新型稀疏LVLM架构MoE-LLaVA 解决模型稀疏性相关的性能下降问题
要点:
1、MoE-LLaVA是一种新型稀疏LVLM架构,使用路由算法仅激活top-k专家。
2、MoE-LLaVA在各种视觉理解数据集上表现相当甚至超越了LLaVA-1.5-7B。
3、MoE-LLaVA采用三阶段的训练策略,以降低稀疏模型学习的难度。
MoE-LLaVA是一种新型稀疏LVLM架构,通过使用路由算法仅激活top-k专家,解决了通常与多模态学习和模型稀疏性相关的性能下降问题。研究者联合提出了一种新颖的LVLM训练策略,名为MoE-Tuning,以解决大型视觉语言模型(LVLM)的扩大参数规模会增加训练和推理成本的问题。
项目地址:https://github.com/PKU-YuanGroup/MoE-LLaVA
Demo地址:https://huggingface.co/spaces/LanguageBind/MoE-LLaVA
此外,MoE-LLaVA在各种视觉理解数据集上表现相当甚至超越了LLaVA-1.5-7B。该架构采用三阶段的训练策略,以降低稀疏模型学习的难度,从而建立稀疏LVLMs的基准,为未来研究开发更高效和有效的多模态学习系统提供宝贵的见解。
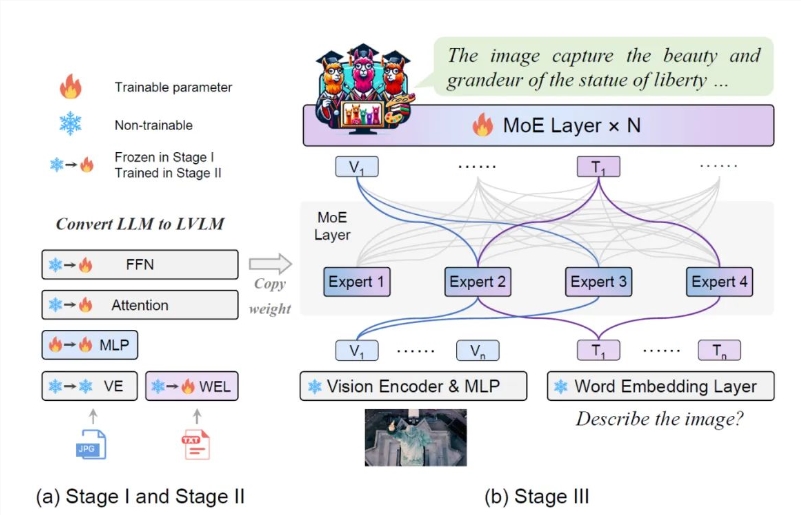
论文提出了MoE-LLaVA的三阶段训练策略。第一阶段的目标是让视觉token适应到LLM,使LLM具备理解图片实体的能力。第二阶段的目标是用多模态的指令数据来微调,以提高大模型的能力和可控性。
第三阶段使用第二阶段的权重作为初始化以降低稀疏模型学习的难度。在模型构建中,MoE-LLaVA是第一个基于LVLM搭载soft router的稀疏模型。研究团队在5个图片问答benchmark上验证了MoE-LLaVA的性能,并报告了激活的参数量和图片分辨率。
为了验证MoE-LLaVA的多模态理解能力,研究在4个benchmark toolkit上评估了模型性能。结果显示,MoE-LLaVA可以用更少的激活参数达到和稠密模型相当甚至超过的性能。研究还采用POPE评估pipeline验证MoE-LLaVA的物体幻觉,结果表明MoE-LLaVA展现出最佳的性能,以较少的激活参数超过了LLaVA。
MoE-LLaVA能够帮助我们更好地理解稀疏模型在多模态学习上的行为,为未来研究和开发提供了有价值的见解。
- 0000
- 0000
- 0001
- 0001
- 0000