清华首个AI医院小镇来了!AI医生自进化击败人类专家,数天诊完1万名患者
【新智元导读】清华团队竟把医院搬进了AI世界!首个AI医院小镇——Agent Hospital,可以完全模拟医患看病的全流程。更重要的是,AI医生可以自主进化,仅用几天的时间治疗大约1万名患者。
斯坦福AI小镇曾火遍了全网,25个智能体生活交友,堪称现实版的「西部世界」。
而现在,AI「医院小镇」也来了!
最近,来自清华团队的研究人员开发了一个名为「Agent Hospital」的模拟医院。
论文地址:https://arxiv.org/pdf/2405.02957
在这个虚拟世界中,所有的医生、护士、患者都是由LLM驱动的智能体,可以自主交互。
它们模拟了整个诊病看病的过程,包括分诊、挂号、咨询、检查、诊断、治疗、随访等环节。
而在这项研究中,作者的核心目标是,让AI医生学会在模拟环境中治疗疾病,并且能够实现自主进化。
由此,他们开发了一种MedAgent-Zero系统,能够让医生智能体,不断从成功和失败的病例积累经验。
值得一提的是,AI医生可以在几天内完成对1万名患者的治疗。
而人类医生需要2年的时间,才能达到类似的水平。
另外,进化后的医生智能体,在涵盖主要呼吸道疾病的MedQA数据集子集上,实现高达93.06%的最新准确率。
不得不说,AI进化在虚拟世界中默默进化,真有淘汰人类之势。
有网友表示,「AI模拟将探索人类根本没有时间,或能力探索的道路」。

