谷歌发布可读屏AI模型ScreenAI:可理解用户界面和信息图表
**划重点:**
1. 🌐 **ScreenAI引领AI界新趋势:** 谷歌研究推出ScreenAI,该AI模型能理解用户界面和信息图表,刷新各项任务的性能指标,包括根据信息图表回答问题、总结内容以及导航用户界面。
2. 🧠 **技术创新:** ScreenAI采用新颖的截图文本表示方法,通过识别UI元素的类型和位置,利用Google LLM PaLM2-S生成合成训练数据,使模型能够回答关于屏幕信息、屏幕导航和总结屏幕内容的问题。
3. 🚀 **未来展望与挑战:** 尽管ScreenAI在改善对数字内容理解方面取得了一定进展,但模型尚不能执行生成的操作。研究人员表示,尽管该专用模型在其类别中表现最佳,但在与更大型模型(如GPT-4和Gemini)的某些任务上仍需进一步研究,以推动其实际应用的发展。
谷歌研究最新发布的ScreenAI标志着语言和语音控制计算机界面的又一重要进展。这一AI模型不仅能理解用户界面和信息图表,而且在回答基于信息图表的问题、总结内容以及导航用户界面等多项任务上,创下了新的性能标杆。
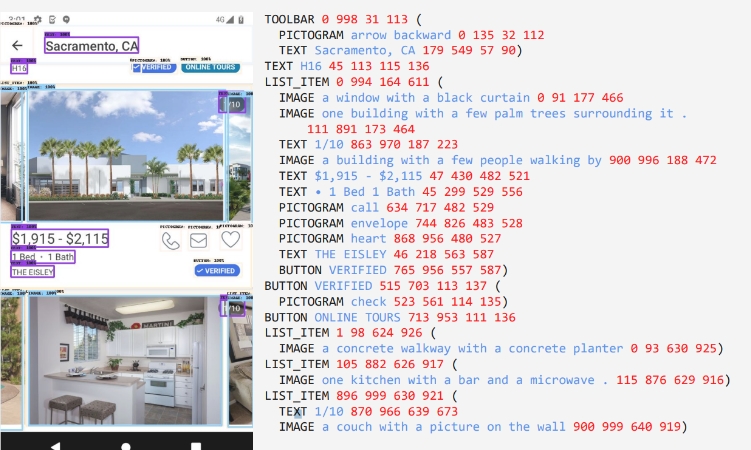
ScreenAI的核心创新在于对截图的文本表示方法。该模型能够识别UI元素的类型和位置,这一方法使用了Google LLM PaLM2-S生成的合成训练数据,使其能够回答关于屏幕信息、屏幕导航和总结屏幕内容的问题。
为实现这一创新,ScreenAI将谷歌先前的技术进展,如PaLI架构和Pix2Struct的灵活修补机制,相结合。后者根据宽高比将图形分割为可变网格。ScreenAI通过图像编码器和多模态编码器处理图像和文本输入,然后使用自回归解码器生成文本输出。
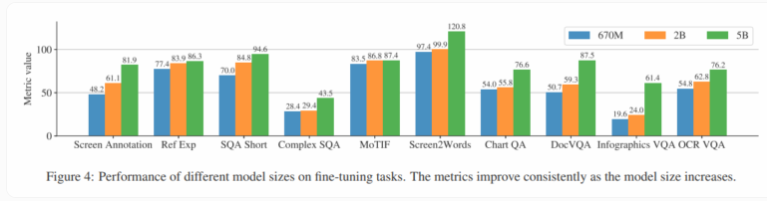
研究人员进行的实验证明,模型性能随着模型大小的增加而提高。这表明通过扩大模型规模,可以进一步提升性能。与类似规模的模型相比,ScreenAI在各项基准测试中表现最佳,通常超过更大型模型。此外,使用光学字符识别(OCR)从截图中提取文本内容对模型性能有轻微积极影响。
然而,尽管ScreenAI在数字内容理解方面取得了一定里程碑,但模型尚不能执行生成的操作。研究人员指出,尽管目前有一些在智能手机上运行的语言模型,但缺乏更强大的多模态模型,这些模型可以结合文本、图像、音频和视频。他们预测,随着像ScreenAI这样的模型的发展,仅使用自然语言对智能手机和用户界面进行自动化处理将在不久的将来变得更加先进。
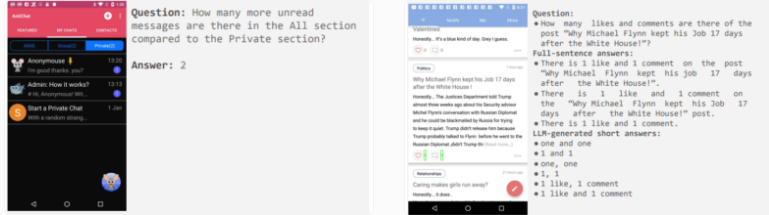
研究人员强调,虽然他们的专用模型在其类别中是最佳的,但在某些任务上仍需要进一步研究,以缩小与更大型模型(如GPT-4和Gemini)的差距。为鼓励更多的发展,谷歌研究计划发布ScreenAI的评估数据集,其中ScreenQA已经提供了包含36,000张截图的86,000个问答对;更复杂的变体和包含截图及其文本描述的集合将会推出。

 0000
0000
 0000
0000- 0000
- 00010
- 0000