FastGen:在不降低LLM质量的情况下降低GPU内存成本
划重点:
- ⭐FastGen 一种高效的技术,可以提高 LLM 的推理效率,而不会降低可见质量。
- ⭐FastGen 轻量级模型分析和自适应键值缓存来实现。
- ⭐FastGen 通过自适应的键值缓存构造来少生成推理过程中的 GPU 内存使用量。
研究人员来自伊利诺伊大学厄巴纳 - 香槟分校和微软提出了一种名为 FastGen 的高效技术,通过使用轻量级模型分析和自适应键值缓来提高 LLM 的推理效率,而不会降低可见质量。FastGen 通过自适应的键值缓存构造来减少生成推理过程中的 GPU 内存使用量。
FastGen 的自适应键值缓存压缩方法减小了 LLM 生成推理内存占用。该方法涉及两个步骤:
1. 提示编码:注意模块需要从前面的 i-1标记中收集上下文信息,以生成 LLM 的第 i 个标记。
2. 令牌生成:当完成提示编码后,M 逐个标记生成输出,对于每个步骤,使用 LLM 对上一步生成的新标记进行编码。
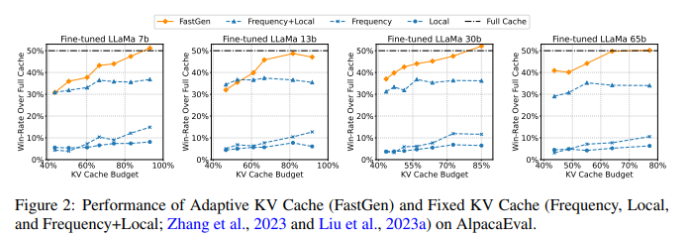
对于 B 模型,FastGen 在所有非自适应键值缓存压缩方法中表现最佳,并随着模型规模的增加而得更高的键值缓存压缩比例,同时保持模型的质量不受影响。例如,与 Llama17B 上的16.9% 压缩比例相比,FastGen 在 Llama1-65B 上获得了44.9% 的缩比例,达到了45% 的胜率。此外,对 FastGen 进行了敏感性分析,选择了不同的超。由于模型保持45% 的胜率,研究表明在更改超参数后对生成质量没有明显影响。
伊利诺伊大学厄巴纳 - 香槟分校和微软的研究人员提出了 FastGen,一种新的技,通过使用轻量级模型分析和自适应键值缓存来提高 LLM 的推理效率,而不会降低见质量。研究人员引入的自适应键值缓存压缩通过 FastGen 构建,以减少 LLM 生成推的内存占用。未来的工作包括将 FastGen 与其他模型压缩方法(如量化和蒸馏、分组查询注意等)进行整合。
论文地址:https://arxiv.org/abs/2310.01801
- 0000
- 0000


 0000
0000- 0000
- 0000