想象一下,数千家全自动化医院,将会拯救数百万人的生命。这很快就会到来。
首个AI医院小镇登场
其实,智能体,早已成为业界看好的一个领域。
不论是在虚拟世界中的模拟,还是能够解决实际任务(比如Devin)的智能体,都将给我们世界带来巨变。
然而,这些多智能体通常用于「社会模拟」,或者「解决问题」。
那么,是否有将这两种能力结合起来的智能体?
也就是说,社会模拟过程能否,提升LLM智能体在特定任务的表现?
受此启发,研究人员开发了一个几乎涵盖所有医学领域的治疗流程的模拟。


如同单机游戏《主题医院》的世界
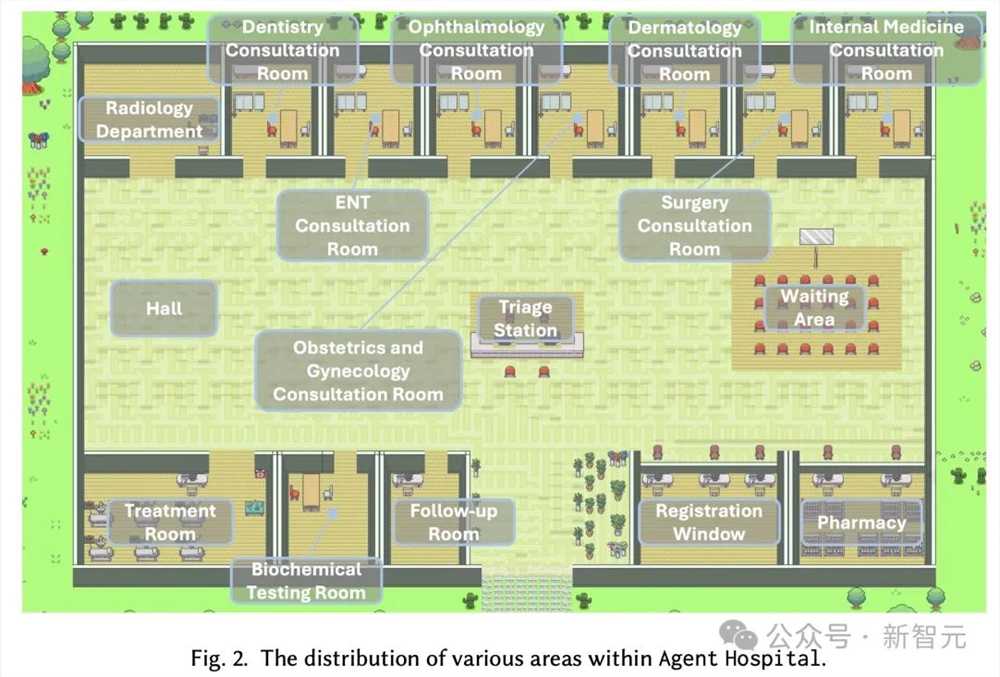
Agent Hospital中模拟的环境,主要有两类主体:一是患者,一是医疗专业人员。
它们的角色信息,都是由GPT-3.5生成,可以无限扩展。
比如,下图中,35岁患者Kenneth Morgan有急性鼻炎,而他的病史是高血压,目前的症状是持续呕吐,有些腹泻、反复发烧、腹痛、头痛,而且颈淋巴结肿大。
再来看32岁内科医生Elise Martin,具备了出色的沟通能力,以及富有同理心的护理能力。
她主要的职责是,为患有各种急性病和慢性病的成年患者提供诊断、治疗和预防保健服务。
ZhaoLei是一位擅长解读医学图像的放射科医生,还有前台接待员Fatoumata Diawara。

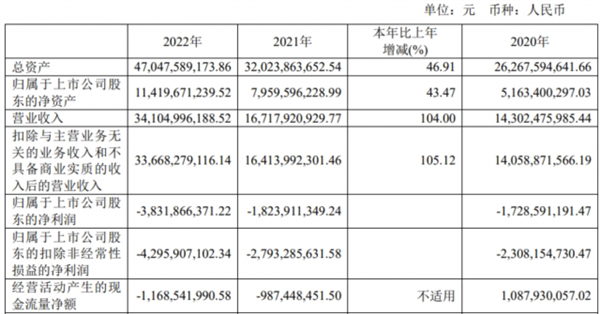
