AI实时绘画系统StreamMultiDiffusion 支持局部涂抹+提示生成图片
近期,一篇名为"StreamMultiDiffusion"的论文提出了一种新颖的实时、交互式的文本到图像生成系统。这种系统能够根据用户提供的手绘区域和相应的语义文本提示来生成图像,为专业图像创作者提供了一个强大的工具,可以用于快速原型设计和创意探索。
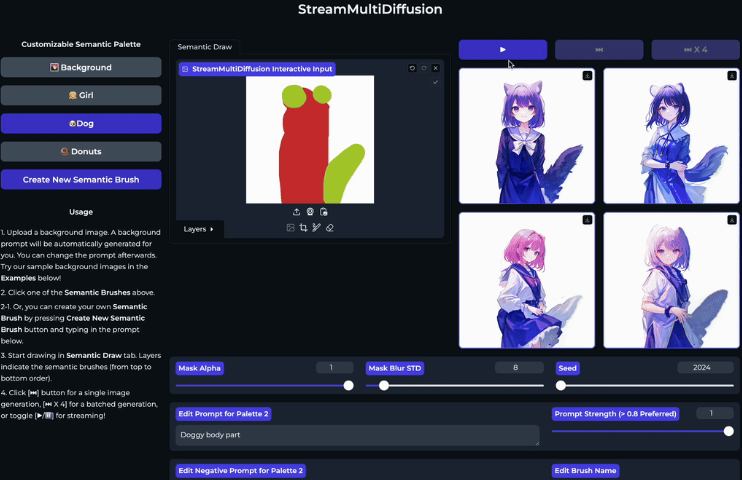
项目地址:https://github.com/ironjr/StreamMultiDiffusion
扩散模型在文本到图像合成领域取得了巨大成功,成为了图像生成和编辑的有前途的候选者。然而,将这些模型用于实际应用仍面临两大挑战:一是需要更快的推理速度,二是需要更智能的模型控制。这两个目标需要同时满足,才能在实际应用中发挥作用。为了解决这些挑战,作者提出了StreamMultiDiffusion框架。
该框架是第一个实时基于区域的文本到图像生成框架。通过稳定快速推理技术并重构模型为新提出的多提示流批处理架构,实现了比现有解决方案更快的全景图生成速度,并在单个RTX2080Ti GPU上实现了基于区域的文本到图像合成的1.57FPS生成速度。
该框架引入了几种关键技术。首先是Latent Pre-Averaging,在推理的每个步骤中,先对中间潜在表示进行平均,以适应快速推理算法。其次是Mask-Centering Bootstrapping,在生成过程的前几步中,将每个遮罩的中心点对齐到图像中心,以确保对象不会被遮罩边缘切断。再次是Quantized Masks,通过量化遮罩来控制提示遮罩的紧密度,从而在不同噪声水平下平滑地融合生成区域。
此外,StreamMultiDiffusion还引入了一个名为Semantic Palette的新概念,这是一种交互式图像生成范式,允许用户通过手绘区域和文本提示实时生成高质量图像。这种方法类似于使用画笔在画布上绘制,但使用的是文本提示和遮罩。例如,用户可以在红色区域生成人物,在耳朵和尾巴区域标记为狗,系统会根据涂抹的区域生成长着狗狗耳朵和尾巴的人物。
论文中的实验结果表明,StreamMultiDiffusion在全景图生成和基于区域的文本到图像合成方面,相比于现有的MultiDiffusion方法,实现了显著的速度提升,同时保持了图像质量。这证明了该系统在实际应用中的巨大潜力和价值。
- 0000
- 0001

 0002
0002- 0000
- 0000


