微软NaturalSpeech语音合成推出第三代 生成语音更自然了
要点:
微软 NaturalSpeech 推出第三代语音合成技术,实现了超自然的零样本语音合成。
NaturalSpeech3采用创新的属性分解扩散模型和数据 / 模型扩展,提高了语音合成的质量和自然度。
FACodec 和属性分解扩散模型是 NaturalSpeech3的关键技术,取得了 SOTA 的语音合成效果。
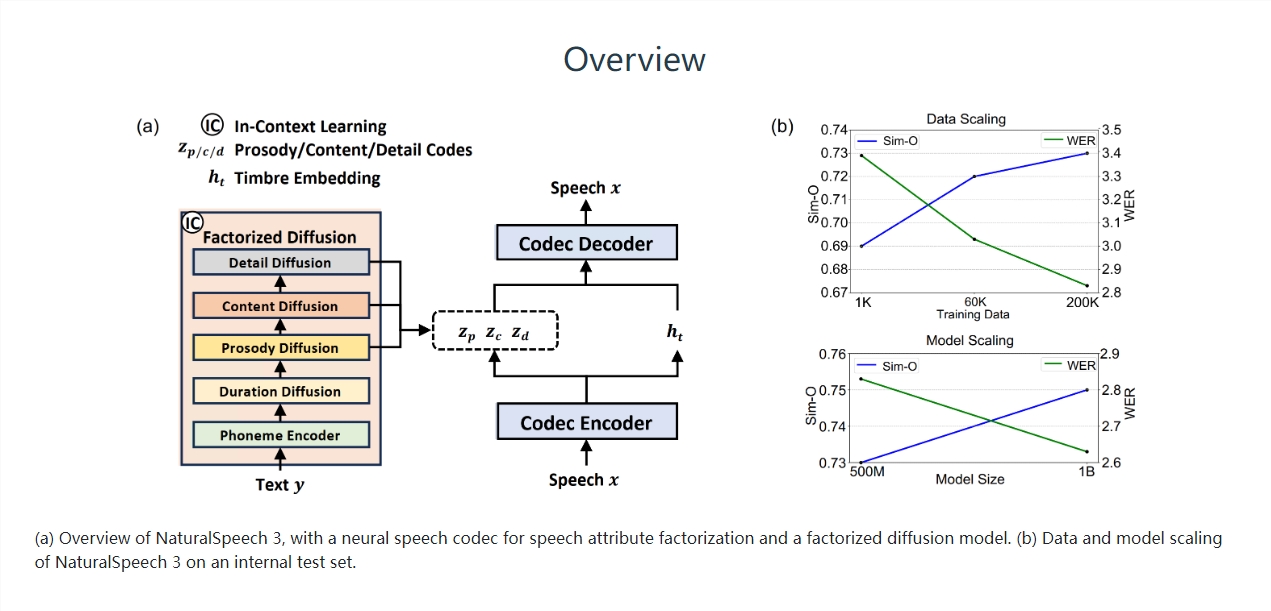
近来,微软 NaturalSpeech 项目推出了第三代语音合成技术,以实现超自然的零样本语音合成。NaturalSpeech3通过属性分解扩散模型和数据 / 模型扩展,提高了语音合成的质量和自然度。其关键技术 FACodec 和属性分解扩散模型取得了 SOTA 的语音合成效果。
NaturalSpeech3的成功在于基于属性分解的 Codec Diffusion 建模范式,以及数据 / 模型扩展。传统 TTS 系统难以支持高质量零样本语音合成,而 NaturalSpeech3通过扩大数据集和模型规模,大幅提升了合成语音的质量和自然度。
论文:https://arxiv.org/abs/2403.03100
Demo 演示: https://speechresearch.github.io/naturalspeech3
FACodec 作为 NaturalSpeech3的核心组件,能够将语音波形转换成不同属性的解耦表示,从而实现高质量语音合成。属性分解扩散模型的设计使得对音素持续时间、韵律、内容和声学细节的建模更加精准,从而提升了语音合成的效果。
NaturalSpeech3在语音质量、相似性、韵律和可懂度方面均超越了现有 TTS 系统。其扩散模型和 FACodec 的应用展示了基于属性分解的语音表征在语音合成领域的巨大潜力,为实现自然且高质量的语音合成提供了新思路。
微软 NaturalSpeech3的技术突破和创新为语音合成领域带来新的可能性,为未来更自然、更高效的语音合成奠定了基础。这一成果将进一步推动语音合成技术的发展,为实现智能语音交互提供更强大的支持。
- 0000
- 0000
- 0000
- 0000
 0000
0000
