。
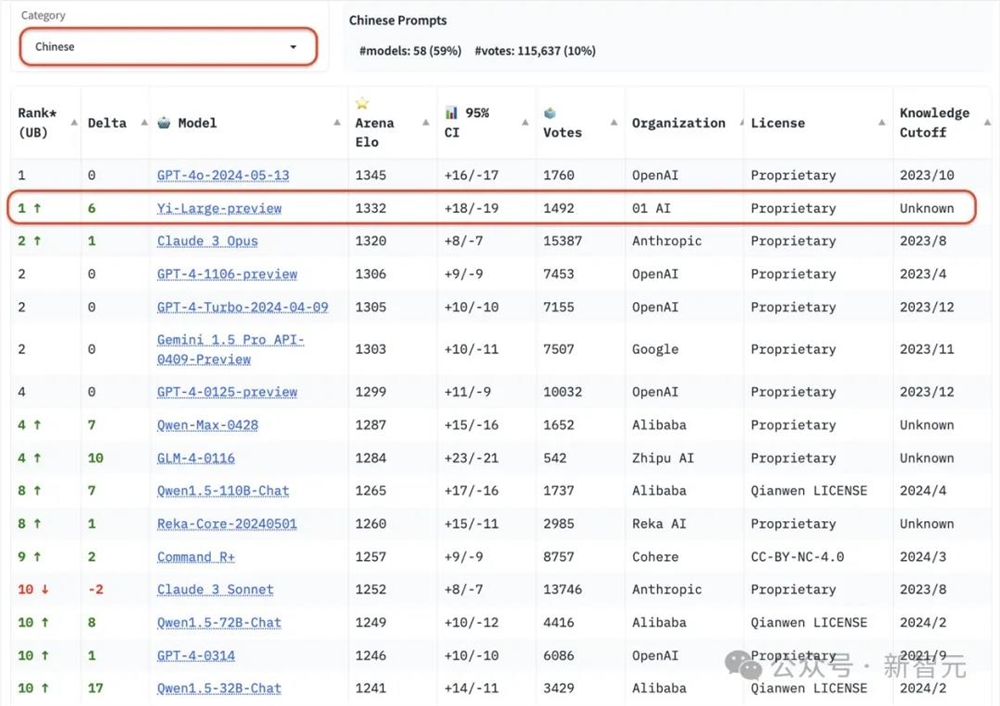
LMSYS中文榜:GPT-4o和Yi-Large并列第一
值得国人关注的是,国内大模型厂商中,智谱GLM-4、阿里Qwen Max、Qwen1.5、零一万物Yi-Large、Yi-34B-chat此次都有参与盲测。
在总榜之外,LMSYS的语言类别上也新增了英语、中文、法文三种语言评测,开始注重全球大模型的多样性。
其中,Yi-Large在中文语言分榜上拔得头筹,与OpenAI刚刚官宣一周的地表最强GPT-4o并列第一,Qwen-Max和GLM-4在中文榜上也都表现不凡。
「最烧脑」公开评测:Yi-Large位居全球第二
在分类别的排行榜中,Yi-Large同样表现亮眼。
编程能力、长提问及最新推出的「艰难提示词」的三个评测是LMSYS所给出的针对性榜单,以专业性与高难度著称,可称作大模型「最烧脑」的公开盲测。
在编程能力(Coding)排行榜上,Yi-Large 的Elo分数超过Anthropic 当家旗舰模型 Claude3Opus,仅低于GPT-4o,与GPT-4-Turbo、GPT-4并列第二。
长提问(Longer Query)榜单上,Yi-Large同样位列全球第二,与GPT-4-Turbo、GPT-4、Claude3Opus并列。
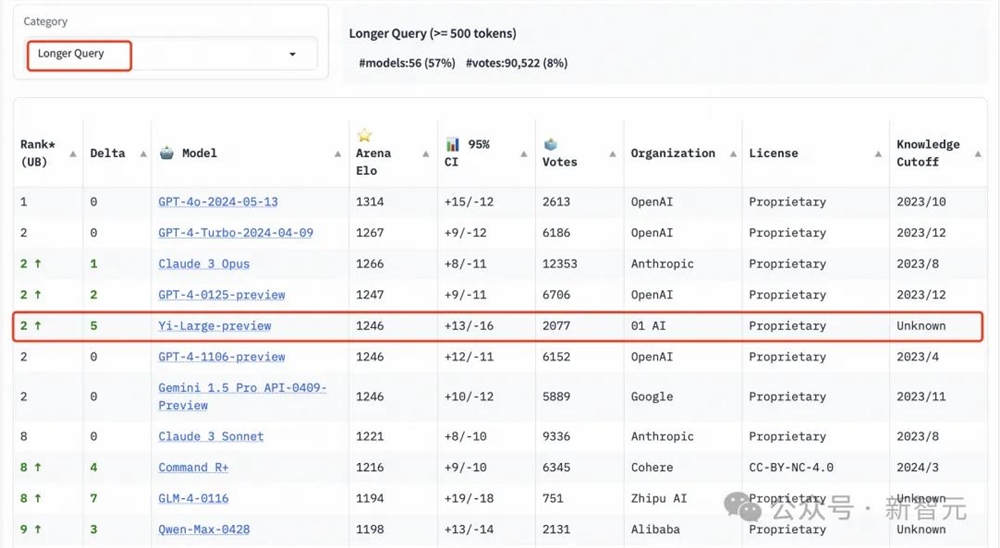
艰难提示词(Hard Prompts)则是LMSYS为了响应社区要求,于此次新增的排行榜类别。这一类别包含来自Arena的用户提交的提示,这些提示则经过专门设计,更加复杂、要求更高且更加严格。
LMSYS认为,这类提示能够测试最新语言模型面临挑战性任务时的性能。
