RPG-DiffusionMaster:利用LLM优化SD文生图过程
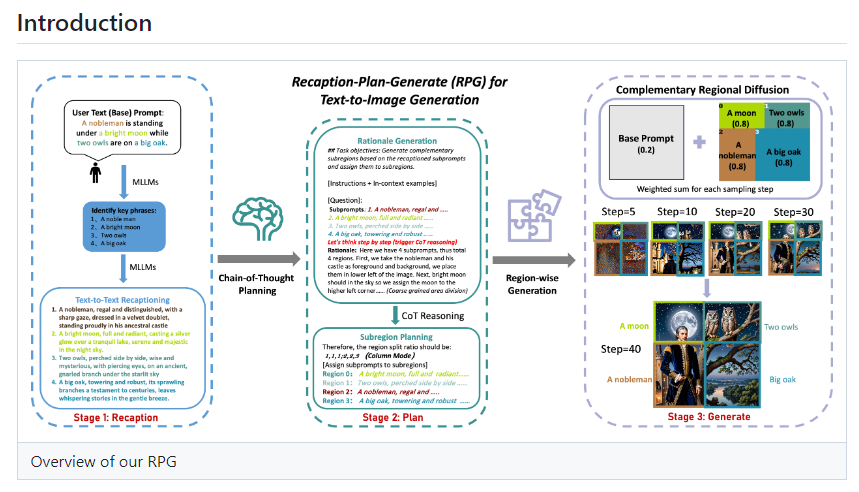
RPG-DiffusionMaster是一个利用LLM(Large Language Model)优化SD(Text-to-Image)文本到图像的转换过程的框架。该框架能够更好地理解和分解生成图像的文字提示,以实现将一幅图像分解成不同的部分或区域,并根据理解的相应文本提示来生成图像,最后合成为一个符合预期要求的图像。
项目地址:https://top.aibase.com/tool/rpg-diffusionmaster
RPG框架的主要功能包括多模态重标记、思维链规划、补充区域扩散、高分辨率图像生成、多样化应用以及对不同类型的大语言模型的兼容性。
在多模态重标记方面,RPG框架能够将简单的文本提示转换为更具描述性和详细性的提示,以提高生成图像的质量和与文本的语义对齐程度。同时,它还能将复杂的图像生成任务分解为多个简单的子任务,并在图像空间中划分为互补的子区域,每个子区域对应一个特定的子任务。
在生成图像内容时,RPG框架在非重叠的子区域中独立生成图像内容,然后将这些内容合并,创建一幅完整的复合图像。此外,RPG-DiffusionMaster还能够生成超高分辨率的图像,并支持多种扩散模型,包括SDXL和SD v1.4/1.5等,兼容不同的MLLM架构,从而具有更高的灵活性和准确性。
RPG-DiffusionMaster不仅支持专有的大语言模型,如GPT-4、Gemini PRO等,还支持开源模型,如miniGPT-4,提供了更广泛的应用可能性。由于使用先进的大型语言模型,该框架可以直接应用于文本到图像的转换任务,无需进行额外的模型训练。
举例解释,当提示词为:“我想要一幅画,画里有一只大象在草地上玩足球”,RPG框架通过多模态重标记将描述变得更加详细和具体,然后利用思维链规划将图像分解为多个部分,并最终通过补充区域扩散将这些单独绘制的部分合并成一幅完整的画。
实验结果表明,RPG框架能够根据复杂的文本描述生成高度准确和详细的图像,优于现有技术,并具有灵活性和广泛的适用性,能够应用于多种不同的图像生成场景。
- 0000

 0000
0000- 0000
- 0000
 0000
0000

