谷歌发布 “Vlogger” 视频模型框架:单张图片生成 10 秒视频
站长网2024-03-20 15:23:182阅
划重点:
⭐️ 谷歌发布新视频框架 “Vlogger”,可以通过单张图片和录音生成本人演讲视频。
⭐️ Vlogger 模型基于扩散模型,包含音频到人体动作和文本到图像模型。
⭐️ Vlogger 具备多样性和自然性,可应用于视频编辑和翻译等领域。
谷歌最近发布了一项名为 “Vlogger” 的新视频框架,可以通过仅一张图片和录音即可生成一个本人演讲视频。
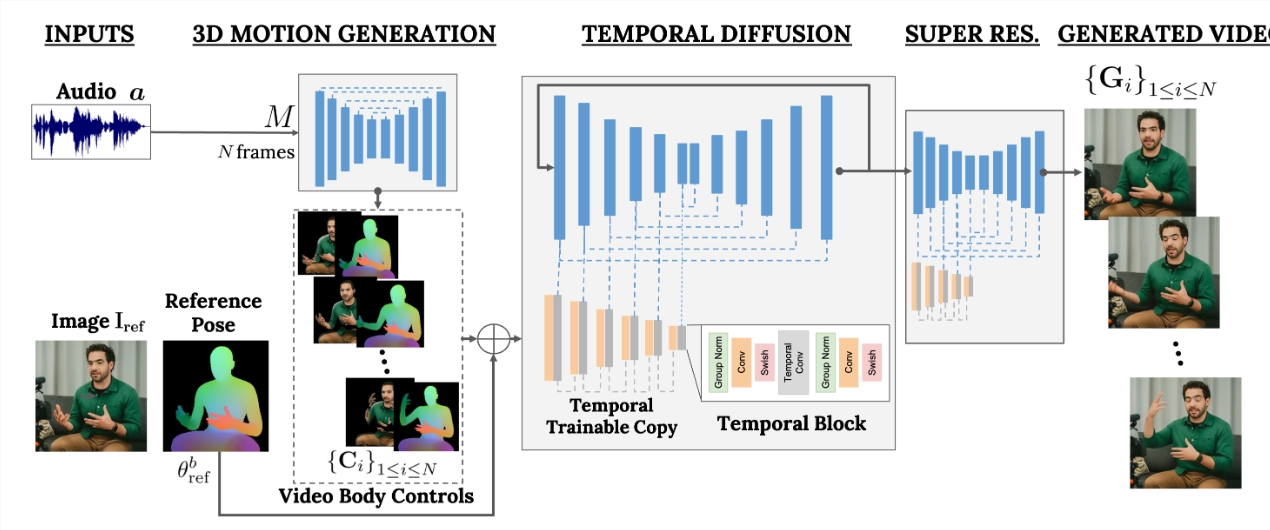
这一框架基于扩散模型,包含音频到人体动作和文本到图像模型两部分。其中,音频波形被用来生成人物的身体控制动作,包括眼神、表情、手势等,使生成的视频看起来自然且生动。该模型训练在一个包含80万个人物视频的大型数据集上完成。
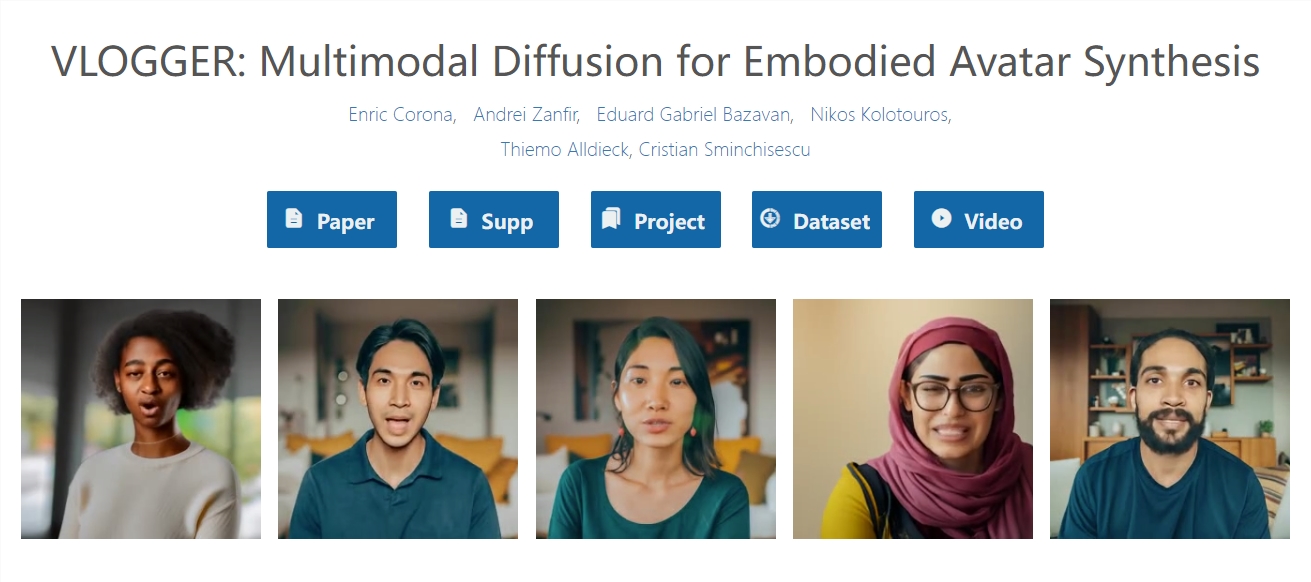
Vlogger 的突出之处在于其多样性和完整性。与其他方法相比,Vlogger 不需要对每个人进行训练,也不依赖于面部检测和裁剪,生成的视频包括面部、唇部和肢体动作等。此外,Vlogger 还具有视频编辑和翻译等应用,能够让人物闭嘴、闭眼,甚至进行视频翻译。
虽然谷歌尚未发布具体模型,但通过展示效果和论文,可以看到 Vlogger 在视频生成领域的潜力和优势。然而,一些网友对其生成视频的画质、口型对不上等问题提出了质疑和吐槽。尽管如此,Vlogger 的发布仍引起了业界的广泛关注和讨论。
谷歌发布的 Vlogger 模型为视频生成领域带来了新的可能性,具备多样性和自然性,为视频编辑和翻译等应用提供了新的解决方案。随着技术的不断进步和完善,相信 Vlogger 将在未来有更广泛的应用和发展。
产品入口:https://top.aibase.com/tool/vlogger
0002
评论列表
共(0)条相关推荐
- 0000
- 0000
- 0000

 0000
0000

 0000
0000