下图中展示的是,Agent Hospital内有各种问诊室和检查室,因此需要一系列医疗专业智能体工作。
研究人员设计了,14名医生和4名护士。
医生智能体被设计来诊断疾病并制定详细的治疗计划,而护理智能体则专注于分诊,支持日常治疗干预。
AI患者如何看病?
与真实世界看病的流程一样,当患者生病后,就会去医院挂号就诊。
在此期间,它们还会经历一系列阶段,包括检查、分诊、会诊、诊断、治疗。
患者在拿到治疗方案后,LLM会帮助预测患者的健康状况变化。一旦康复,它便会主动向医院汇报进行随访。
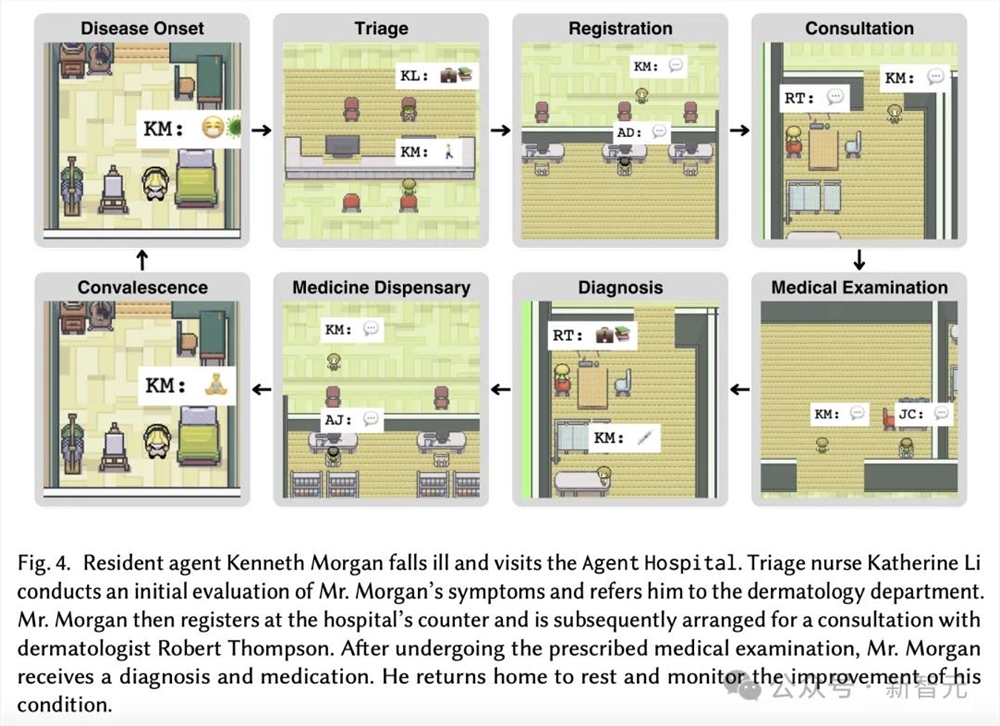
如下是Kenneth Morgan前往医院就诊的示意图。
首先是,分诊护士Katherine Li对Morgan进行了初步的评估,并将他分诊到皮肤科就诊。
随后,Morgan在医院柜台进行登记,被安排与皮肤科医生Robert Thompson进行会诊。
在完成规定的体检之后,AI医生为Morgan开出药物治疗,并敦促回家休息,同时还要监测病情的改善情况。
AI医生自我超进化,无需手动标记数据
在模拟环境中,研究人员希望训练一个熟练的医生智能体,来处理诸如诊断、治疗等医疗任务。
传统的方法是,将巨量的医学数据喂给LLM/智能体,经过预训练、微调、RAG之后,以构建强大的医学模型。
最新研究中,作者提出了一种新策略——在虚拟环境中模拟医患互动,来训练医生智能体。
