200GB!AutoMathText:专注数学文本的超大规模数据集
划重点:
1. 📌AutoMathText是一个200GB的数学文本数据集,包含来自不同来源的科学论文、编程代码片段和网页数据,适用于数学推理、推理训练和微调等多种应用场景。
2. 📌支持文本生成和问答任务,特别适用于开发和测试理解和生成数学相关内容的模型。
3. 📌数据集包含10亿到100亿的数据量级,提供丰富的资源供大规模模型训练。
AutoMathText是一个庞大的数学文本数据集,总体规模达到200GB,汇聚了来自多个来源的数据,包括科学论文、编程代码片段以及网页数据。该数据集经过特定的过滤和处理,旨在服务于数学推理、推理训练和微调等多种应用场景。
AutoMathText专注于文本生成和问答任务,为开发和测试涉及数学推理和推理能力的模型提供了理想的训练资源。模型可以通过这个数据集进行学习,提高对数学相关内容的理解和生成能力。数据集目前仅支持英语,适用于需要大量英文训练数据的场景。这有助于研究人员和开发者在英语环境中训练和评估模型。
AutoMathText的数据量级在10亿到100亿之间,为大规模模型训练提供了丰富的资源。这对于开发大型、高性能的数学模型具有重要意义。
数据集包含了不同来源和不同过滤条件下的数据子集,包括来自arXiv的科学论文、编程代码片段以及网页数据。这些子集的多样性使其适用于多种不同的训练和测试需求。AutoMathText提供了详细的领域标签,涵盖数学推理、推理、微调等方面。这有助于用户精确挑选符合特定任务需求的数据,提高模型的训练效果。
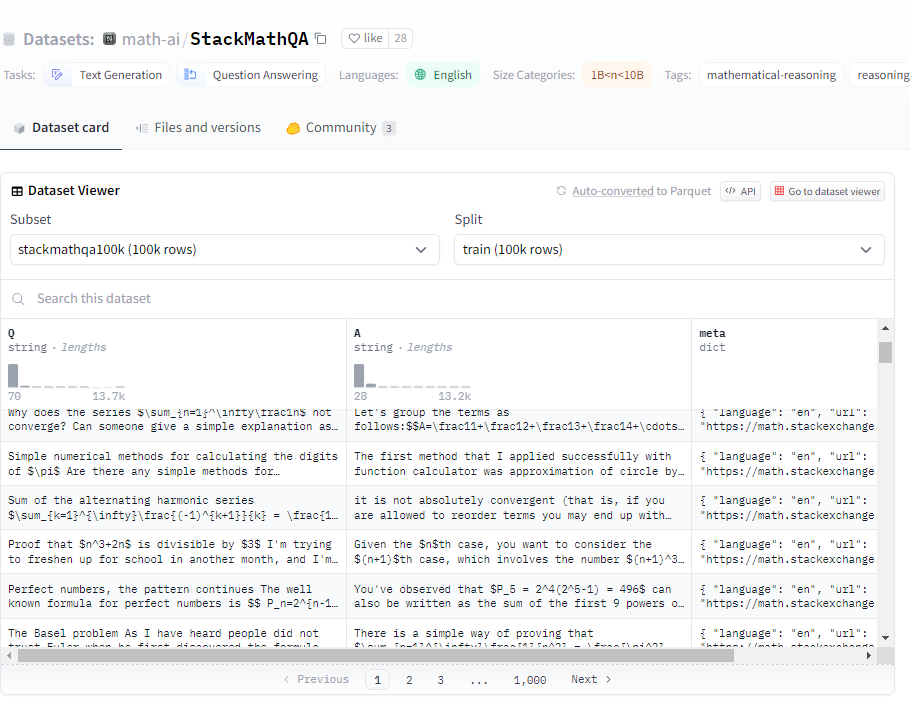
此外,AutoMathText的姊妹数据集StackMathQA汇集了200万个数学问题和答案,为AI提供了一个庞大的习题集,有助于训练模型更好地理解和解决数学问题。 StackMathQA的集合是由数学问题和对应答案组成,提供了更具挑战性的数学任务,为模型的进一步发展提供了支持。
数据集入口:https://huggingface.co/datasets/math-ai/StackMathQA
- 0000


 0000
0000- 0000
- 0000
- 0002



