MathVerse:全方位可视化数学基准,对多模态大型语言模型进行公平和深入的评估
划重点:
🔍 MLLMs在视觉情境下的表现异常出色,但解决视觉数学问题的能力仍需全面评估和理解。
🔍 MATHVERSE提出了一个创新性的基准,旨在严格评估MLLMs在解释数学问题中的视觉信息理解能力。
🔍 研究发现大多数现有模型需要视觉输入来理解数学图表,甚至可能表现更好,这表明需要更先进的数学专用视觉编码器。
多模态大型语言模型(MLLMs)在视觉情境下的表现异常出色,引起了广泛关注。然而,它们解决视觉数学问题的能力仍需全面评估和理解。数学常常在理解复杂概念和解释解决问题所需的视觉信息方面存在挑战。在教育和其他领域中,解读图表和插图变得至关重要,尤其是在解决数学问题时。
GeoQA和MathVista等框架试图弥合文本内容与视觉解释之间的差距,专注于几何查询和更广泛的数学概念。这些模型,包括SPHINX和GPT-4V,旨在通过解决各种挑战,从几何问题解决到理解复杂图表,来增强多模态理解能力。尽管它们取得了进展,但在数学推理的文本分析与准确视觉解释之间实现无缝整合的全面方法仍然是一个尚未完全征服的前沿领域。
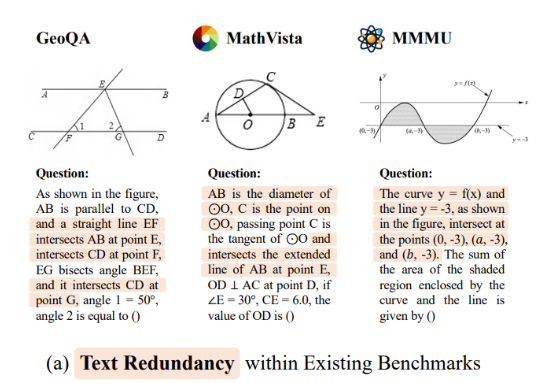
来自香港中文大学多媒体实验室和上海人工智能实验室的研究团队提出了“MATHVERSE”,这是一个创新性的基准,旨在严格评估MLLMs在解释数学问题中的视觉信息理解能力。该方法引入了各种数学问题,其中包含图表,以测试模型在文本推理之外的理解能力。