在这个过程中,研究人员没有使用手动标记数据,因此最新系统被命名为MedAgent-Zero。
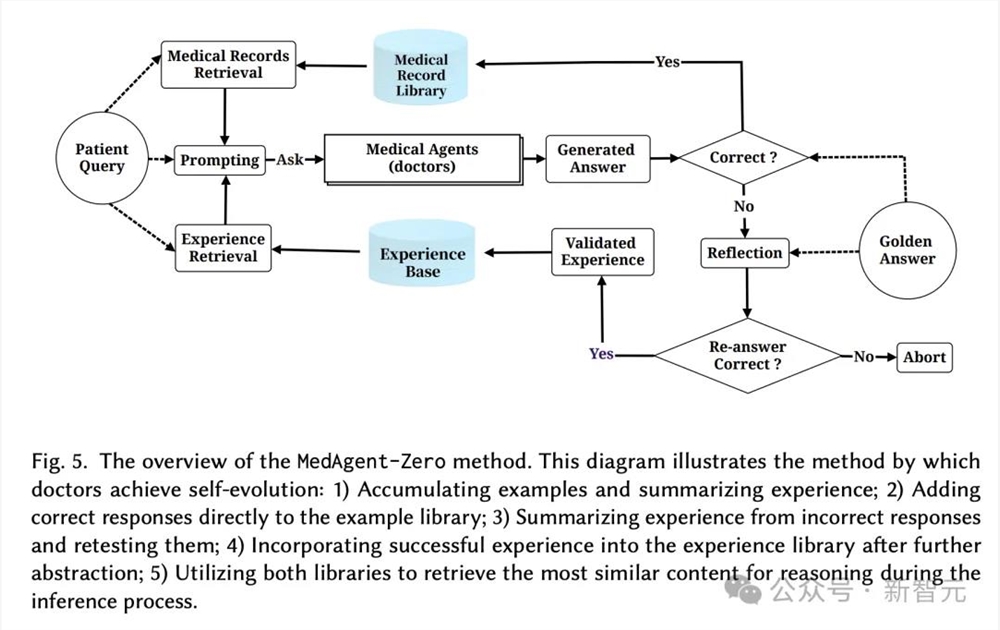
这一策略包含了两个重要的模块,即「病历库」和「经验库」。
诊疗成功的案例被整理,并存储在病历库中,作为今后医疗干预的参考。
而对于治疗失败的情况,AI医生有责任反思、分析诊断不正确的原因,总结出指导原则,作为后续治疗过程中的警示。
简言之,MedAgent-Zero可以让生智能体通过与患者智能体互动。
通过积累成功案例的记录,和从失败案例中获得经验,进化成更优秀的「医生」。
整个自我进化流程如下:
1)积累实例,总结经验;
2)直接向示例库添加正确的响应;
3)总结错误的经验,并重新测试;
4)将成功经验进一步抽象后,纳入经验库;
5)在推理过程中利用两个库检索最相似的内容进行推理。
难得的是,由于训练成本低,效率高,医生智能体可以轻松应对数十种情况。
比如,智能体可以在短短几天内处理数万个病例,而现实世界的医生需要几年的时间才能完成。
诊断呼吸疾病,准确率高达93.06%
接下来,研究人员进行了两类实验,来验证MedAgent-Zero策略改进的医生智能体,在医院中的有效性。
一方面,在虚拟医院内,作者们进行了从100-10000个智能体的交互实验(人类医生一周可能会治疗约100名病人),涵盖了8种不同的呼吸疾病、十几种医疗检查,以及每种疾病的三种不同治疗方案。
