LLaVA++:为Phi-3和Llama-3模型增加视觉处理能力
站长网2024-04-28 16:57:260阅
LLaVA 项目通过扩展现有的LLaVA模型,成功地为LLaVA 和Llama-3模型赋予了视觉能力。这一改进标志着AI在多模态交互领域的进一步发展。
主要创新点包括:
模型整合: LLaVA 将Phi-3和Llama-3模型进行整合,创建了具备视觉处理能力的Phi-3-V和Llama-3-V版本。
图像理解与生成: 新模型不仅能够理解与图像相关的内容,还能生成视觉内容,扩展了模型的应用范围。
复杂指令执行: 增强的视觉处理能力使得模型能够更准确地理解和执行与视觉内容相关的复杂指令。
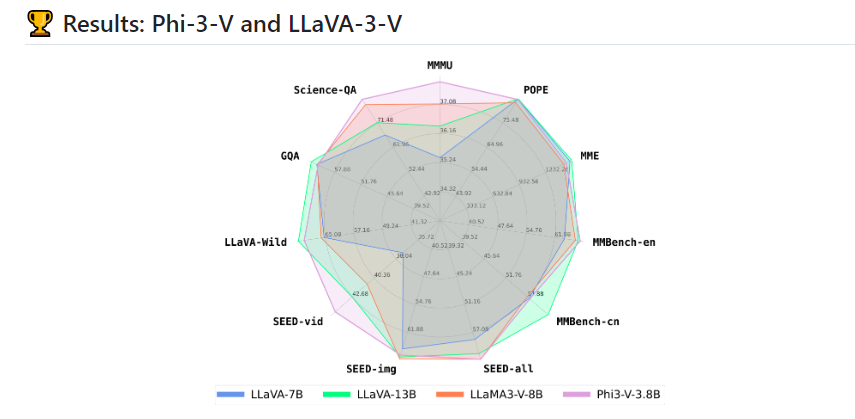
学术任务处理: 在需要同时理解图像和文本的学术任务中,LLaVA 展现了更高的准确率和效率,提升了模型的学术研究和教育应用潜力。
LLaVA 的优势:
通过赋予Phi-3和Llama-3视觉能力,LLaVA 项目不仅提升了AI模型的多模态交互能力,还为图像识别、视觉问答、视觉内容创作等领域带来了新的机遇。这种跨模态的能力增强,使得AI模型在执行需要视觉和文本结合的任务时更加得心应手。
LLaVA 的推出,预示着未来AI模型将更加智能和灵活,能够更好地服务于需要视觉与文本结合理解的复杂场景。
项目地址:https://top.aibase.com/tool/llava-
0000
评论列表
共(0)条相关推荐
- 0000
 0001
0001- 0003
- 0000
- 0001