Hugging Face 发布医疗任务评估基准Open Medical-LLM
划重点:
⭐️ Hugging Face 发布了一个新的医疗任务评估基准,旨在测试生成式人工智能模型在健康相关任务上的表现。
⭐️ Open Medical-LLM 基准由现有测试集拼接而成,涵盖多个医学领域,如解剖学、药理学、遗传学和临床实践。
⭐️ 一些医学专家对 Open Medical-LLM 提出了警告,强调实际临床实践与医学问题回答之间存在较大差距,强调基准测试结果不能替代真实世界测试。
近期,Hugging Face 发布了一项名为 Open Medical-LLM 的新基准测试,旨在评估生成式人工智能模型在健康相关任务上的表现。
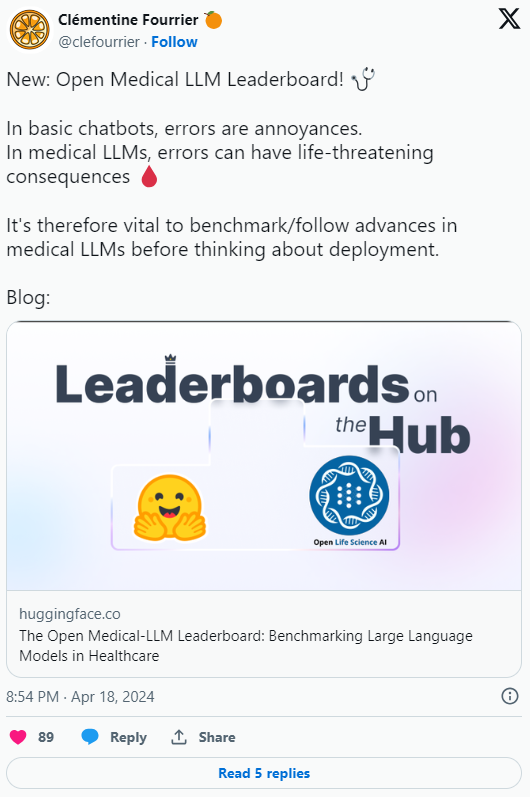
该基准由 Hugging Face 与非营利组织 Open Life Science AI 和爱丁堡大学自然语言处理小组的研究人员合作创建。Open Medical-LLM 的目标是标准化评估生成式人工智能模型在一系列医学相关任务上的性能。
Open Medical-LLM 并非从零开始的基准测试,而是由现有测试集(如 MedQA、PubMedQA、MedMCQA 等)拼接而成,涵盖多个医学领域,如解剖学、药理学、遗传学和临床实践。基准测试包含多项选择和开放性问题,需要医学推理和理解,涵盖了美国和印度的医学执照考试以及大学生物学测试题库的内容。
尽管 Hugging Face 将该基准视为医疗界生成式人工智能模型的 “健全评估”,但一些医学专家在社交媒体上对 Open Medical-LLM 提出了警告,指出实际临床实践与医学问题回答之间存在较大差距。他们强调,基准测试结果不能替代在真实世界条件下的仔细测试。

对此,Hugging Face 的研究科学家克莱门汀・弗里尔(Clémentine Fourrier)在社交媒体上表示,这些排行榜只能作为探索特定用例的第一近似值,但实际上需要进行更深入的测试阶段,以检查模型在真实条件下的局限性和相关性。她指出,医学模型绝不能单独由患者使用,而应该被训练成为医生的支持工具。
尽管 Open Medical-LLM 等基准测试具有一定的参考意义,但结果排行榜也反映出模型在回答基本健康问题时表现不佳。然而,Open Medical-LLM 和其他任何基准测试都不能替代经过深思熟虑的真实世界测试。例如,谷歌曾试图将用于糖尿病视网膜病变筛查的人工智能工具引入泰国的医疗系统,但尽管理论上准确度很高,该工具在实际测试中却表现不佳,导致患者和护士对其结果的不一致性感到沮丧,与实际临床实践缺乏协调性。
至今,美国食品药品监督管理局已批准的139个与人工智能相关的医疗设备中,没有一个使用生成式人工智能。测试生成式人工智能工具在实验室中的性能如何转化为医院和门诊诊所的实际情况,以及这些结果可能随时间变化的趋势,都是异常困难的。
官方博客:https://huggingface.co/blog/leaderboard-medicalllm
- 0000
- 0000
- 0000


 0001
0001- 0000