ICLR 2024 Oral:长视频中噪声关联学习,单卡训练仅需1天
在2024世界经济论坛的一次会谈中,图灵奖得主 Yann LeCun 提出用来处理视频的模型应该学会在抽象的表征空间中进行预测,而不是具体的像素空间 [1]。借助文本信息的多模态视频表征学习可抽取利于视频理解或内容生成的特征,正是促进该过程的关键技术。
然而,当下视频与文本描述间广泛存在的噪声关联现象严重阻碍了视频表征学习。因此本文中,研究者基于最优传输理论,提出鲁棒的长视频学习方案以应对该挑战。该论文被机器学习顶会ICLR2024接收为了 Oral。

论文题目:Multi-granularity Correspondence Learning from Long-term Noisy Videos
论文地址:https://openreview.net/pdf?id=9Cu8MRmhq2
项目地址:https://lin-yijie.github.io/projects/Norton
代码地址:https://github.com/XLearning-SCU/2024-ICLR-Norton
背景与挑战
视频表征学习是多模态研究中最热门的问题之一。大规模视频 - 语言预训练已在多种视频理解任务中取得显著效果,例如视频检索、视觉问答、片段分割与定位等。目前大部分视频 - 语言预训练工作主要面向短视频的片段理解,忽略了长视频中存在的长时关联与依赖。
如下图1所示,长视频学习核心难点是如何去编码视频中的时序动态,目前的方案主要集中于设计定制化的视频网络编码器去捕捉长时依赖 [2],但通常面临很大的资源开销。

图1:长视频数据示例 [2]。该视频中包含了复杂的故事情节和丰富的时序动态。每个句子只能描述一个简短的片段,理解整个视频需要具有长时关联推理能力。
由于长视频通常采用自动语言识别(ASR)得到相应的文本字幕,整个视频所对应的文本段落(Paragraph)可根据 ASR 文本时间戳切分为多个短的文本标题(Caption),同时长视频(Video)可相应切分为多个视频片段(Clip)。对视频片段与标题进行后期融合或对齐的策略相比直接编码整个视频更为高效,是长时时序关联学习的一种优选方案。
然而,视频片段与文本句子间广泛存在噪声关联现象(Noisy correspondence [3-4],NC),即视频内容与文本语料错误地对应 / 关联在一起。如下图2所示,视频与文本间会存在多粒度的噪声关联问题。
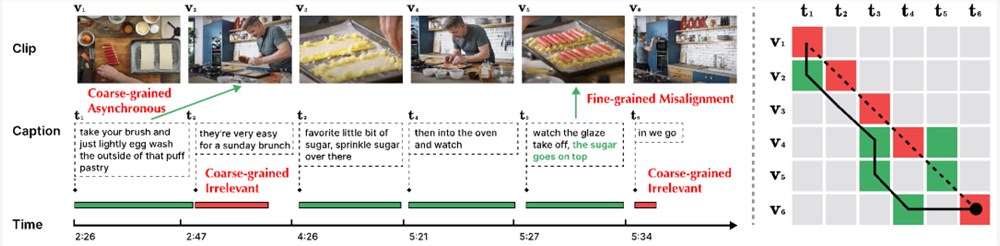
图2:多粒度噪声关联。该示例中视频内容根据文本标题切分为6块。(左图)绿色时间线指示该文本可与视频内容对齐,红色时间线则指示该文本无法与整个视频中的内容对齐。t5中的绿色文本表示与视频内容 v5有关联的部分。(右图)虚线表示原本给定的对齐关系,红色指示原本对齐中错误的对齐关系,绿色则指示真实的对齐关系。实线表示通过 Dynamic Time Wraping 算法进行重新对齐的结果,其也未能很好地处理噪声关联挑战。
粗粒度 NC(Clip-Caption 间)。粗粒度 NC 包括异步(Asynchronous)和不相关(Irrelevant)两类,区别在于该视频片段或标题能否与现有标题或视频片段相对应。其中「异步」指视频片段与标题间存在时序上的错位,例如图2中 t1。由于讲述者在实际执行动作的前后进行解释,导致陈述与行动的顺序不匹配。「不相关」则指无法与视频片段对齐的无意义标题(例如 t2和 t6),或是无关的视频片段。根据牛津 Visual Geometry Group 的相关研究 [5],HowTo100M 数据集中只有约30% 的视频片段与标题在视觉上是可对齐的,而仅有15% 是原本就对齐的;
细粒度 NC(Frame-Word 间)。针对一个视频片段,可能一句文本描述中只有部分文字与其相关。在图2中,标题 t5中「糖撒在上面」与视觉内容 v5强相关,但动作「观察釉面脱落」则与视觉内容并不相关。无关的单词或视频帧可能会阻碍关键信息提取,从而影响片段与标题间的对齐。
方法
本文提出噪声鲁棒的时序最优传输(NOise Robust Temporal Optimal transport, Norton),通过视频 - 段落级对比学习与片段 - 标题级对比学习,以后期融合的方式从多个粒度学习视频表征,显著节省了训练时间开销。

图3视频 - 段落对比算法框架图。
1)视频 - 段落对比。如图3所示,研究者以 fine-to-coarse 的策略进行多粒度关联学习。首先利用帧 - 词间相关性得到片段 - 标题间相关性,并进一步聚集得到视频 - 段落间相关性,最终通过视频级对比学习捕捉长时序关联。针对多粒度噪声关联挑战,具体应对如下:
面向细粒度 NC。研究者采用 log-sum-exp 近似作为 Soft-maximum 算子去识别帧 - 词和词 - 帧对齐中的关键词和关键帧,以细粒度的交互方式实现重要信息抽取,累计得到片段 - 标题相似性。
面向粗粒度异步 NC。研究者采用最优传输距离作为视频片段和标题之间的距离度量。给定视频片段 - 文本标题间相似性矩阵,其中表示片段与标题个数,最优传输目标为最大化整体对齐相似性,可天然处理时序异步或一对多(如 t3与 v4,v5对应)的复杂对齐情况。