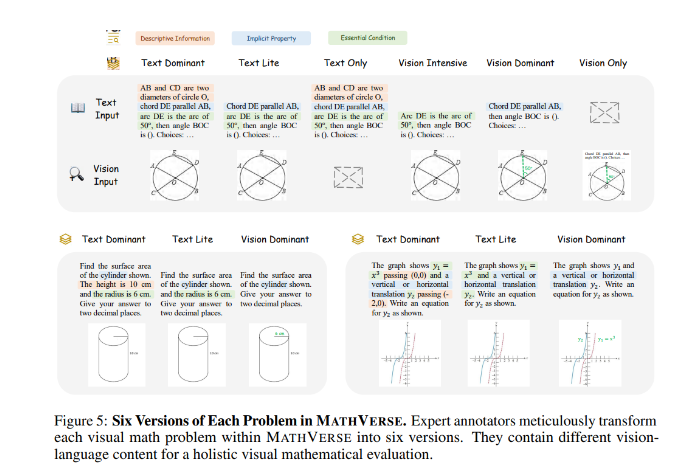
MATHVERSE通过2612个数学问题与图表,挑战视觉数据处理。研究人员将这些问题精心调整为六种不同的格式,从以文本为主到仅以视觉为主,以解剖MLLMs的多模态分析技能。性能分析显示出不同的成功程度;当剥夺了视觉线索时,一些模型的准确性竟然提高了超过5%,暗示了对文本的更强依赖性。特别是,GPT-4V展示了在文本和视觉模态中的平衡熟练度,为当前MLLMs在处理视觉和数学查询方面的能力和局限性提供了全面的洞察。
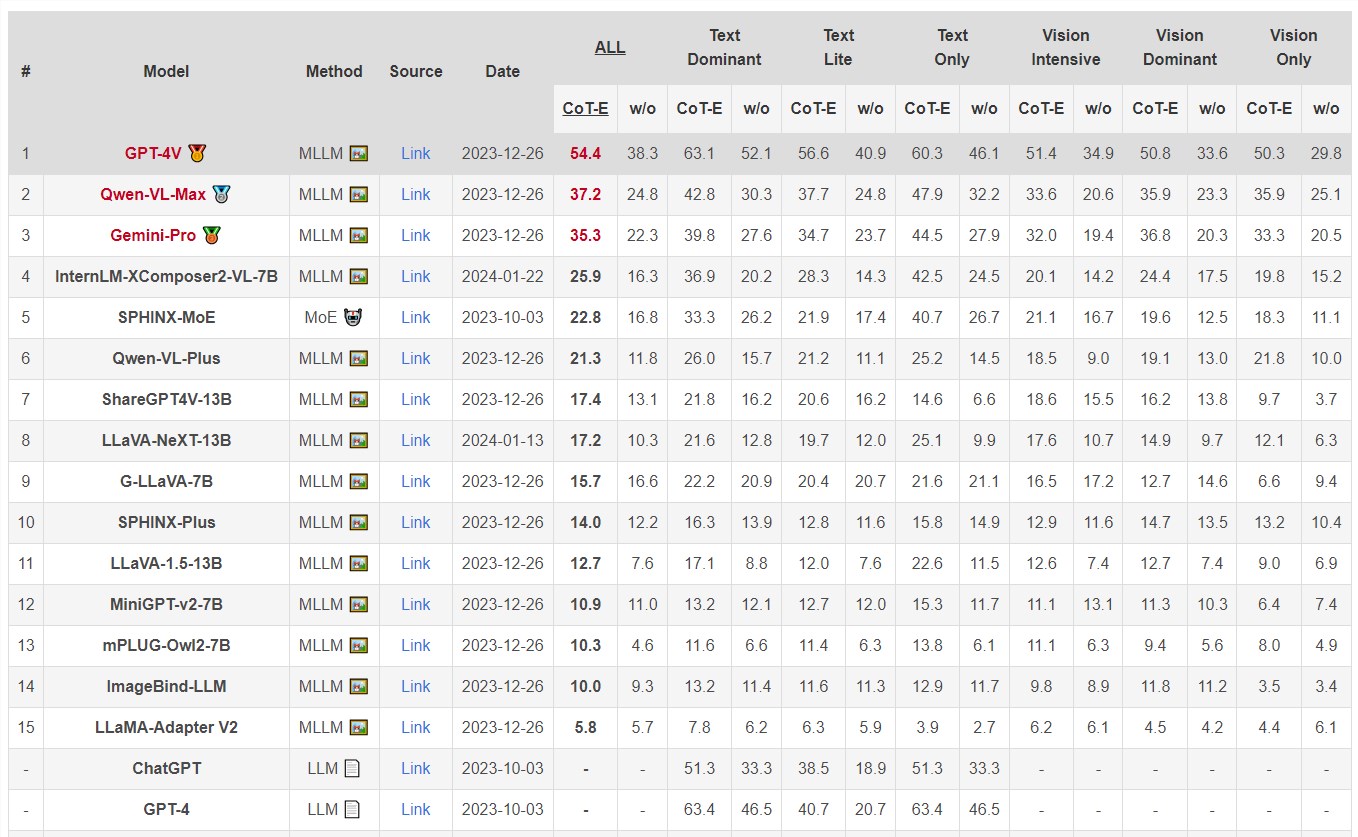
对MATH VERSE的评估突出显示,像Qwen-VL-Max和InternLM-XComposer2这样的模型在没有视觉输入的情况下,性能有所提升(准确性增加超过5%),而GPT-4V在整合视觉信息方面表现更为熟练,在仅有文本的情况下几乎与人类水平相匹配。这种差异强调了MLLMs对文本而非视觉的依赖性,而GPT-4V则因其比较视觉理解而显著。
研究提出了一个名为MATHVERSE的专门基准,以评估MLLMs在视觉数学问题解决能力方面的能力。研究结果显示,大多数现有模型需要视觉输入才能理解数学图表,甚至可能表现更好。这表明需要更先进的数学专用视觉编码器,突显了MLLM发展的潜在未来方向。
产品入口:https://top.aibase.com/tool/mathverse
论文:https://arxiv.org/abs/2403.14624
- 0001
- 0001
- 0000
- 0003
- 0000