在这一榜单上,Yi-Large处理艰难提示的能力也得到印证,与GPT-4-Turbo、GPT-4、Claude3Opus并列第二。
LMSYS Chatbot Arena:后benchmark时代的风向标
如何为大模型给出客观公正的评测一直是业内广泛关注的话题。
为了在固定题库中取得一份亮眼的评测分数,业内出现了各式各样的「刷榜」方法:将各种各样的评测基准训练集直接混入模型训练集中、用未对齐的模型跟已经对齐的模型做对比等等,对尝试了解大模型真实能力的人,的确呈现「众说纷纭」的现场,更让大模型的投资人摸不着北。
在经过2023年一系列错综复杂、乱象丛生的大模型评测浪潮之后,业界对于评测集的专业性和客观性给予了更高的重视。
而LMSYS Org发布的Chatbot Arena凭借其新颖的「竞技场」形式、测试团队的严谨性,成为目前全球业界公认的基准标杆,连OpenAI在GPT-4o正式发布前,都在LMSYS上匿名预发布和预测试。
在海外大厂高管中,不只Sam Altman,Google DeepMind首席科学家Jeff Dean也曾引用LMSYS Chatbot Arena的排名数据,来佐证Bard产品的性能。
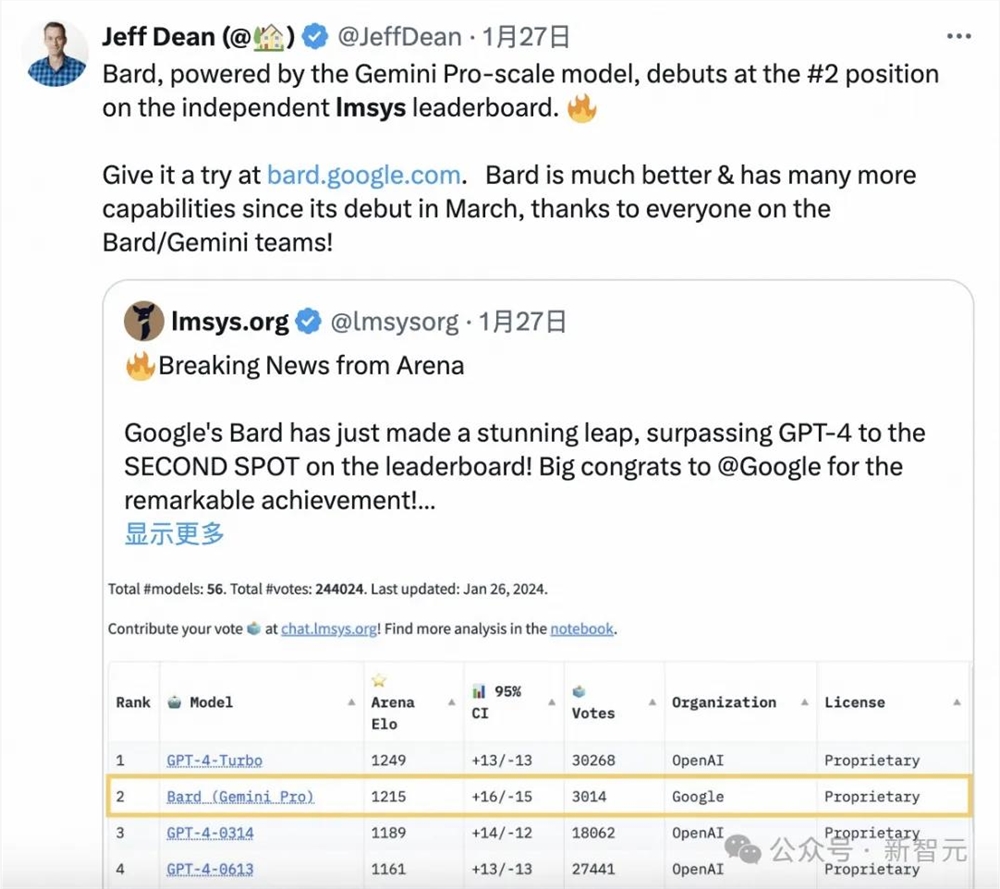
OpenAI创始团队成员Andrej Karpathy甚至公开表示,Chatbot Arena is「awesome」。
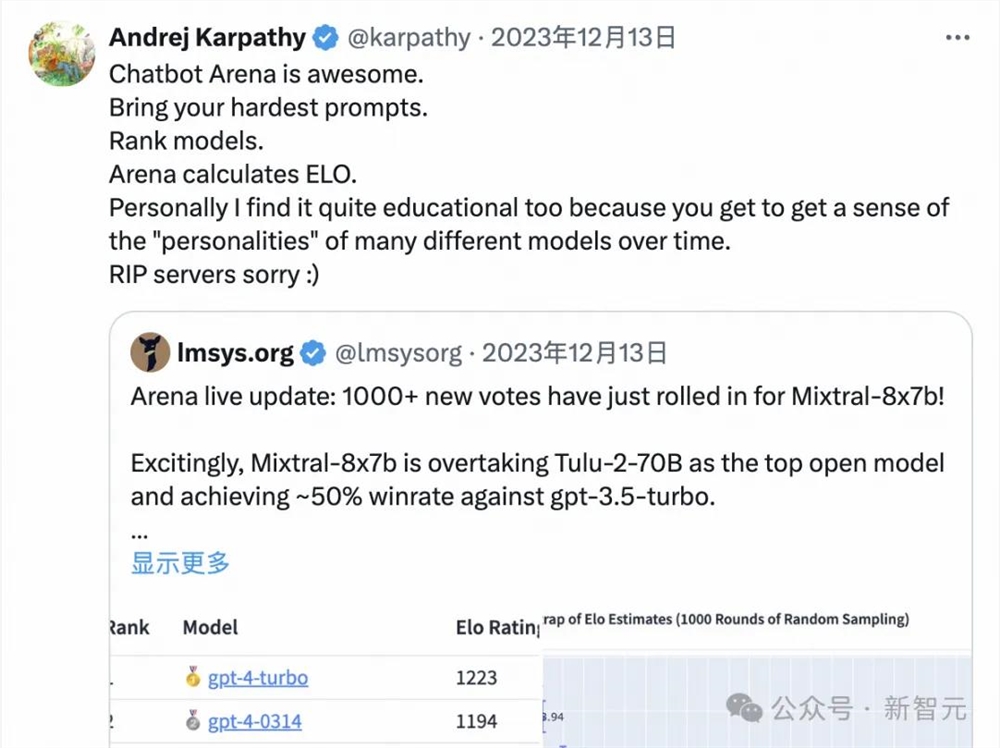
自身的旗舰模型发布后第一时间提交给LMSYS,这一行为本身就展现了海外头部大厂对于Chatbot Arena的极大尊重。
这份尊重既来自于LMSYS作为研究组织的权威背书,也来自于其新颖的排名机制。
公开资料显示,LMSYS Org是一个开放的研究组织,由加州大学伯克利分校的学生和教师、加州大学圣地亚哥分校、卡耐基梅隆大学合作创立。
