腾讯开源DiT 图像生成模型 可根据对话上下文生成并细化图像
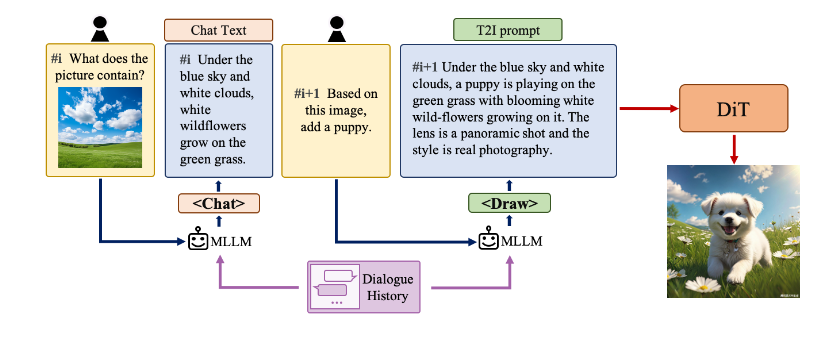
腾讯开源了混元 DiT 图像生成模型,对英语和中文都有着精细的理解能力。Hunyuan-DiT能够进行多轮多模态对话,根据对话上下文生成并细化图像。
Hunyuan-DiT是一种强大的多分辨率扩散变换器,具有细粒度的中文理解能力。它结合了Transformer结构、文本编码和位置编码,并通过训练一个多模态大型语言型来改进图像的描述,从而实现了对中英文的细粒度理解。通过建立完整的数据管道,可以对模型进行迭代优化。
项目地址:https://github.com/Tencent/HunyuanDiT
在Hunyuan-DiT中,采用了Transformer结构,结构在自然语言处理领域取得了巨大的成功。通过多层的自注意力机制和前馈神经网络,Transformer可以有效地捕捉文本之间的关系和上下文信息。
为了更好地理解中文,Hun-DiT采用了文本编码和位置编码。文本编码使用了预训练的词嵌入模型,将文本转化为向量表示。位置编码则是为了捕捉文本中的位置信息,通过给不同的词语分配不同的编码,使得模型能够感知词语的位置关系。
为了改进图像描述,Hunyuan-DiT训练了一个多模态大型语言模型。该模型通过学习文本和图像间的关联,可以生成更准确、更具描述性的图像描述。通过将这个模型与扩散变换器相结合,Hunyuan-DiT可以实现多轮的多模态文本到图像的生成。
Hunyuan-DiT的应用前景非常广泛。它可以用于自然语言处理、图像生成等领域,为这些任务提供了一个强大的工具。同时,Hunyuan-DiT还可以应用于文本编辑、文档生成等任务,提高文本的质量和确性。
综上述,Hunyuan-DiT是一种强大的多分辨率扩散变换器,具有细粒度的中文理解能力。它通过结合Transformer结构、文本编码和位置编码,以及训练一个多模态大型语言型,实现了对中英文的细粒度理解,并在图像生成等任务中取得了显著的效果。
- 0000
- 0000

 0008
0008- 0000
- 0000


