BiTA:创新AI方法加速大型语言模型生成
**划重点:**
- 🚀 **加速语言模型推理:** BiTA通过双向调优和简化的SAR草稿验证,实现对自回归语言模型(AR)的无损加速,为公开可访问的基于transformer的LLMs提供插拔式模块,特别适用于聊天机器人等实时应用。
- 🌐 **双向调优与树状解码:** BiTA采用双向调优和树状解码技术,通过在单个前向传递中同时生成和验证多个标记,提高了LLMs的生成效率。。
- 🤖 **通用架构与可插拔设计:** BiTA的通用架构使其成为一个可插拔的方法,可用于加速任何公开可访问的transformer-based LLMs,而不会削弱其卓越的生成能力。
近年来,基于transformer架构的大型语言模型(LLMs)已经崭露头角。Chat-GPT和LLaMA-2等模型展示了LLMs参数的迅速增加,从几十亿到数万亿。尽管LLMs是非常强大的生成器,但由于所有参数的计算负载,它们在推理延迟方面存在问题。因此,人们一直在努力加速LLMs的推理,尤其是在像边缘设备和实时应用(如聊天机器人)等资源受限的情境中。
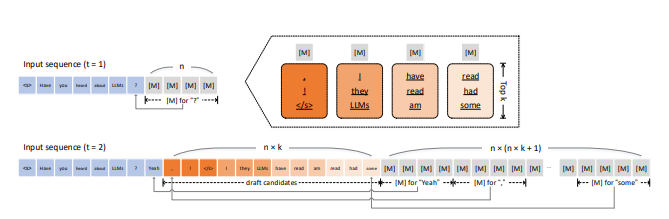
最近的研究表明,大多数仅解码器的LLMs遵循逐标记生成模式。由于标记生成的自回归(AR)性质,每个标记必须经过推理执行,导致许多transformer调用。这些调用针对内存带宽限制运行,常常导致降低计算效率和较长的墙钟周期。
通过在单个模型推理步骤中同时合成多个标记,半自回归(SAR)解码减少了推理执行的高需求。问题在于,大多数LLMs只能生成AR模型,而不能生成SAR模型。由于SAR目标和AR预训练不同步,重新训练SAR模型似乎是一项艰巨的任务。
Intellifusion Inc.和哈尔滨工业大学的研究人员希望通过他们的新加速方法,即双向调优以实现无损SAR解码的Bi-directional Tuning for lossless Acceleration(BiTA),通过学习少量额外的可训练参数,甚至只有0.01%。BiTA的两个主要部分是建议的双向调优和简化的SAR草稿候选验证。为了预测未来的标记,AR模型的双向调优将提示和掩码标记一起纳入考虑,超越了下一个标记。标记序列中的可学习前缀和后缀嵌入是这种方法的一个隐喻。在变换后的AR模型中,通过复杂的基于树的注意机制,生成和验证在单个前向传递中同时进行,无需额外的验证程序或第三方验证模型。建议的方法使用快速调优,可作为插拔模块用于加速任何公开可访问的基于transformer的LLMs,特别是那些经过良好指导的聊天机器人,而不削弱其出色的生成能力。
该模型使用基于树的解码技术在并行中执行高效的创建和验证。BiTA的这两个方面共同作用,加速LLMs的同时保持原始输出不变。在对不同大小的LLMs进行了广泛的生成任务测试后,研究发现其印象深刻的加速效果范围为2.1×至3.3×。此外,当资源受限或需要实时应用时,BiTA的可调提示设计使其成为一种可插即用的方法,可用于加速任何公开可用的LLMs。
论文网址:https://arxiv.org/pdf/2401.12522.pdf
- 0004
- 0000
- 0000
- 0000

 0000
0000