虽然主要人员出自高校,但LMSYS的研究项目却十分贴近产业,他们不仅自己开发大语言模型,还向业内输出多种数据集(其推出的MT-Bench已是指令遵循方向的权威评测集)、评估工具,此外还开发分布式系统以加速大模型训练和推理,提供线上live大模型打擂台测试所需的算力。
在形式上,Chatbot Arena借鉴了搜索引擎时代的横向对比评测思路。
它首先将所有上传评测的「参赛」模型随机两两配对,以匿名模型的形式呈现在用户面前。
随后号召真实用户输入自己的提示词,在不知道模型型号名称的前提下,由真实用户对两个模型产品的作答给出评价。
在盲测平台上,大模型们两两相比,用户自主输入对大模型的提问,模型A、模型B两侧分别生成两PK模型的真实结果,用户在结果下方做出投票四选一:A模型较佳、B模型较佳,两者平手,或是两者都不好。
提交后,可进行下一轮PK。
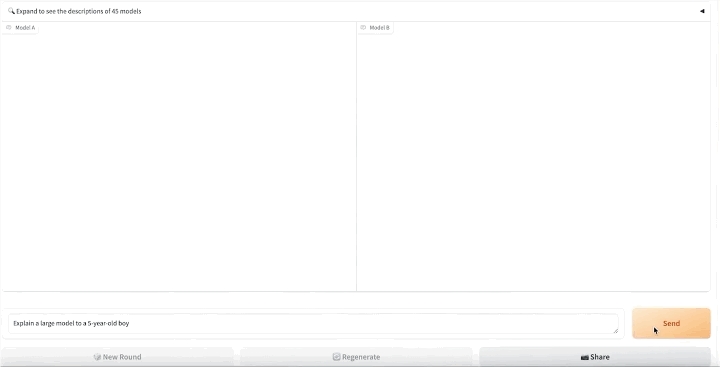
通过众筹真实用户来进行线上实时盲测和匿名投票,Chatbot Arena一方面减少偏见的影响,另一方面也最大概率避免基于测试集进行刷榜的可能性,以此增加最终成绩的客观性。在经过清洗和匿名化处理后,Chatbot Arena还会公开所有用户投票数据。
得益于「真实用户盲测投票」这一机制,Chatbot Arena被称为大模型业内最有用户体感的奥林匹克。
在收集真实用户投票数据之后,LMSYS Chatbot Arena还使用Elo评分系统来量化模型的表现,进一步优化评分机制,力求公平反应参与者的实力。
Elo评分系统,是一项基于统计学原理的权威性评价体系,由匈牙利裔美国物理学家Arpad Elo博士创立,旨在量化和评估各类对弈活动的竞技水平。
