百度推多模态模型UNIMO-G 支持还原图片ID
站长网2024-01-26 11:00:070阅
核心要点:
百度提出了UNIMO-G统一图像生成框架,通过多模态条件扩散实现文本到图像生成,克服了文本描述简洁性对生成复杂细节图像的挑战。
UNIMO-G包含多模态大语言模型(MLLM)和基于编码的多模态输入生成图像的条件去噪扩散网络两个核心组件,通过两阶段训练策略达到统一的图像生成能力。
UNIMO-G在文本到图像生成和零样本主题驱动合成方面表现出色,特别有效地处理包含多个图像实体的复杂多模态提示。
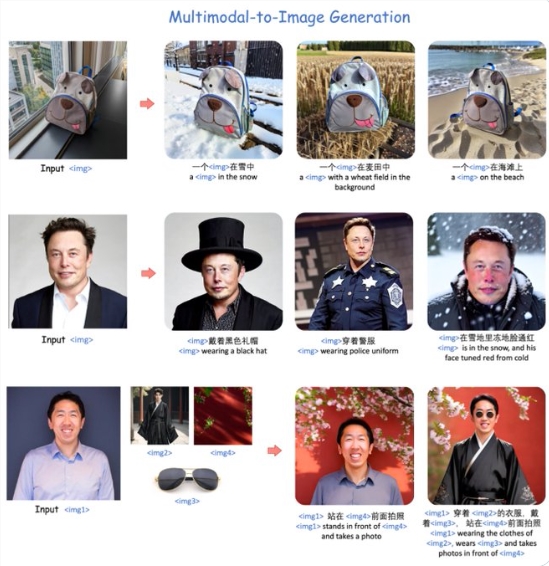
在最新的研究中,百度提出了一项名为UNIMO-G的统一图像生成框架,旨在克服现有文本到图像扩散模型面临的挑战。传统模型主要根据简洁的文本提示生成图像,但文本描述的简洁性限制了生成复杂细节图像的能力。
UNIMO-G采用了简单而强大的多模态条件扩散框架,能够处理交错的文本和视觉输入,展示了文本驱动和主题驱动图像生成的统一能力。
项目地址:https://top.aibase.com/tool/unimo-g
UNIMO-G的核心组件包括多模态大语言模型(MLLM)和基于编码的多模态输入生成图像的条件去噪扩散网络。独特的两阶段训练策略使得该框架能够在大规模文本图像对上进行预训练,开发出条件图像生成能力,并通过多模态提示进行指令调整,实现统一的图像生成能力。
这一框架还采用了精心设计的数据处理管道,涉及语言基础和图像分割,用以构建多模态提示。在测试中,UNIMO-G在文本到图像生成和零样本主题驱动合成方面表现卓越,特别是在处理包含多个图像实体的复杂多模态提示时,生成高保真图像的效果显著。
总体而言,UNIMO-G的提出为文本到图像生成领域带来了新的可能性,其简单而有效的多模态条件扩散框架在处理复杂性和提高图像生成质量方面具有潜在的广泛应用价值。
0000
评论列表
共(0)条相关推荐

 0000
0000
 0001
0001- 0000
- 0001
- 0000