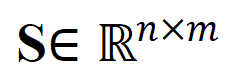

其中

为均匀分布给予每个片段、标题同等权重,
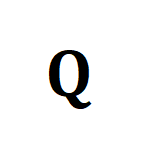
为传输指派或重对齐矩,可通过 Sinkhorn 算法求解。
面向粗粒度不相关 NC。受特征匹配中 SuperGlue [6] 启发,我们设计了自适应的可对齐提示桶去尝试过滤不相关的片段与标题。提示桶是一行一列的相同值向量,拼接于相似性矩阵上,其数值代表是否可对齐的相似度阈值。提示桶可无缝融入最优传输 Sinkhorn 求解中。
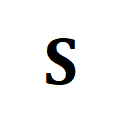
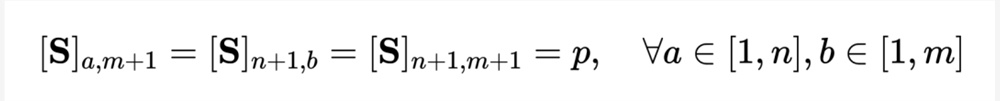
通过最优传输来度量序列距离,而非直接对长视频进行建模,可显著减少计算量。最终视频 - 段落损失函数如下,其中
表示第
个长视频与第

个文本段落间的相似性矩阵。

2)片段 - 标题对比。该损失确保视频 - 段落对比中片段与标题对齐的准确性。由于自监督对比学习会将语义相似的样本错误地作为负样本优化,我们利用最优传输识别并矫正潜在的假阴性样本:

其中

代表训练批次中的所有视频片段和标题个数,单位矩阵

代表对比学习交叉熵损失中的标准对齐目标,
代表融入最优传输矫正目标
后的重对齐目标,

为权重系数。
实验
本文旨在克服噪声关联以提升模型对长视频的理解能力。我们通过视频检索、问答、动作分割等具体任务进行验证,部分实验结果如下。
1)长视频检索
该任务目标为给定文本段落,检索对应的长视频。在 YouCookII 数据集上,依据是否保留文本无关的视频片段,研究者测试了背景保留与背景移除两种场景。他们采用 Caption Average、DTW 与 OTAM 三种相似性度量准则。Caption Average 为文本段落中每个标题匹配一个最优视频片段,最终召回匹配数最多的长视频。DTW 和 OTAM 按时间顺序累计视频与文本段落间距离。结果如下表1、2所示。
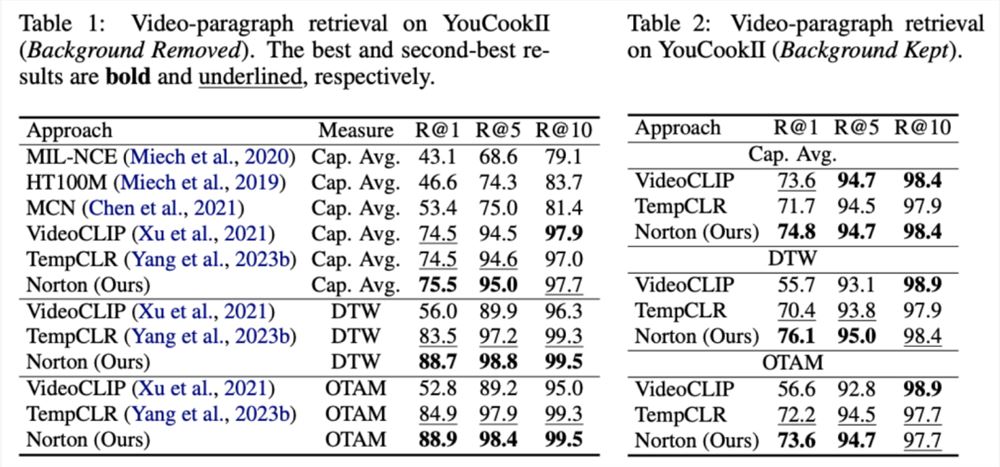
表1、2在 YouCookII 数据集上的长视频检索性能比较
2)噪声关联鲁棒性分析
牛津 Visual Geometry Group 对 HowTo100M 中的视频进行了手工重标注,对每个文本标题重新标注正确的时间戳。产出的 HTM-Align 数据集 [5] 包含80个视频与49K 条文本。在该数据集上进行视频检索主要验证模型是否过度拟合了噪声关联,结果如下表9所示。

表9在 HTM-Align 数据集上针对噪声关联的有效性分析
总结与展望
本文是噪声关联学习 [3][4]—— 数据错配 / 错误关联的深入延续,研究多模态视频 - 文本预训练面临的多粒度噪声关联问题,所提出的长视频学习方法能够以较低资源开销扩展到更广泛的视频数据中。
展望未来,研究者可进一步探讨多种模态间的关联问题,例如视频往往包含视觉、文本及音频信号;可尝试结合外部大语言模型(LLM)或多模态模型(BLIP-2)来清洗和重组织文本语料;以及探索将噪声作为模型训练正激励的可能性,而非仅仅抑制噪声的负面影响。
- 0000
- 0000
- 0000
- 0000
- 0000


