StoryDiffusion:保持角色一致,可生成多图漫画和长视频
站长网2024-05-06 20:36:040阅
划重点:
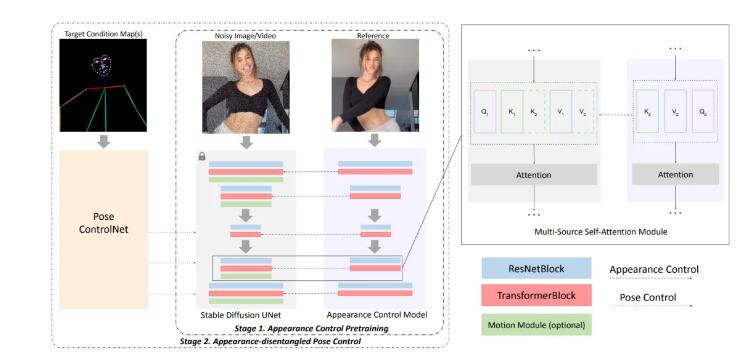
🔮 Consistent self-attention 实现角色连贯图像生成
🎥 Motion predictor 实现长视频生成
🎨支持漫画生成、图像转视频、长短视频等多种内容生成功能
南开大学 HVision 团队开发了 StoryDiffusion,一款能够创造神奇故事的工具。StoryDiffusion可以保持角色一致,生成多图漫画和长视频。

该工具通过实现 Consistent self-attention 和 Motion predictor,能够生成连贯的图像和视频。用户可以提供文本提示来生成角色连贯的图像序列,同时也能实现长视频生成,预测不同条件图像之间的运动,实现更大幅度的运动预测。
StoryDiffusion 的应用范围广泛,可用于漫画生成、图像转视频等多种场景。通过 Consistent self-attention 机制生成的图像,可以顺利过渡为视频,实现两阶段长视频生成方法。此外,结合两个部分,还能生成常长且高质量的 AIGC 视频。

用户可以通过提供一系列用户输入的条件图像,使用 Image-to-Video 模型生成视频。此外,用户可以通过 Jupyter notebook 或本地 adio demo 来生成漫画。目前,该项目发布了生成漫画部分的源码。
产品入口:https://top.aibase.com/tool/storydiffusion
试玩入口:https://huggingface.co/spaces/YupengZhou/StoryDiffusion
0000
评论列表
共(0)条相关推荐


 0000
0000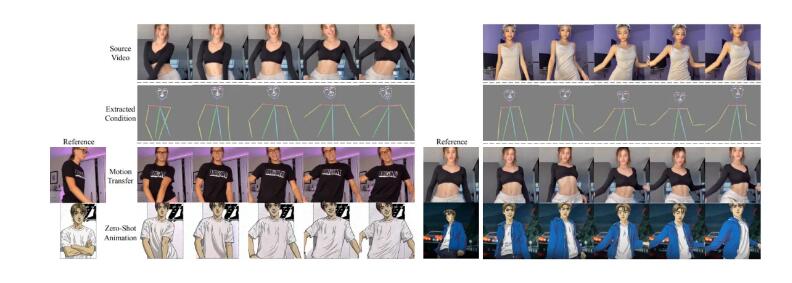
 0001
0001
 0000
0000- 0000
- 0000