谷歌提出最新模型SpatialVLM :赋予视觉语言模型空间推理能力
划重点:
🌐 视觉语言模型 (VLM) 在空间推理方面存在困难,谷歌提出的 SpatialVLM 能够弥补这一不足。
🚀 通过生成大规模的空间 VQA 数据集,研究者训练了 SpatialVLM,展现了显著的定性和定量空间推理能力。
🤖 SpatialVLM 不仅在视觉领域有潜在应用,还能作为密集奖励注释器和执行链式思维推理的强大工具。
谷歌最新论文揭示的 SpatialVLM,是一种具备空间推理能力的视觉语言模型,旨在解决当前视觉语言模型在空间推理方面的困难。视觉语言模型在图像描述、视觉问答等任务上取得显著进展,但在理解目标在三维空间中的位置或空间关系方面仍存在难题。
研究者通过生成大规模的空间视觉问答(VQA)数据集,利用计算机视觉模型提取目标为中心的背景信息,并采用基于模板的方法生成合理的 VQA 数据。经过训练,SpatialVLM表现出令人满意的能力,包括在回答定性和定量空间问题方面的显著提升。
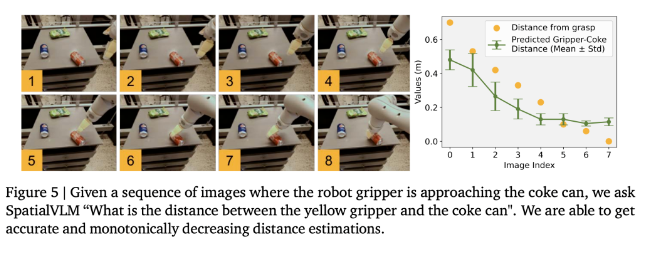
定性空间 VQA 方面,SpatialVLM在人工注释的答案和模型输出自由形式的自然语言中展现了高成功率。在定量空间 VQA 方面,模型在两个指标上表现优越,比基线模型更为出色。
研究者强调了数据的重要性,指出常见数据集的限制是当前视觉语言模型在空间推理上的瓶颈。他们专注于从现实世界数据中提取空间信息,通过生成大规模的空间 VQA 数据集,成功地提高了VLM的一般空间推理能力。
SpatialVLM不仅在视觉领域有应用潜力,还可以作为密集奖励注释器,用于机器人任务的奖励注释。此外,结合大型语言模型,SpatialVLM能够执行链式思维推理,解锁复杂问题的解决能力。
这一研究为视觉语言模型的空间推理能力提供了新的思路,为未来在机器人、图像识别等领域的发展带来了新的可能性。
论文地址:https://arxiv.org/pdf/2401.12168.pdf
项目入口:https://top.aibase.com/tool/spatialvlm
- 0000
 00021
00021- 0000
- 0001
- 0002