小红书提出创新框架:充分利用负样本提升大语言模型推理能力
要点:
小红书搜索算法团队在AAAI2024上提出了一种创新框架,利用负样本知识来提升大语言模型(LLMs)的推理能力。
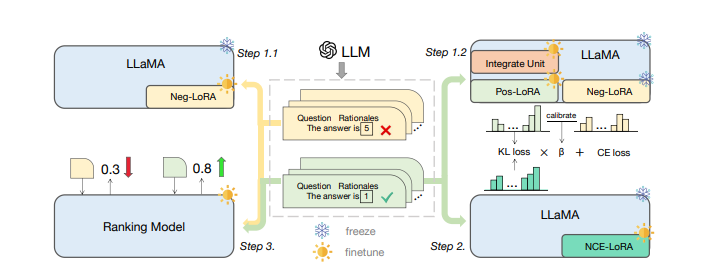
他们设计了一个模型专业化框架,包括负向协助训练(NAT)、负向校准增强(NCE)和动态自洽性(ASC)等序列化步骤,全面利用负样本在知识蒸馏中的关键作用。
该框架通过在训练和推理过程中充分利用负样本,使得小模型能够更好地处理复杂的数学推理问题,避免大模型的黑盒属性和庞大参数量的限制。
在AAAI2024上,小红书搜索算法团队推出了一项创新框架,旨在解决大语言模型(LLMs)在推理任务中的黑盒属性和庞大参数量带来的问题。传统研究方法主要关注正样本,而这项工作强调了负样本在知识蒸馏中的价值。通过负向协助训练(NAT)、负向校准增强(NCE)和动态自洽性(ASC)等序列化步骤,他们构建了一个全方位利用负样本的模型专业化框架。
论文地址:https://arxiv.org/pdf/2312.12832.pdf
首先,他们提出了负向协助训练(NAT)方法,通过设计dual-LoRA结构,从正向和负向两方面获取知识。这一步骤在训练中动态地集成正、负LoRA模块的知识,以构建更全面的推理能力。其次,他们设计了负向校准增强(NCE),利用负知识来帮助自我增强过程,通过KL散度来度量正、负推理链路之间的不一致性,以选择性地学习和增强嵌入的知识。
除了训练阶段,他们还在推理过程中利用负向信息,提出了动态自洽性(ASC)方法,通过排序模型在正、负样本上进行训练,为正确答案的推理链路分配更高的权重。整体来说,这一框架通过充分挖掘负样本的宝贵信息,使得小模型能够更有效地进行复杂的算术推理,从而在实际应用中更广泛地部署大语言模型的推理能力。
这一研究为提高大语言模型应用性能提供了新思路,通过引入负样本的知识,弥补了传统研究方法的不足,为推理任务的应用提供了更可靠和高效的解决方案。
- 0002
- 0000
- 0000
- 0000
- 0000