通过MedAgent-Zero策略训练的医生智能体,在处理模拟病人的过程中不断自我进化,最终在检查、诊断和治疗任务中的准确率分别达到了88%、95.6%和77.6%。
随着样本的不断扩增,MedAgent-Zero的训练性能,在达到一定量时趋于平稳。
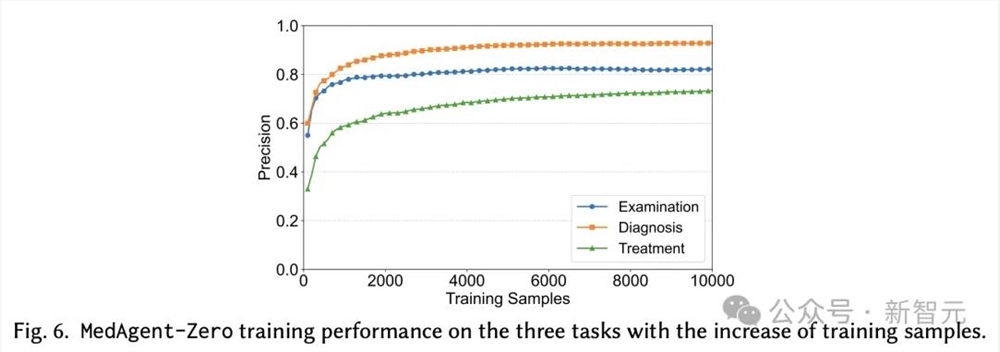
在检查、诊断、治疗三个任务方面上的性能,MedAgent-Zero也随着样本增加,不断波动,但整体准确性呈现出上升趋势。
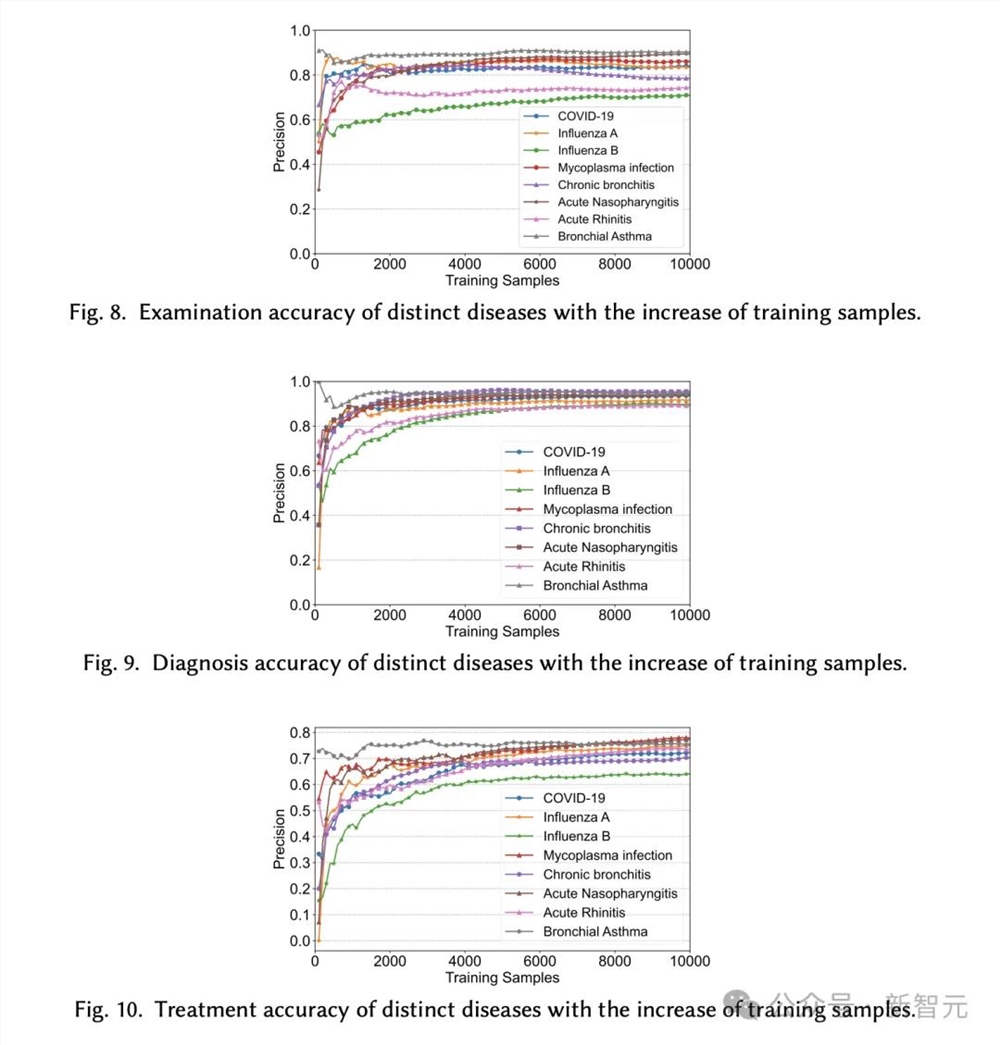
诊断呼吸疾病,准确率高达93.06%
再看如下三张图,分别展示了不同疾病的检查精度、诊断精确度、以及治疗精度,随着样本的增加,也在平稳攀升。
另一方面,研究者让进化后的医生智能体,参加了对MedQA数据集子集的评估。
令人惊讶的是,即使没有任何手动标注的数据,医生智能体在Agent Hospital中进化后,也实现了最先进的性能。
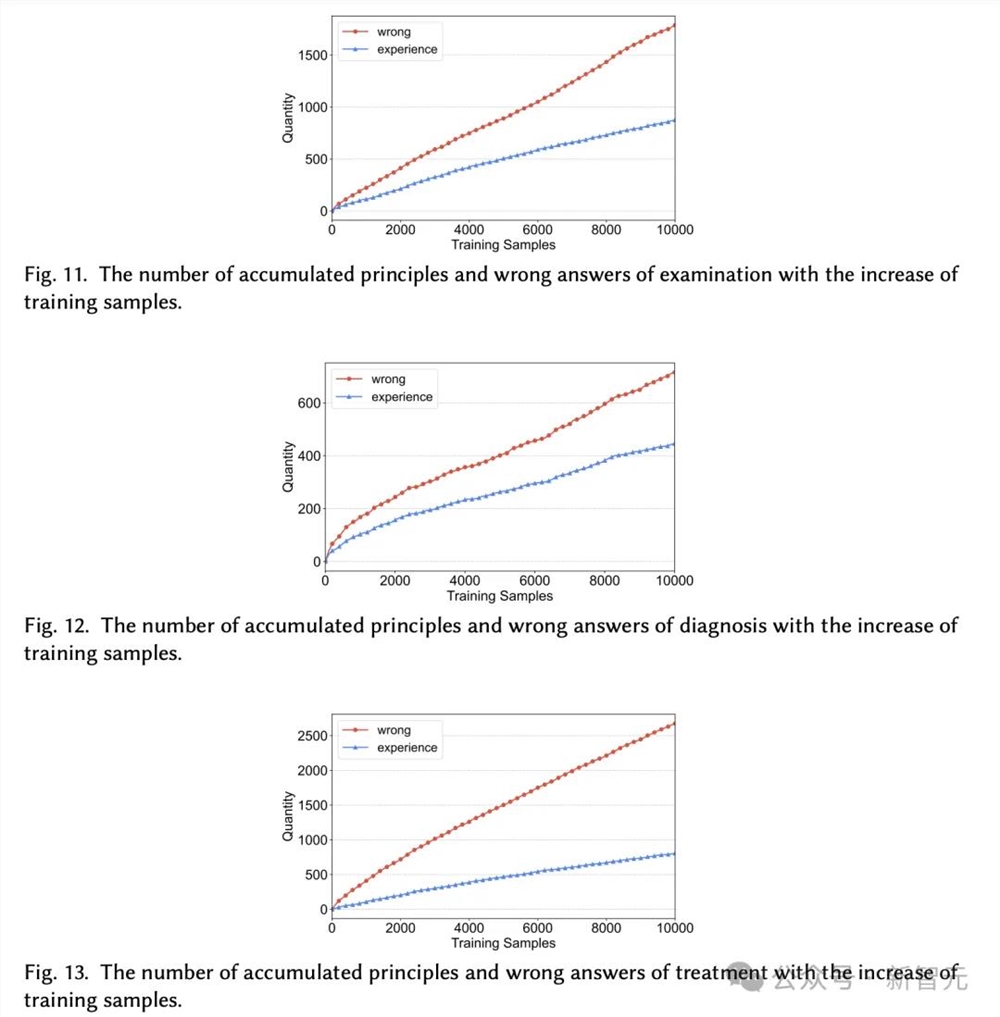
在经验积累上,图11、图12和图13分别显示了,检查、诊断和治疗任务中,经过验证经验和错误答案的积累。
当训练样本增加时,经验数和错误答案数都缓慢增加。
如图所示,经验曲线低于错误答案曲线,原因是智能体无法反映所有失败的经验。此外,诊断经验比其他任务更容易积累。
一起来看个案例研究。
下表中说明了,经验库、病理库和MedAgent-Zero,在患者诊疗中的三个任务上的性能。