作为当前国际公认的竞技水平评估标准,Elo等级分制度在国际象棋、围棋、足球、篮球、电子竞技等运动中都发挥着至关重要的作用。
更通俗地来讲,在Elo评分系统中,每个参与者都会获得基准评分。每场比赛结束后,参与者的评分会基于比赛结果进行调整。系统会根据参与者评分来计算其赢得比赛的概率,一旦低分选手击败高分选手,那么低分选手就会获得较多的分数,反之则较少。
通过引入Elo评分系统,LMSYS Chatbot Arena在最大程度上保证了排名的客观公正。
Chatbot Arena的评测过程涵盖了从用户直接参与投票到盲测,再到大规模的投票和动态更新的评分机制等多个方面,这些因素共同作用,确保了评测的客观性、权威性和专业性。
毫无疑问,这样的评测方式能够更准确地反映出大模型在实际应用中的表现,为行业提供了一个可靠的参考标准。
Yi-Large以小搏大紧追国际第一阵营,登顶国内大模型盲测
此次Chatbot Arena共有44款模型参赛,既包含了顶尖开源模型Llama3-70B,也包含了各家大厂的闭源模型。
以最新公布的Elo评分来看,GPT-4o以1287分高居榜首,GPT-4Turbo、Gemini1.5Pro、Claude3Opus、Yi-Large等模型则以1240左右的评分位居第二梯队;其后的Bard(Gemini Pro)、Llama3-70B Instruct、Claude3Sonnet的成绩则断崖式下滑至1200分左右。
值得一提的是,排名前6的模型分别归属于海外巨头OpenAI、Google、Anthropic,零一万物位列全球第四机构,且GPT-4、Gemini1.5Pro等模型均为万亿级别超大参数规模的旗舰模型,其他模型也都在大几千亿参数级别。
