通义千问开源基于Qwen1.5的代码模型CodeQwen1.5
通义千问昨晚开源了基于Qwen1.5的代码模型CodeQwen1.5,这是一个基于 Qwen 语言模型的代码专家模型。CodeQwen1.5拥有7B 参数,采用 GQA 架构,经过约3T tokens 代码数据的预训练,支持92种编程语言,并且能够处理最长64K 的上下文输入。
在代码生成、长序列建模、代码修改和 SQL 能力等方面,CodeQwen1.5展现出了卓越的性能,极大地提升了开发人员的工作效率,并简化了软件开发流程。
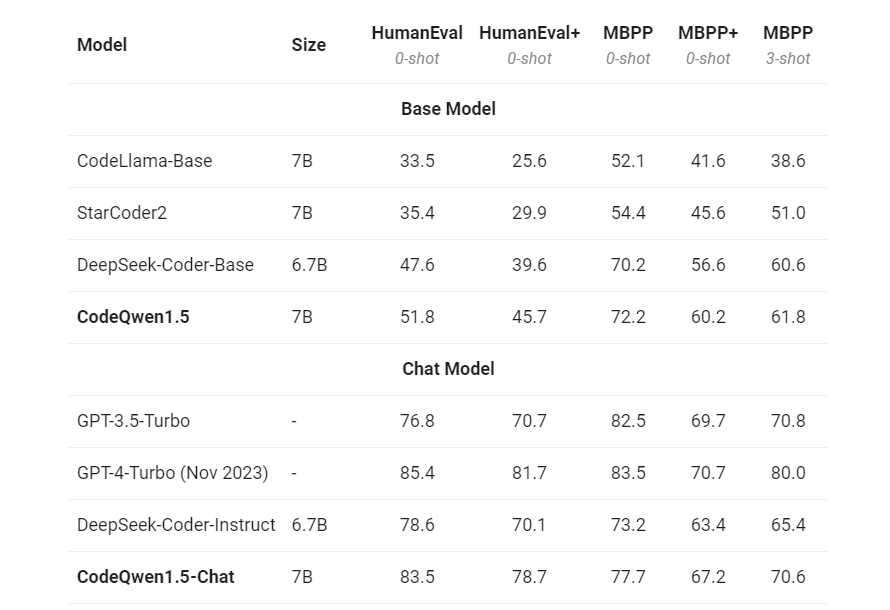
在代码生成方面,CodeQwen1.5已经超越了许多更大尺寸的模型,缩小了开源 CodeLLM 与 GPT-4之间在编码能力上的差距。通过 HumanEval 和 MBPP 的评估,CodeQwen1.5在各项指标上均表现出色。
此外,LiveCodeBench 的评估显示,CodeQwen1.5在 LeetCode、AtCoder 和 CodeForces 三个竞赛平台的问题上具有极强的泛化能力,尽管其预训练语料中包含了 LeetCode 的数据。
CodeQwen1.5不仅精通 Python,还支持多种编程语言。在 MultiPL-E 的8种主流语言上进行全面评估,CodeQwen1.5证明了其多语言编程的卓越能力。长序列能力对于代码模型至关重要,CodeQwen1.5通过精心构造的长序列代码数据预训练,实现了最长64K 输入长度的支持。
在实际应用方面,CodeQwen1.5在 SWE Bench 上的表现尤为突出,它能够理解代码仓库并生成可通过单测的代码,解决了真实软件开发中的问题。
CodeQwen1.5在代码修改方面的能力也得到了验证,它在 CodeEditorBench 的四个方面——Debug、Translate、Switch、Polish——均达到了最佳效果。
作为一个智能的 SQL 专家,CodeQwen1.5通过自然语言查询数据库,极大地降低了非编程专业人士与高效数据交互之间的学习曲线。在 Spider 和 Bird 两个流行的文本到 SQL 基准测试中,CodeQwen1.5的性能接近 GPT-4,显示了其在 SQL 领域的强大实力。
CodeQwen1.5作为 Qwen1.5开源家族的一员,目前已支持多种平台和工具,如 Transformers, vLLM, llama.cpp, Ollama 等。开源社区对 CodeQwen1.5的发布充满期待,希望它在代码助手、Code Agent 等方面为社区做出贡献,并在未来的代码智能建设中发挥重要作用,实现真正的 AI 程序员。
详细模型介绍:https://qwenlm.github.io/zh/blog/codeqwen1.5/
- 0000
- 0000

 0000
0000- 0000
- 0000