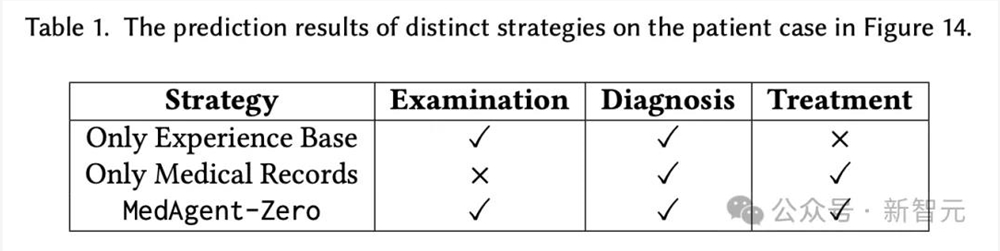
在得知病人症状之后,AI医生不仅需要使用病历库,同时还需要经验库,也就是相辅相成。
若是少了其中的一方,便会导致诊断准确性的下降。
如下,通过添加经验和记录,MedAgent-Zero针对所有3个任务都给出了正确的回答。

以上结果表明,模拟环境可以有效地帮助LLM智能体在处理特定任务时完成进化。
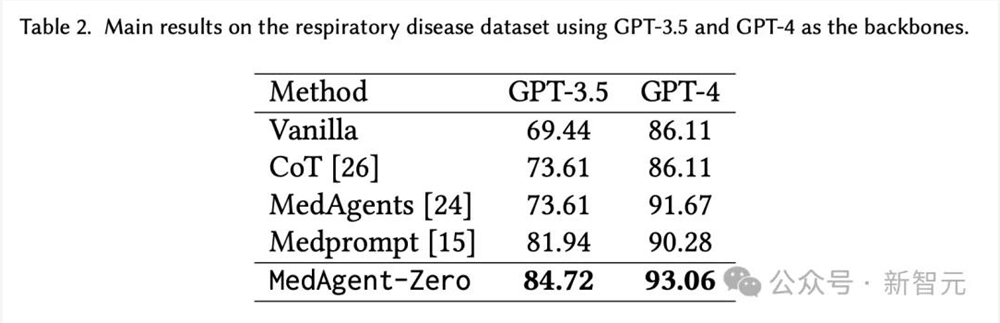
MedAgent-Zero在使用GPT-3.5时,比SOTA方法Medprompt高出2.78%,在使用GPT-4时比SOTA方法MedAgents高出1.39%。
这一结果验证了新模型有助于,在没有任何MedQA训练样本的情况下,仅使用模拟文档和医疗文档进行智能体进化,从而有效提高医生智能体的医疗能力。
其次,基于GPT-4的MedAgent-Zero的最佳性能为93.06%,优于MedQA数据集中的人类专家(约87%)。
第三,基于GPT-4的医生智能体比基于GPT-3.5的任何其他方法都表现得更出色,这表明GPT-4在医疗领域更强大。
另外,在对MedAgent-Zero进行的消融研究中,
同时利用「病历库」和「经验库」的MedAgent-Zero取得了最佳性能,表明这两个模块对诊断的帮助。
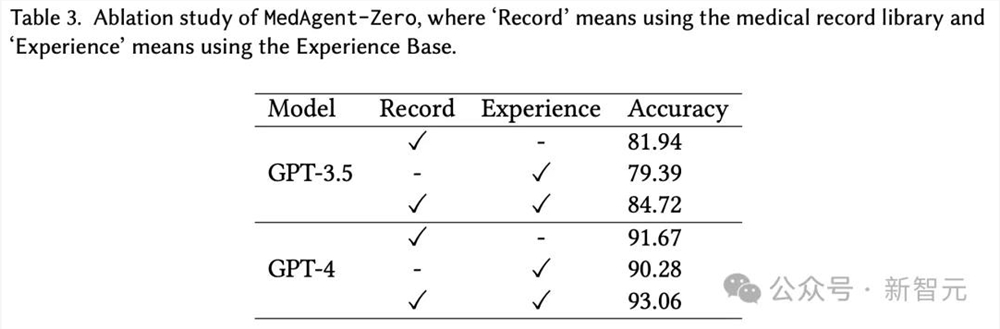