Yi-Large「以小搏大」以仅仅千亿参数量级紧追其后,5月13日一经发布便冲上世界排名第七大模型,与海外大厂的旗舰模型处于同一梯队。
在LMSYS Chatbot Arena截至5月21日的总榜上,阿里巴巴的Qwen-Max大模型Elo分数为1186,排名第12;智谱AI的GLM-4大模型Elo分数为1175,排名第15。
在当前大模型步入商业应用的浪潮中,模型的实际性能亟需通过具体应用场景的严格考验,以证明其真正的价值和潜力。过去那种仅要求表面光鲜的「作秀式」评测方式已不再具有实际意义。
为了促进整个大模型行业的健康发展,整个行业必须追求一种更为客观、公正且权威的评估体系。
在这样的背景下,一个如Chatbot Arena这样能够提供真实用户反馈、采用盲测机制以避免操纵结果、并且能够持续更新评分体系的评测平台,显得尤为重要。它不仅能够为模型提供公正的评估,还能够通过大规模的用户参与,确保评测结果的真实性和权威性。
无论是出于自身模型能力迭代的考虑,还是立足于长期口碑的视角,大模型厂商应当积极参与到像Chatbot Arena这样的权威评测平台中,通过实际的用户反馈和专业的评测机制来证明其产品的竞争力。
这不仅有助于提升厂商自身的品牌形象和市场地位,也有助于推动整个行业的健康发展,促进技术创新和产品优化。相反,那些选择作秀式的评测方式,忽视真实应用效果的厂商,模型能力与市场需求之间的鸿沟会越发明显,最终将难以在激烈的市场竞争中立足。
参考资料:
LMSYS Chatbot Arena盲测竞技场公开投票地址:
https://arena.lmsys.org/
LMSYS Chatbot Leaderboard评测排行(滚动更新):
https://chat.lmsys.org/?leaderboard
- 0000
- 0000
- 0003
- 0000
- 0001



