斯坦福大学研究人员发布新机器学习方法C3PO:根据上下文定制大型语言模型
划重点:
1. C3PO 是斯坦福大学研究人员推出的一种全新的机器学习方法,用于定制大型语言模型,使其能够根据上下文进行个性化适应。
2. C3PO 方法采用情境化批评(C3PO)策略微调语言模型,以在相关环境中应用反馈,同时避免过度泛化,确保模型在不同环境中表现稳健。
3. 该方法利用直接偏好优化(DPO)和监督微调(SFT)损失来调整模型,保持模型性能并避免不相关提示的负面影响。
斯坦福大学的研究人员最近发布了一种名为C3PO的新方法,旨在解决语言模型定制化面临的挑战。
在人工智能领域不断发展的今天,语言模型的定制化对于确保用户满意度至关重要。然而,传统方法往往需要辨别反馈的适用性,导致模型在意料之外的情境中延伸规则。这一问题凸显了需要先进方法来确保语言模型可以精确地适应用户偏好,而不影响其在各种应用中的实用性。
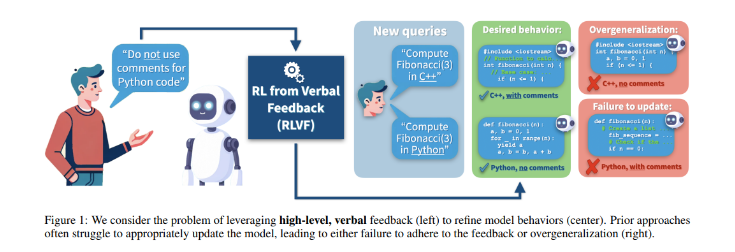
过去的研究已经探索了通过各种类型的反馈(包括学习或启发式奖励、偏好或排名以及自然语言反馈)来改进语言或对话系统。自然语言反馈在代码生成、对话和总结任务中提高了性能。一些研究侧重于利用自然语言反馈来优化通用模型行为,而不是改善单个模型输出。相关研究领域包括宪法人工智能、上下文蒸馏、模型编辑和去偏见大型语言模型。
研究人员引入了一种新颖的方法,即带有约束偏好优化的情境化批评(C3PO),以细化模型的响应行为。C3PO 方法战略性地微调语言模型,以在相关的地方应用反馈,同时小心地避免过度概括。它通过对范围内的数据利用直接偏好优化 (DPO) 以及对范围外和近范围数据的监督微调 (SFT) 损失来实现这一目标,确保模型的性能在各种环境下保持稳健。
数据集 Dnear-scope 和 Dout-of-scope 的生成充满了初始模型的提示和完成,保持了与反馈无关的输入的模型完整性。该方法结合了复杂的组合损失函数 LC3PO,不仅包含相关提示的反馈,而且还积极防止模型的性能因不相关的提示而恶化。C3PO 创建综合两种政策偏好数据进一步增强了这一点,从而能够在 Bradley-Terry 偏好模型框架下学习最优政策。这种最优策略巧妙地平衡了模型的原始能力与新的反馈,惩罚偏离输入的响应,从而精确地改进模型的响应,并与反馈保持一致。
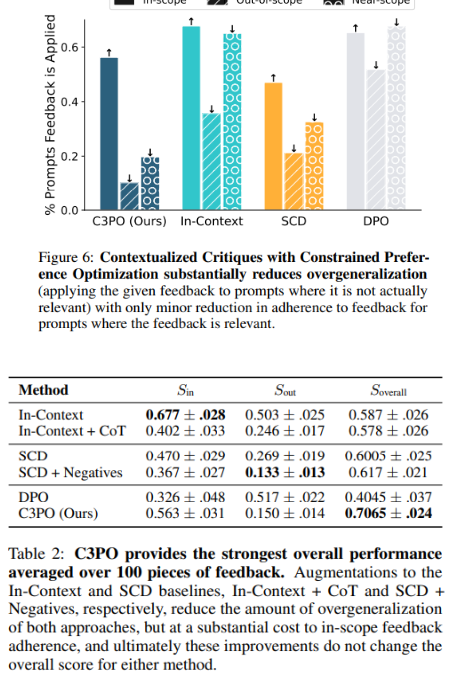
这些实验严格评估了 C3PO 在不过度概括的情况下纳入口头反馈的能力,将其与传统方法进行比较,并探索其吸收多种反馈的能力。利用包含100个条目的反馈数据集(包括编写的和 GPT-4生成的),C3PO 通过有效遵循范围内提示同时最大限度地减少过度概括,展示了卓越的性能,这比修改后的 In-Context 和 SCD 方法有显着改进。混合学习低阶调整 (LoRA) 参数强调了 C3PO 的高效反馈集成,并由优于全面知识蒸馏的战略约束公式支持。
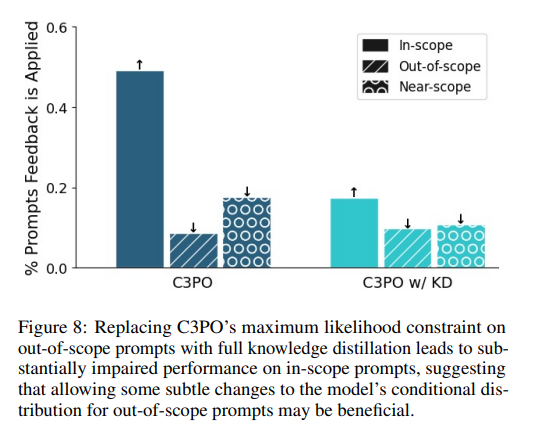
C3PO 的发展标志着朝着更具适应性和以用户为中心的语言模型迈出了一大步。通过解决过度泛化的挑战,这种方法为更加个性化和高效的人工智能工具铺平了道路,这些工具可以在不牺牲更广泛适用性的情况下满足用户的多样化需求。这项研究的意义超出了技术成就的范畴,预示着人工智能可以无缝适应个人偏好、增强其实用性和可访问性的未来。
项目入口:https://top.aibase.com/tool/c3po
论文入口:https://arxiv.org/abs/2402.10893
- 0001
- 0001
- 0001
- 0000
- 0000