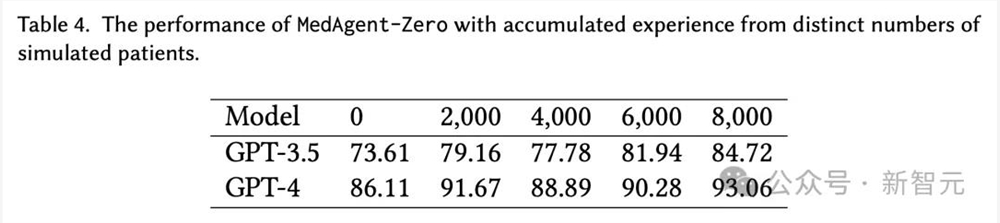
随着病例的积累和经验库的扩大,医生智能体准确率总体上越来越高。
无论是使用GPT-3.5还是 GPT-4,使用8000个病例积累的经验库,其性能都高于使用2000/4000/6000个病例的性能。
不过,经验库越大并不总是越好,因为研究者还发现在2,000-4,000个案例之间有明显的下降。
局限性
最后,研究人员还提到了这项研究的局限性。
- 只采用GPT-3.5作为Agent Hospital和评估的模拟器
- 由于智能体之间的交互及其演化涉及API调用,AI医院的运作效率受到LLM生成的限制
- 每个患者的健康记录和检查结果,是在没有领域知识的情况下,模拟真实的电子健康记录生成的,但仍与现实世界的记录仍存在一些差异。
在未来,研究者们对Agent Hospital的计划将会包括:
第一,扩大规模覆盖的疾病范围,延伸到更多的医疗科室,旨在反映真实医院提供的全面服务,以供进一步研究。
第二,在加强智能体社会模拟方面,比如纳入医疗专业人员的全面晋升制度、随时间改变疾病的分布、纳入病人的历史病历等。
第三,优化基础LLM的选择和实施,旨在通过利用功能强大的开源模型,更高效地执行整个模拟过程。
参考资料:
https://x.com/emollick/status/1787896361276571660
- 0000
- 0000
- 0000
- 0000
- 0000