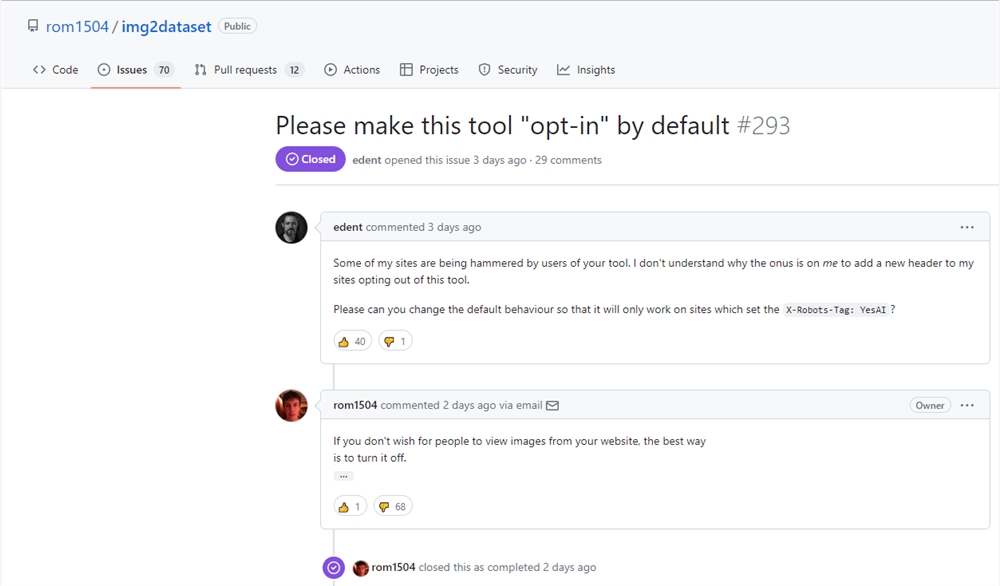
OpenAI 的 ChatGPT 通过新的放射学委员会考试:病患更喜欢 AI 的回答 更具同情心
OpenAI 的 ChatGPT 正在通过医学考试,两项最新研究表明,这一次 ChatGPT 在放射学考试中取得了及格分数。

研究人员将 ChatGPT 的 GPT-3.5 版本和 GPT-4 版本评估了放射学考试的 150 个问题。他们发现,在两个版本中,AI 的聊天机器人从 69.3% 的接近及格的分数提高到了 80.7%,在高级别思维问题中表现更为出色,特别是在描述影像发现和应用医学概念方面,GPT-4 版本的表现更好。
这些问题是基于文本的选择题,分为两个大类(高级和低级),以评估技术在回答问题方面的具体优势和劣势。这些问题被选中以匹配加拿大皇家学院和美国放射学委员会考试的风格、内容和难度。
ChatGPT 在医学考试中的应用已经成为一种常见现象。自 ChatGPT 在 2022 年 11 月 30 日发布以来,通过医学认证考试一直是 AI 开发人员的长期目标,尤其是谷歌的医学重点大语言模型(LLM)Med-PaLM。
自当月以来,参与 AI 测试使用于医学认证的研究已成为一种常见实践,特别是通过 ChatGPT 的性能来提升在医学领域的应用。医学认证考试成为了 AI 开发的一个长期目标。
在 2022 年 12 月,研究人员展示了 Med-PaLM 在美国医疗许可考试(USMLE)上获得了 67.6% 的准确率,这是及格分数的普遍门槛,这是 AI 在医学上功能的一个重大里程碑,类似于人工智能在多年中与国际象棋大师的竞争。
此外,ChatGPT 最近还接受了评估其回答患者问题的能力。在与真实医生回答的比较中,经过盲评估的评价者在 75% 以上的时间内更喜欢 ChatGPT 的回答。与医生的回答相比,该 AI 聊天机器人的回答也被评为更具有同情心。
总的来说,现在 AI 模型在医学上能做什么和不能做什么的努力是一个设定基准的过程。Bhayana 表示,目前的重点是确定 ChatGPT 和其他 AI 模型可以在医学上如何使用,但他警告说,由于这些技术往往会「幻觉」或说谎(通常非常自信),因此应用是有限制的。然而,他希望技术能够不断改进,以实现在医学上更广泛的应用。
目标是了解医生可以信任这些工具的程度,然后开始着手改进和优化这些模型,以适用于特定的临床用途。目前,生成式 AI 已经表明在某些用途上是高效的,例如听写和转录,但 Bhayana 认为,在医学上医生将能够信任这些工具,需要更多时间和更新。
他表示:「随着这些工具的出现,重点在于了解它们的性能,寻找它们的应用,并确保人们知道它们的优点和限制,以便医生与技术共同发展。」
- 0000
- 0002
- 0000
- 0000

 0000
0000